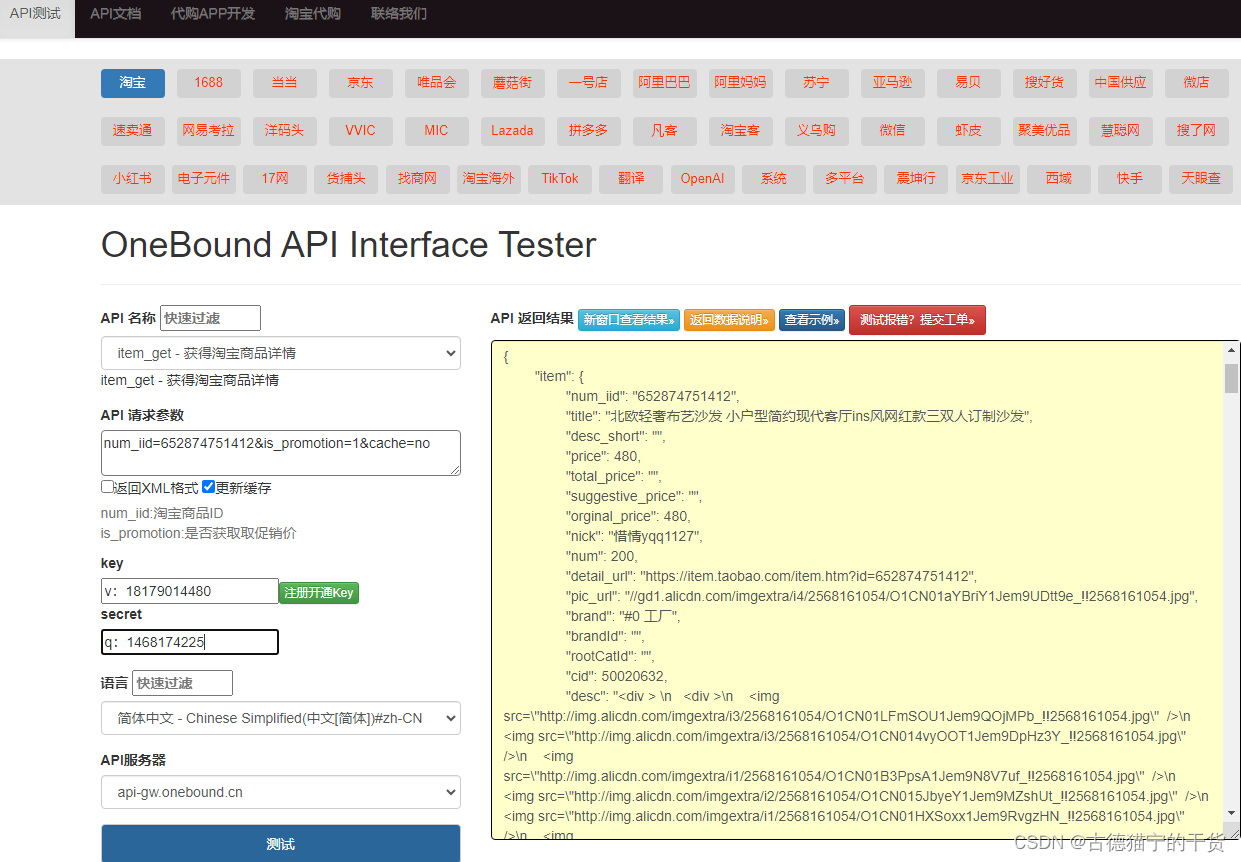
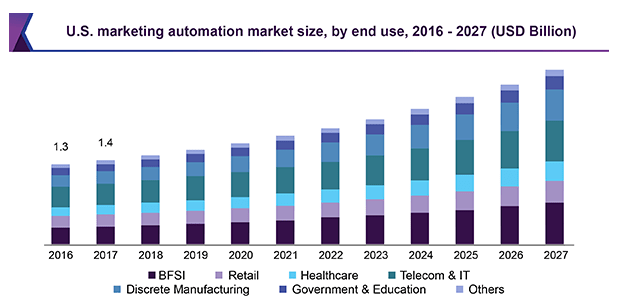
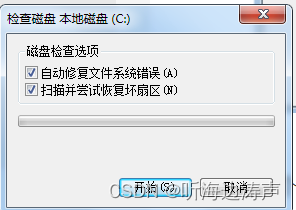
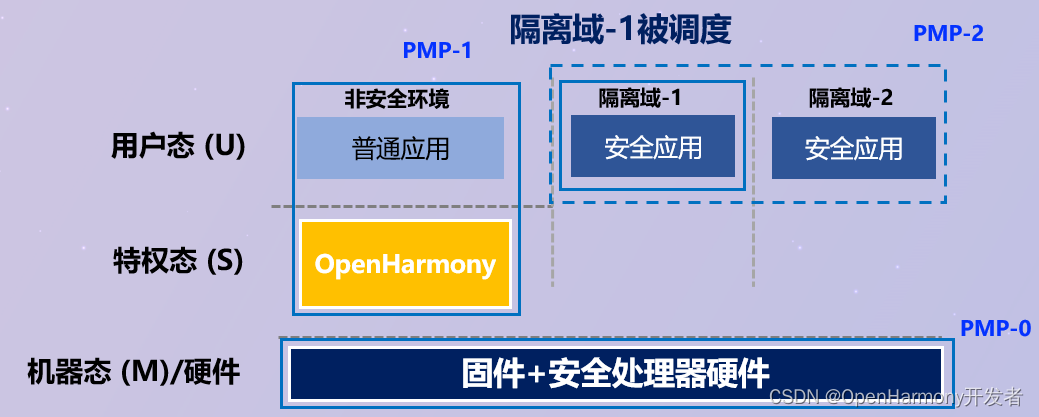
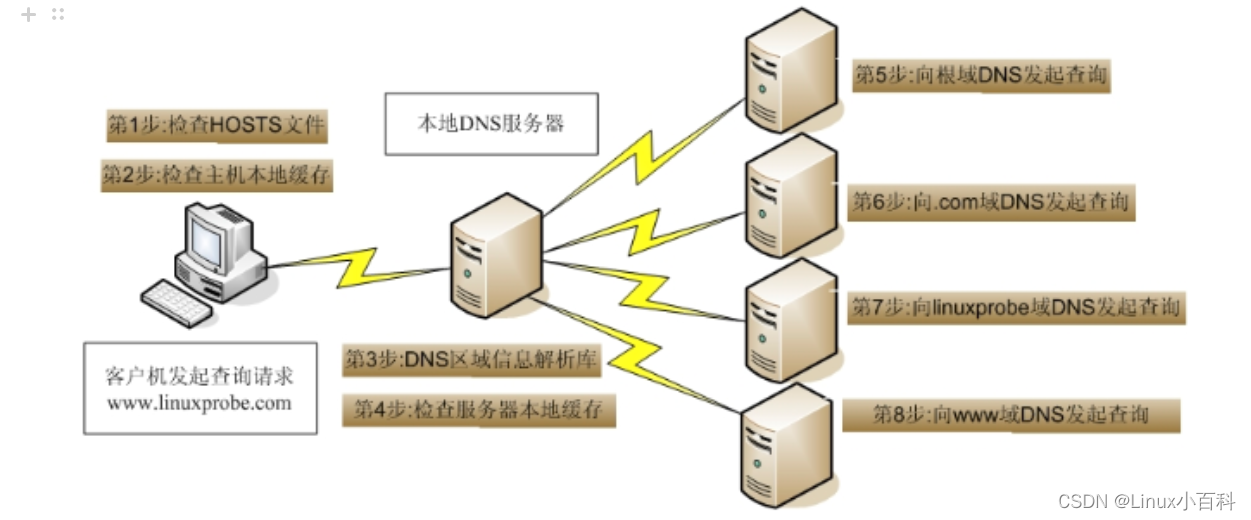
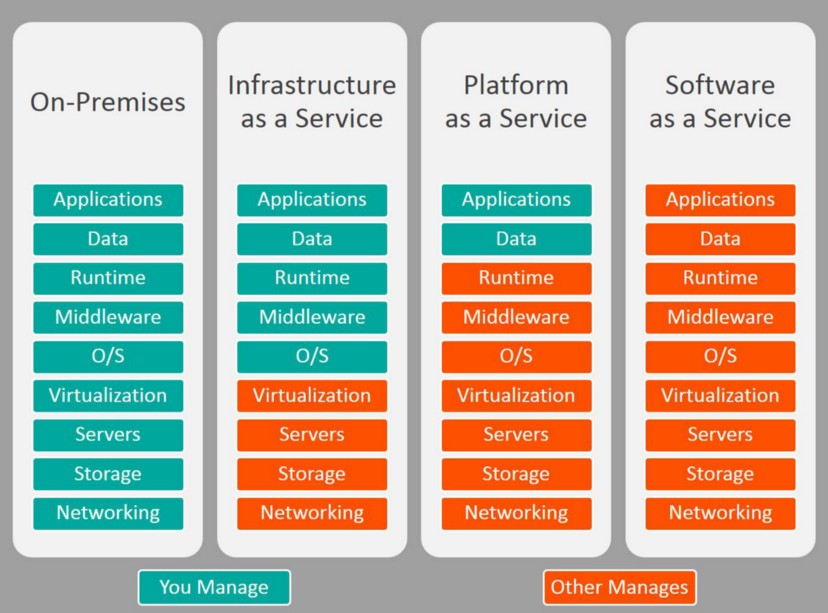
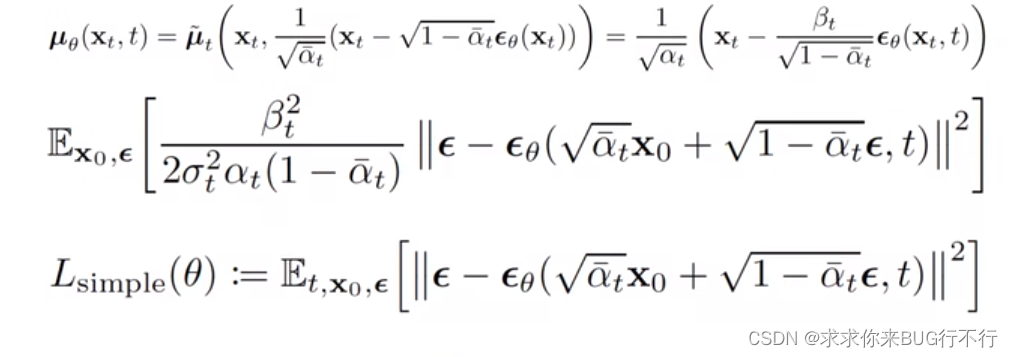Google DeepMind 开发的一款机器人操作系统RoboTAP。该系统能够通过只需几分钟的示范,就能让机器人学会新的视觉运动任务。你只需要给它展示几次如何做某件事,比如拿起一个苹果放到果冻上,它就能学会这个动作。
工作原理
该系统能够通过视觉伺服控制器来解决多种视觉运动任务。RoboTAP的核心是一个通用控制器,该控制器能够对场景中的点进行对齐。系统通过密集跟踪来解决多任务操作问题,包括什么(what)、在哪里(where)以及如何(how)进行操作。