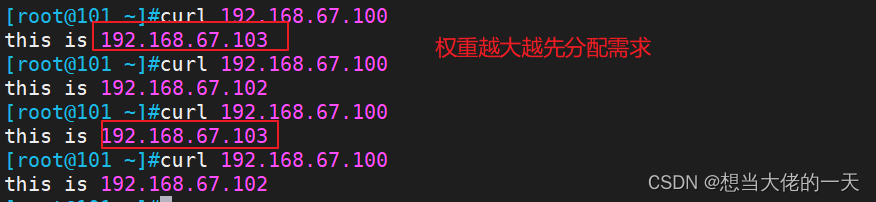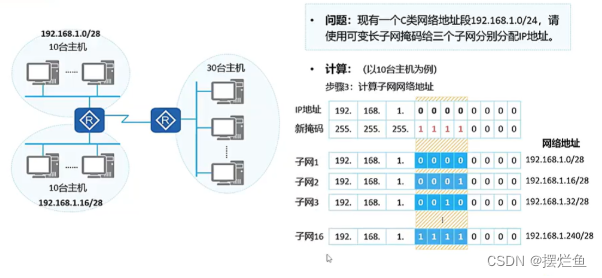
一、介绍
2017是机器学习中具有历史意义的一年,当变形金刚模型首次出现在现场时。它在许多基准测试上都表现出色,并且适用于数据科学中的许多问题。由于其高效的架构,后来开发了许多其他基于变压器的模型,这些模型更专注于特定任务。
其中一个模型是BERT。它主要以能够构建嵌入而闻名,这些嵌入可以非常准确地表示文本信息并存储长文本序列的语义含义。因此,BERT嵌入在机器学习中得到了广泛的应用。理解BERT如何构建文本表示至关重要,因为它为处理NLP中的大量任务打开了大门。
在本文中,我们将参考原始的BERT论文,并查看BERT架构并了解其背后的核心机制。在第一节中,我们将对BERT进行高级概述。之后,我们将逐步深入了解其内部工作流程以及如何在整个模型中传递信息。最后,我们将学习如何微调BERT以解决NLP中的特定问题。
二、高级概述
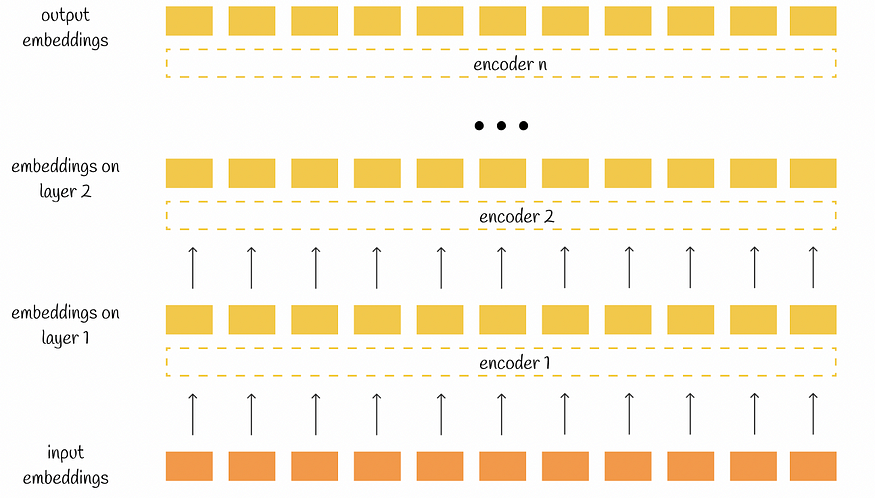
Transformer的架构由两个主要部分组成:编码器和解码器。堆叠编码器的目标是为输入构造有意义的嵌入,以保留其主要上下文。最后一个编码器的输出将传递给所有尝试生成新信息的解码器的输入。
BERT是变压器的后继产品,继承了其堆叠式双向编码器。BERT中的大多数架构原理与原始变压器中的架构原理相同。
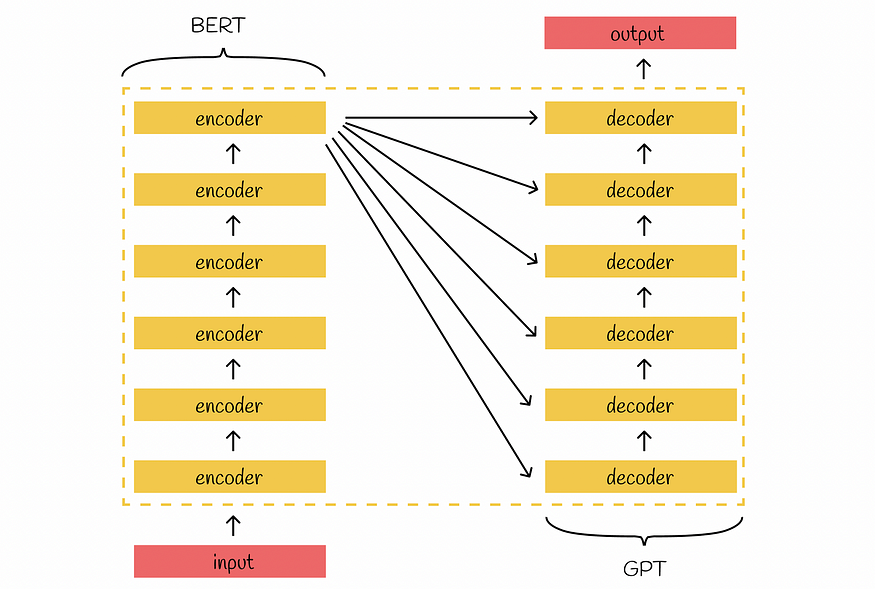
变压器架构
三、Bert版本
BERT有两个主要版本:基本版本和大型版本。它们的架构是完全相同的,除了它们使用不同数量的参数。总体而言,与BERT基础相比,BERT large需要调整的参数多3.09倍。

