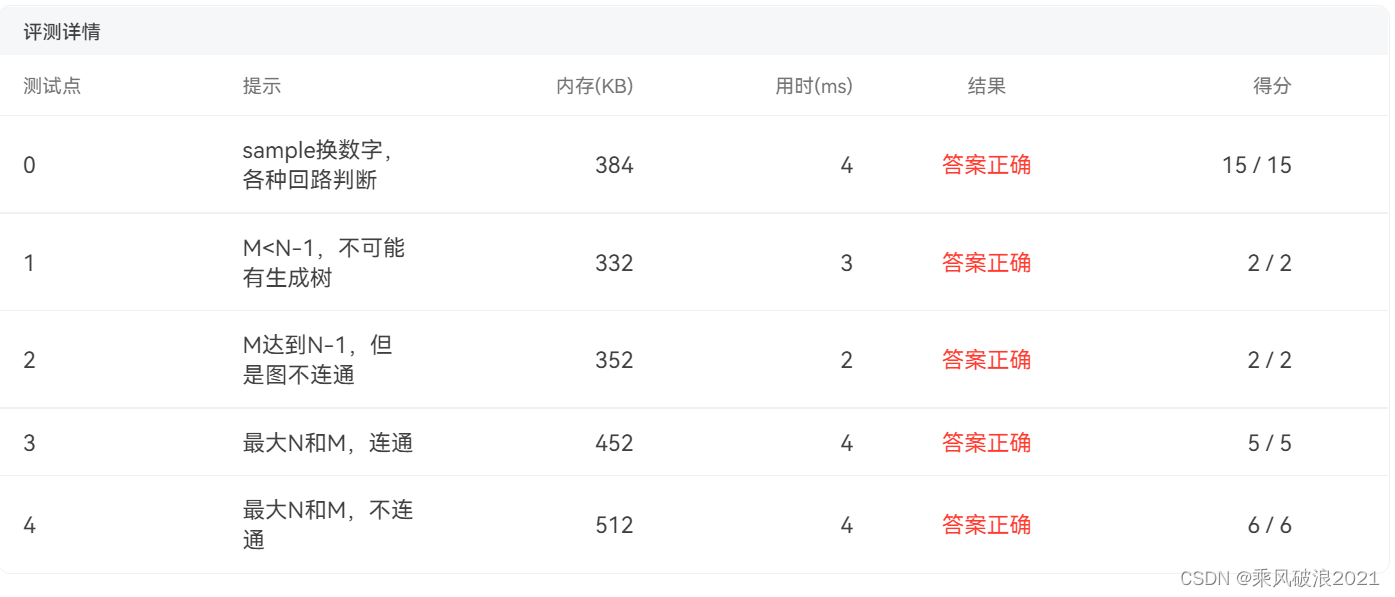
论文地址:https://arxiv.org/abs/2211.11962
论文代码:https://github.com/hailanyi/TED
论文背景
三维场景中的物体分布有不同的方向。普通探测器不明确地模拟旋转和反射变换的变化。需要大的网络和广泛的数据增强来进行鲁棒检测。
equivariant networks 通过在多个变换点云上应用共享网络显式地模拟变换变化,显示出在物体几何建模方面的巨大潜力。这种网络计算量大,推理速度慢,难以应用于自动驾驶中的 3D 目标检测。
希望 3D detector 的预测与旋转和反射等变换是一致的。换句话说,当一个目标在输入点中改变它的方向时,该目标被检测到的 box 应该具有相同的形状,但相应地改变它的方向。
然而,大多数基于体素和点的方法都没有对这种变换等价方差进行显式建模,在处理变换后的点云时会产生不可靠的检测结果。
论文提出了 an efficient Transformation-Equivariant 3D Detector(TED)
论文相关
3D物体检测
先前的方法将点云转换成2D多视图图像以执行3D目标检测。最近大量的方法采用体素或基于点的检测框架。
通过使用基于体素的稀疏卷积,SECOND、PointPillars、SA-SSD 和 SE-SSD 执行单阶段3D对象检测,而体素-RCNN 和SFD 执行两阶段检测。
通过使用基于点的集合抽象,3DSSD、SASA 和 IA-SSD 执行单阶段检测,而PointRCNN 和 STD 进行两阶段检测。
PVRCNN 和 CT3D 使用基于体素和基于点的操作两者来生成和细化目标 proposal。
一些最近的方法生成伪点云或来自RGB图像的虚拟点,用于基于体素的多模态3D目标检测。
论文扩展了流水线与变换等变性设计,拥有更高的检测精度。
变换等变性建模
目前,已经提出了各种各样的变换(平移、旋转和反射)等变网络。一些基于点的SO(3)和基于体素的SE(3)等变网络被设计用于处理3D数据。一些等变网络被设计用于目标检测和姿态估计。最相近的是专为室内场景设计的EON;但是,它没有考虑效率。
论文的TED主要是为户外场景中的实时目标检测而设计的。
变换等变性和不变性
给定运算f:
X
→
Y
X → Y
X→Y 和变换群
G
G
G,等方差定义为:
f
[
T
g
X
(
x
)
]
=
T
g
Y
[
f
(
x
)
]
,
∀
x
∈
X
,
∀
g
∈
G
,
(1)
\tag1 f[T_g^X(x)]=T_g^Y[f(x)],\forall x\in X,\forall g \in G,
f[TgX(x)]=TgY[f(x)],∀x∈X,∀g∈G,(1)其中
T
g
X
T^X_g
TgX 和
T
g
Y
T^Y_g
TgY 分别指
X
X
X 和
Y
Y
Y 空间中的变换操作。当
T
g
Y
T^Y_g
TgY 是单位矩阵时,等方差变为不变性。
论文研究了自动驾驶场景中的3D目标检测,其中变换主要发生在道路平面上。
不失一般性,考虑 2D BEV平面上的变换。形式上,认为变换群
G
G
G 是二维平移群
(
R
2
,
+
)
(\R^2,+)
(R2,+) 和二维旋转反射群
K
K
K 的半直积
G
=
(
R
2
,
+
)
⋊
K
G =(R2,+)\rtimes K
G=(R2,+)⋊K。旋转反射群