RoboTAP能够在几分钟内通过少量的示范来学习这些行为。它使用摄像头或其他视觉传感器来获取环境信息,并根据这些信息来控制机器人或其他自动化设备的动作。
控制器不仅能识别目标物体,还能识别物体上的特定点或特征,并据此进行操作。这种能力使得 RoboTAP 能够执行多种复杂的视觉运动任务,例如拾取和放置、插入和堆叠等。这种精确的控制也意味着 RoboTAP 可以在多变的环境中工作,包括那些物体姿态和位置不断变化的环境。
主要组件
通用控制器:这是系统的核心,负责执行所有任务。
视觉伺服控制器:用于跟踪和对齐场景中的特定点。
密集跟踪:系统使用密集跟踪技术来解决多任务操作问题。
功能和应用
- 快速学习:只需几分钟的示范,RoboTAP 就能学习新的视觉运动任务。
- 多任务操作:能够解决拾取和放置、插入、堆叠等多种任务。
- 环境适应性:能够适应不同的环境和物体姿态。
- 局限性:在需要极高精度或多模态(视觉+力量)输入的任务中可能不适用。
论文:arxiv.org/abs/2308.15975
视频演示
RoboTAP 利用 DeepMind 开发的先进点追踪算法 TAPIR(Tracking Algorithm for Point Inference and Recognition)来解决模板插入和其他多种任务。
这个系统不需要 CAD 模型或与目标物体的先前经验。它能够在每一时刻检测对动作最重要的物体上的点(标记为红色),推断这些点应该移动到哪里(标记为青色),并计算一个将它们移动到那里的动作(标记为橙色箭头)。
这种方法的优势在于它能够从少于或等于 6 次的示范中快速学习和解决任务,这大大减少了训练时间和复杂性。
这个系统不需要 CAD 模型或与目标物体的先前经验。它能够在每一时刻检测对动作最重要的物体上的点(标记为红色),推断这些点应该移动到哪里(标记为青色),并计算一个将它们移动到那里的动作(标记为橙色箭头)。
这种方法的优势在于它能够从少于或等于 6 次的示范中快速学习和解决任务,这大大减少了训练时间和复杂性。

![CMS-织梦[dede]-通用免登发布插件](https://img-blog.csdnimg.cn/60bbb02f08e74107a712d21a01b0ac21.png)