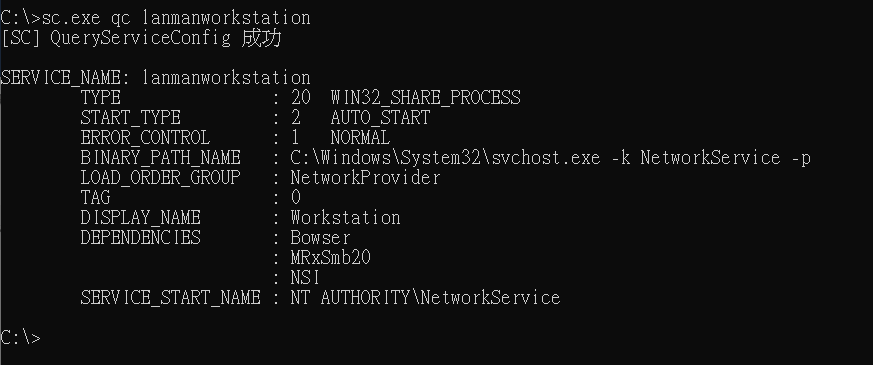
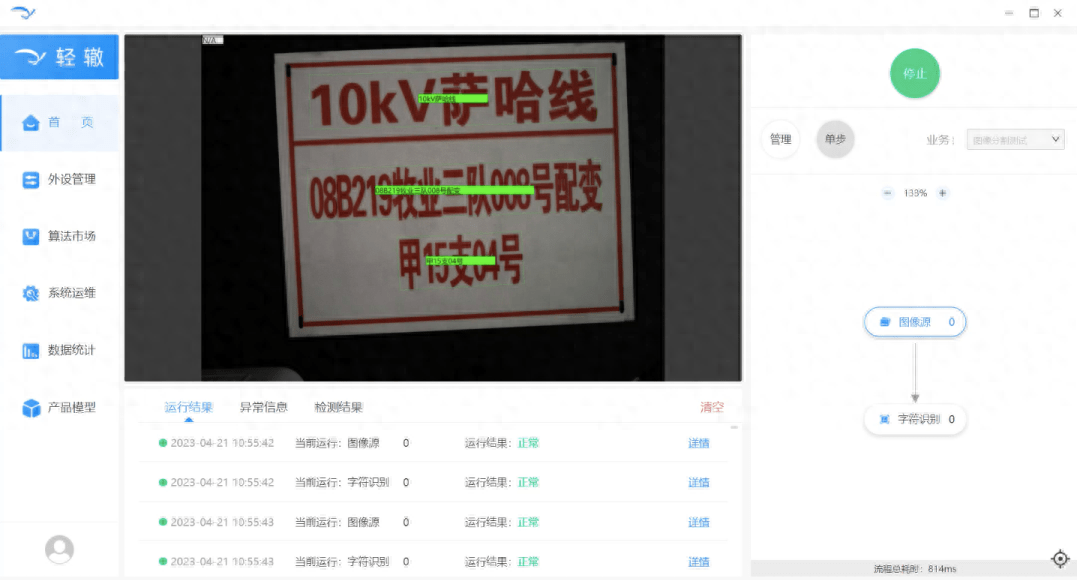
我在最近的工作中遇到了一个问题,问题是我需要根据银行账户在一定时间内的使用信息对该账户在未来的一段时间是否会被销户进行预测。这是一个双元值的分类问题,只有两种可能,即会被销户和不会被销户。针对这个问题一般来说有两种解决策略。
- 提取时间序列的统计学特征值,例如最大值,最小值,均值等。然后利目前常用的算法根据提取的特征进行分类,例如Naive Bayes, SVMs 等。
- k-NN方法。针对想要预测的时间序列,在训练集中找一个跟它最相似的另外一个序列,然后利用找到的序列的输出值作为原序列的预测值。
下面我会使用这两种算法,运行并对比结果,然后找到最合适的算法。
找到相似数据
针对这个问题,一般会使用欧氏距离寻找相似,但这种方法存在很多问题。如下文给出的示例。如图所示,有三个时间序列:

很明显,序列ts1和ts2的相似度更高,ts3和其他两个相比的差异性更大。为了验证结果,可以通过编程求得这三个序列之间的欧氏距离d(ts1, ts2)和d(ts1,ts3)。下面编写一个计算欧氏距离的函数:
def euclid_dist(t1,t2):
return sqrt(sum((t1-t2)**2))
通过计算,结果是d(ts1,ts2)=26.9,d(ts1,ts3)=23.2。很明显,与我们直觉判断相悖。这就是利用欧氏距离标准来判定相似性存在的问题。为了解决这个问题,引入另一个方法——DTW。
动态时间规整(Dynamic Time Warping, DTW)
DTW可以针对两个时间序列找到最优的非线定位(non-linear alignment)。定位之间的欧氏距离不太容易受到时间轴方向上的失真所造成的负面相似性测量的影响。但是我们也必须为这种方法付出代价,即DTW是所有用到的时间序列的数据数量的二次方。
DTW的工作方式如下。我们可以引入两个时间序列Q和C,这两个时间序列都拥有n个数据点,Q=q_1, q_2, \cdots, q_n和C=c_1, c_2, \cdots, c_n。首先我们用这两个时间序列去构造一个n\times n的矩阵,这个矩阵中的第i,j^{th}项代表的是数据点q_i和c_j之间的欧氏距离。我们需要通过这个矩阵找到一个变量,通过该变量可以使所有的欧氏距离和最小。这个变量可以决定两个时间序列之间的最优非线性定位。需要注意的是,对于其中一个时间序列上的数据点,它是有可能映射到另一条时间序列上的多个数据点。
我们可以把这个变量记作W,W = w_1,w_2,\cdots,w_n。其中每一个W代表的都是Q中的第i个点与C中的第j个点之间的距离,即w_k=(q_i-c_j)^2。
因为我们需要找到这个变量的最小值,即W^*=argmin_W(\sqrt{\sum_{k=1}^{K}w_k}),为了找到这个值我们需要通过动态的方法,特别是接下来的这个递归函数。\gamma(i,j)=d(q_i,c_j)+min(\gamma(i-1,j-1),\gamma(i-1,j),\gamma(i,j-1))。该算法可以通过以下的Python代码实现。
def DTWDistance(s1, s2):
DTW={}
for i in range(len(s1)):
DTW[(i, -1)] = float('inf')
for i in range(len(s2)):
DTW[(-1, i)] = float('inf')
DTW[(-1, -1)] = 0
for i in range(len(s1)):
for j in range(len(s2)):
dist= (s1[i]-s2[j])**2
DTW[(i, j)] = dist + min(DTW[(i-1, j)],DTW[(i, j-1)], DTW[(i-1, j-1)])
return sqrt(DTW[len(s1)-1, len(s2)-1])