K
K
K 由反射群
(
{
±
1
}
,
∗
)
(\{±1\},*)
({±1},∗) 和离散旋转群
O
N
O_N
ON 组成。在反射的情况下,群
K
K
K 包含角度分辨率
β
β
β 的角度倍数的
N
N
N 个离散旋转;因此,
K
K
K 是
2
N
2N
2N 阶的离散子群。对于输入点云
P
P
P,论文试图找到具有参数
θ
θ
θ 的检测器
D
θ
(
⋅
)
D^θ(·)
Dθ(⋅) 来检测 bounding box
B
B
B,满足变换等方差:
D
θ
(
T
g
(
P
)
)
=
T
g
[
D
θ
(
P
)
]
(2)
\tag2D^θ(T_g(P))=T_g[D^\theta(P)]
Dθ(Tg(P))=Tg[Dθ(P)](2) 其中,
T
g
T_g
Tg 是
G
G
G 的变换操作。
用于3D检测的对象增强
基于“copy-andpaste”的增强(GT-aug)在最近的 3D 目标检测中被广泛使用。LiDAR-Aug 解决了GT-aug中的闭塞问题。通过交换目标的一部分,PA-Aug 和 SE-SSD 创建用于数据增强的不同目标。
与之不同的是,论文通过从附近密集的对象中创建稀疏的训练样本来增强远处对象的检测。
3D 目标检测
给定输入点云
P
=
{
p
i
}
i
P = \{p_i\}_i
P={pi}i,3D对象检测旨在找到由 3D BBs(Bounding boxs)
B
=
{
b
i
}
i
B = \{b_i\}_i
B={bi}i表示的所有对象。每个框
b
i
b_i
bi 由坐标编码,尺寸和方向。
论文中,从最先进的 Voxel-RCNN 提出了单模态 TED-S 和 多模态 TED-M 3D目标检测器。TED-S和TED-M之间的区别在于,TED-S 仅取 LiDAR 点,而 TED-M 取 LiDAR 点和由深度估计算法生成的 RGB 图像伪点两者。遵循基于区域的检测框架。它包括一个稀疏卷积主干,一个2D区域提议网络(RPN)和一个建议细化分支。
论文内容
论文提出了 TED,它既是变换等价的,又是有效的。
通过一个简单而有效的设计来实现:让 TeSpconv 堆叠多通道变换-等变体素特征,而 TeBEV 池和 Tivoxel 池化将等变特征对齐并聚合到轻量级的 scene-Level 和实例级表示中,以实现高效有效的 3D 目标检测。

等差变换体素 Backbone
为了有效地将原始点编码为等差变换特征,首先设计了等差变换稀疏卷积(TeSpConv)Backbone。 TeSpConv 由广泛使用的稀疏卷积(SpConv)构造。 与CNNs类似,SpConv 是等差变换的。 然而,SpConv 与旋转和反射并不时等变换的。 因此,通过添加转换通道将 SpConv 扩展到旋转和反射等变:1)转换通道之间权重高度共享;2)输入点的变换拥有不同旋转角度和反射。
形式上,基于
2
N
2N
2N 个变换动作
{
T
i
}
i
=
1
2
N
⊂
K
\{T_i\}_{i=1}^{2N} \sub K
{Ti}i=12N⊂K,将点云
P
P
P 变换为
2
N
2N
2N 个不同点集
{
P
T
i
}
i
=
1
2
N
\{P^{T_i}\}_{i=1}^{2N}
{PTi}i=12N。 然后将所有点集划分为体素集
{
P
^
T
i
}
i
=
1
2
N
\{\hat P^{T_i}\}_{i=1}^{2N}
{P^Ti}i=12N。在每个体素中,原始特征被计算为所有内部点的 point-wise 特征的平均值。 利用共享 SpConv
φ
(
⋅
)
φ(·)
φ(⋅) 将体素
{
P
^
T
i
}
i
=
1
2
N
\{\hat P^{T_i}\}_{i=1}^{2N}
{P^Ti}i=12N 编码为等差变换体素
{
V
T
i
}
i
=
1
2
N
\{V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N:
V
T
i
=
φ
(
P
^
T
i
)
,
i
=
1
,
2
,
.
.
.
,
2
N
.
(3)
\tag 3 V^{T_i} = \varphi (\hat P^{T_i}),i=1,2,...,2N.
VTi=φ(P^Ti),i=1,2,...,2N.(3)对于多模态设置,论文使用相同的网络结构对伪点特征进行编码。与常规稀疏卷积编码的体素特征相比,在不同的旋转和反射变换下,特征
{
V
T
i
}
i
=
1
2
N
\{V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N 包含了不同的特征。
等差变换 BEV Pooling
体素特征
{
V
T
i
}
i
=
1
2
N
\{V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N 包含大量的变换通道;因此,直接将它们输入RPN将引入大量额外的计算,并需要更大的GPU内存。为了解决这个问题,论文提出了 TeBEV Pooling,通过双线性插值和 max-pooling 将 scene-level 体素特征对齐和聚集成一个紧凑的 BEV map。

首先将体素特征
{
V
T
i
}
i
=
1
2
N
\{V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N沿高度维压缩为BEV特征
{
E
T
i
}
i
=
1
2
N
\{E^{T_i}\}_{i=1}^{2N}
{ETi}i=12N。由于 BEV 特征是在不同的变换下得到的,因此有必要将它们对齐到同一个坐标系中。 首先在
E
T
1
E^{T_1}
ET1 坐标系中生成一组 scene-level 网格点
X
T
1
X^{T_1}
XT1。根据变换动作
{
T
i
}
i
=
1
2
N
\{T_i\}_{i=1}^{2N}
{Ti}i=12N,将网格点转换到 BEV 坐标系中,生成一组新的网格点
{
X
T
i
}
i
=
1
2
N
\{X^{T_i}\}_{i=1}^{2N}
{XTi}i=12N。然后,在 BEV map 上应用一系列双线性插值
I
(
⋅
,
⋅
)
\mathcal I(·, ·)
I(⋅,⋅),得到一组对齐特征
{
A
T
i
}
i
=
1
2
N
\{A^{T_i}\}_{i=1}^{2N}
{ATi}i=12N :
A
T
i
=
I
(
X
T
i
,
E
T
i
)
,
i
=
1
,
2
,
.
.
.
,
2
N
.
(4)
\tag4 A^{T_i} = \mathcal I(X^{T_i}, E^{T_i}),i=1,2,...,2N.
ATi=I(XTi,ETi),i=1,2,...,2N.(4)如果
E
T
1
E^{T_1}
ET1 中的边界像素在
E
T
2
,
.
.
.