通过DTW计算,DTWDistance(ts1,ts2)=17.9,DTWDDistance(ts1,ts3)=21.5。正如我们所看到的,该结果与只利用欧氏距离算法得到的结果截然不同。现在,这个结果就符合我们的主观腿断了,即ts2相比于ts3与ts1更为相似。
提高DTW算法计算速度
DTW的复杂度O(nm)是与两个时间序列的数据数量正相关的。如果两个时间序列都含有大量数据,那么这种方法的计算时间会非常长。因此我们需要通过一些方法去提高计算速度。第一种方法是强制执行局部性约束。这种方法假设当i和j相距太远,则q_i和c_j不需要匹配。这个阈值则由一个给定的窗口大小w决定。这种方法可以提高窗口内循环的速度。详细代码如下:
def DTWDistance(s1, s2, w):
DTW={}
w = max(w, abs(len(s1)-len(s2)))
for i in range(-1,len(s1)):
for j in range(-1,len(s2)):
DTW[(i, j)] = float('inf')
DTW[(-1, -1)] = 0
for i in range(len(s1)):
for j in range(max(0, i-w), min(len(s2), i+w)):
dist= (s1[i]-s2[j])**2
DTW[(i, j)] = dist + min(DTW[(i-1, j)],DTW[(i, j-1)], DTW[(i-1, j-1)])
return sqrt(DTW[len(s1)-1, len(s2)-1])
另一种方法是使用LB Keogh下界方法DTW的边界。
LBKeogh(Q,C)=\sum_{i=1}^{n}(c_i-U_i)^2I(c_i>U_i)+(c_i-L_i)^2I(c_i < U_i)
U_i和L_i是时间序列Q的上下边界,U_i=max(q_{i-r}:q_{i+r}),L_i=min(q_{i-r}:q_{i+r})。其中r是可达到的边界,I(\cdot)是指示函数。该方法可以通过以下代码实现。
def LB_Keogh(s1,s2,r):
LB_sum=0
for ind,i in enumerate(s1):
lower_bound=min(s2[(ind-r if ind-r>=0 else 0):(ind+r)])
upper_bound=max(s2[(ind-r if ind-r>=0 else 0):(ind+r)])
if i>upper_bound:
LB_sum=LB_sum+(i-upper_bound)**2
elif i<lower_bound:
LB_sum=LB_sum+(i-lower_bound)**2
return sqrt(LB_sum)
LB Keogh小界方法是线性的,而DTW则是复杂的二次方形式,这使得它在处理大量时间序列的时候非常有利。
分类与聚类
现在我们有了可靠的方法去判断两个时间序列是否相似,截下来便可以使用k-NN算法进行分类。根据经验,最优解一般出现在k=1的时候。下面就利用DTW欧氏距离的1-NN算法。在该算法中,train是时间序列示例的训练集,其中时间序列所属的类被附加到时间序列的末尾。test是相应的测试集,它所属于的类别就是我们想要预测的结果。在该算法中,对于测试集中的每一个时间序列,每一遍搜索必须遍历训练集中的所有点,从而可以找到最多的相似点。考虑到DTW算法是二次方的,计算过程会耗费非常长时间。我们可以通过LB Keogh下界方法来提高分类算法的计算速度。计算机运行LB Keogh的速度会比运行DTW的速度快很多。另外,当LBKeogh(Q,C)\leq DTW(Q,C)时,我们可以消除那些比当前最相似的时间序列不可能更相似的时间序列。这样,我们就可以消除很多不必要的DTW计算过程。
from sklearn.metrics import classification_report
def knn(train,test,w):
preds=[]