,
E
T
N
E^{T_2},...,E^{T_N}
ET2,...,ETN 中没有对应的像素,则内插结果将被填充零。
为了提高效率,在
2
N
2N
2N 个对齐特征映射上应用最大池
M
(
⋅
)
\mathcal M(·)
M(⋅) 来得到一个紧致表示
A
∗
A^*
A∗:
A
∗
=
M
(
A
T
1
,
A
T
2
,
.
.
.
,
A
T
2
N
)
.
(5)
\tag5 A^* = \mathcal M(A^{T_1},A^{T_2},...,A^{T_{2N}}).
A∗=M(AT1,AT2,...,AT2N).(5)轻量级特征
A
∗
A^*
A∗ 被放入RPN 中,以有效地生成一组目标 proposals
B
∗
B^*
B∗.
变换不变体素 Pooling
近年来,许多检测器都采用了兴趣区域(Region of Interest, RoI)池化操作,从 scene-level 变换等变 backbone 特征中提取 instance-level 变换不变特征,用于 proposal refinement。然而,直接应用这样的池化操作从 backbone 中提取特征是不可行的:
1.坐标系
T
1
T_1
T1 中的 proposal
B
∗
B^*
B∗ 与不同
T
i
T_i
Ti变换的体素特征
{
V
T
i
}
i
=
1
2
N
\{V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N不对齐。
2.TeSpConv中的体素特征包含多个变换通道,将提取的特征直接送入检测头需要大量的额外计算和GPU内存。
因此,论文提出了 TiVoxel pooling,它通过多网格池和跨网格关注将实例级体素特征对齐并聚合成一个紧凑的特征向量。
多网格 pooling
Proposal
B
∗
B^*
B∗ 是在
T
1
T_1
T1 坐标系中获得的,而 backbone 特征是在不同的变换下获得的。因此,在池化之前需要进行 proposal 对齐。
首先在坐标系
T
1
T_1
T1 中使用 proposal
B
∗
B^*
B∗ 生成一组局部网格点,然后根据变换动作
T
2
,
.
.
.
,
T
2
N
{T_2,...,T_{2N}}
T2,...,T2N 将网格点变换 到
{
A
T
i
}
i
=
1
2
N
\{A^{T_i}\}_{i=1}^{2N}
{ATi}i=12N 中的每个通道的坐标系中,最后由变换后的
2
N
2N
2N 组网格点提取变换不变的局部特征。
对于 proposal
B
∗
B^*
B∗ 基于变换动作
{
T
i
}
i
=
1
2
N
\{{T_i}\}_{i=1}^{2N}
{Ti}i=12N,首先生成
2
N
2N
2N 个 instance-level 网格点集合
{
X
T
i
}
i
=
1
2
N
\{{ \boldsymbol X^{T_i}}\}_{i=1}^{2N}
{XTi}i=12N,
X
T
i
=
{
X
j
T
i
}
j
=
1
J
⊂
R
3
{ \boldsymbol X^{T_i}} = \{ X_j^{T_i} \}_{j=1}^{J} \sub \R^3
XTi={XjTi}j=1J⊂R3。
J
J
J 表示在每个集合中的网格点数量。通过使用
2
N
2N
2N 各网格点集,论文从
{
V
T
i
}
i
=
1
2
N
\{ V^{T_i}\}_{i=1}^{2N}
{VTi}i=12N 提取多个 instance-level 特征
{
F
T
i
}
i
=
1
2
N
\{\boldsymbol F^{T_i}\}_{i=1}^{2N}
{FTi}i=12N:
F
T
i
=
V
S
A
(
X
T
i
,
V
T
i
)
,
i
=
1
,
2
,
.
.
.
,
2
N
,
(6)
\tag6 \boldsymbol F^{T_i} = VSA(\boldsymbol X^{T_i},V^{T_i}),i=1,2,...,2N,
FTi=VSA(XTi,VTi),i=1,2,...,2N,(6)其中 VSA 指的是体素集 Abstraction 模块,且
F
T
i
=
{
F
j
T
i
}
j
=
1
J
⊂
R
1
×
C
\boldsymbol F^{T_i} = \{ F_j^{T_i}\}_{j=1}^J \sub \R^{1 \times C}
FTi={FjTi}j=1J⊂R1×C。
C
C
C 为 grid-wise 特征通道数。
Cross-grid attention
{
F
T
i
}
i
=
1
2
N
\{\boldsymbol F^{T_i}\}_{i=1}^{2N}
{FTi}i=12N 包含多个 instance-level 特征。为了编码更好的局部几何,论文应用一个 cross-grid attention 操作来进一步将多个特征聚合成一个更紧凑的变换不变特征向量。具体来说,对于第
j
j
j 个网格点,串联了
2
N
2N
2N 个 grid-wise 特征
F
j
=
c
o
n
c
a
t
(
F
j
T
1
,
…
,
F
j
T
2
N
)
F_j = concat(F^{T_1}_ j,…, F^{T_{2N}}_j)
Fj=concat(FjT1,…,FjT2N),
F
j
∈
R
2
N
×
C
F_j \in \R^{2N \times C}
Fj∈R2N×C。然后有
Q
j
=
F
j
W
q
,
K
j
=
F
j
W
k
,
V
j
=
F
j
W
v
\boldsymbol Q_j = F_j\boldsymbol W^q,\boldsymbol K_j= F_j \boldsymbol W^k,\boldsymbol V_j= F_j \boldsymbol W^v
Qj=FjWq,Kj=FjWk,Vj=FjWv,其中
W
q
,
W
k
,
W
v
\boldsymbol W^q,\boldsymbol W^k,\boldsymbol W^v
Wq,Wk,Wv都是线性投影。因此,grid-wise 特征为:
F
^
j
=
s
o
f
t
m
a
x
(
Q
j
(
K
j
)
T
C
)
V
j
.
(7)
\tag7 \hat F_j = softmax(\frac{\boldsymbol Q_j(\boldsymbol K_j)^T}{\sqrt{C}})\boldsymbol V_j.
F^j=softmax(CQj(Kj)T)Vj.(7)沿
2
N
2N
2N 平均特征,得到特征
F
^
=
{
F
^
j
}
j
=
1
J
⊂
R
1
×
C
\hat {\boldsymbol F} =\{\hat F_j\}^J_{j =1}\sub \R^{1 \times C}
F^={F^j}j=1J⊂R1×C。然后,这些特征被扁平化成一个单一的特征向量,以执行类似于 object proposal refinement。
距离感知数据增强
远距离物体的几何形状不完整通常会导致检测性能的巨大下降。为了解决这个问题,论文通过从附近的密集对象创建稀疏训练样本来增加遥远稀疏对象的 geometric knowledge。
一种简单的方法是采用随机采样或最远点采样(FPS)。但是,它破坏了激光雷达扫描到的点云的分布模式。为了解决这个问题,论文提出了一种距离感知采样策略,该策略考虑了激光雷达和场景遮挡的 scanning 机制。
具体来说,给定一个位置为
C
g
C^g
Cg 的近地真值 box,内部点
{
P
i
g
}
i
\{P^g_i\}_i
{Pig}i,添加一个随机距离偏移
∆
α
∆α
∆α,即
C
g
:
=
C
g
+
∆
α
C^g:= C^g +∆α
Cg:=Cg+∆α,
P
i
g
:
=
P
i
g
+
∆
α
P^g_i:= P^g_i +∆α
Pig:=Pig+∆α。然后将
{
P
i
g
}
i
\{P^g_i\}_i
{Pig}i 转换为球面坐标系,并根据激光雷达的角度分辨率将它们体素化为球面体素。 在每个体素中,最接近体素中心的点被保留作为采样点。 然后,得到一组采样点,它具有与实际扫描点相似的分布模式。
 由于真实场景中由于遮挡导致的数据不完整是很常见的,因此还随机去除一些部分来模拟遮挡。 在训练过程中,类似于GT-AUG,将采样点和 bounding box 添加到训练样本中进行数据扩充。
由于真实场景中由于遮挡导致的数据不完整是很常见的,因此还随机去除一些部分来模拟遮挡。 在训练过程中,类似于GT-AUG,将采样点和 bounding box 添加到训练样本中进行数据扩充。
论文总结
论文提出了一个高性能的三维目标检测器TED。TED将变换等变体素特征编码为紧凑的场景级和实例级表示,用于目标候选生成和精细化。该设计效率高,能更好地学习物体的几何特征。
局限性:
(1)由于输入的变换是离散的和体素化的,TED的设计不是严格的变换等变的。通过使用更多的变换和更小的体素,TED将更接近完全等变,但这带来了更高的计算成本。
(2)考虑到加入更多的变换方式会增加计算成本,没有考虑缩放变换。
(3)与 baseline 相比,TED需要大约2倍的GPU内存。