for ind,i in enumerate(test):
min_dist=float('inf')
closest_seq=[]
#print ind
for j in train:
if LB_Keogh(i[:-1],j[:-1],5)<min_dist:
dist=DTWDistance(i[:-1],j[:-1],w)
if dist<min_dist:
min_dist=dist
closest_seq=j
preds.append(closest_seq[-1])
return classification_report(test[:,-1],preds)
下面测试一批数据。设置窗口大小为4。另外,尽管这里使用了LB Keogh下界方法和局部性约束,计算过程仍然需要几分钟。
train = np.genfromtxt('datasets/train.csv', delimiter='\t')
test = np.genfromtxt('datasets/test.csv', delimiter='\t')
print knn(train,test,4)
运行结果如下

这种方法也可用于k-mean聚类。在这种算法中,簇的数量设置为apriori,相似的时间序列会被放在一起。
import random
def k_means_clust(data,num_clust,num_iter,w=5):
centroids=random.sample(data,num_clust)
counter=0
for n in range(num_iter):
counter+=1
print counter
assignments={}
#assign data points to clusters
for ind,i in enumerate(data):
min_dist=float('inf')
closest_clust=None
for c_ind,j in enumerate(centroids):
if LB_Keogh(i,j,5)<min_dist:
cur_dist=DTWDistance(i,j,w)
if cur_dist<min_dist:
min_dist=cur_dist
closest_clust=c_ind
if closest_clust in assignments:
assignments[closest_clust].append(ind)
else:
assignments[closest_clust]=[]
#recalculate centroids of clusters
for key in assignments:
clust_sum=0
for k in assignments[key]:
clust_sum=clust_sum+data[k]
centroids[key]=[m/len(assignments[key]) for m in clust_sum]
return centroids
再用这种算法测试一下数据:
train = np.genfromtxt('datasets/train.csv', delimiter='\t')
test = np.genfromtxt('datasets/test.csv', delimiter='\t')
data=np.vstack((train[:,:-1],test[:,:-1]))
import matplotlib.pylab as plt
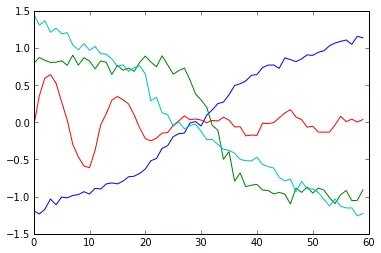
centroids=k_means_clust(data,4,10,4)
for i in centroids:
plt.plot(i)
plt.show()
结果如图
代码
所有用到的代码都可以在my gitHub repo找到。
转载:https://www.cnblogs.com/think90/articles/11975242.html