BERT基底和BERT大基的比较
四、双向表示
从BERT名称中的字母“B”开始,重要的是要记住BERT是一个双向模型,这意味着由于信息是双向传递的(从左到右和从右到左),它可以更好地捕获单词连接。显然,与单向模型相比,这会产生更多的训练资源,但同时会导致更好的预测准确性。
为了更好地理解,我们可以将BERT架构与其他流行的NLP模型进行比较。
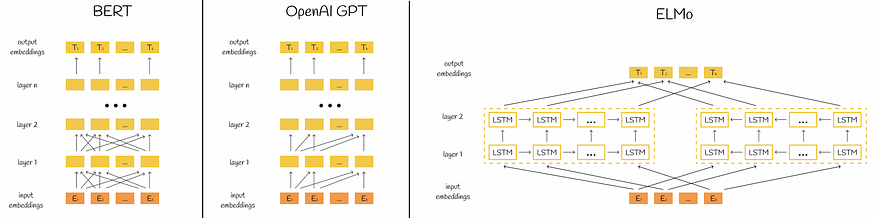
比较来自 ogirinal 论文的 BERT、OpenAI GPT 和 ElMo 架构。作者采纳。
五、输入标记化
小说在官方论文中,作者使用术语“句子”来表示传递给输入的文本。为了指定相同的术语,在本系列文章中,我们将使用术语“序列”。这样做是为了避免混淆,因为“句子”通常意味着由一个点分隔的单个短语,并且由于在许多其他NLP研究论文中,术语“序列”在类似情况下使用。
在深入研究如何训练BERT之前,有必要了解它接受数据的格式。对于输入,BERT采用单个序列或一对序列。每个序列被拆分为令牌。此外,两个特殊令牌将传递给输入:
小说官方论文使用术语“句子”,它表示传递给BERT的输入序列,该序列实际上可以由几个句子组成。为简单起见,我们将遵循符号并在本文中使用相同的术语。
- [CLS] — 在指示其开始的第一个序列之前传递。同时,[CLS] 还用于训练期间的分类目标(在以下部分中讨论)。
- [SEP] — 在序列之间传递,以指示第一个序列的结束和第二个序列的开始。
传递两个序列使BERT可以处理输入包含一对序列的各种任务(例如问题和答案,假设和前提等)。
六、输入嵌入
标记化后,将为每个令牌构建一个嵌入。为了使输入嵌入更具代表性,BERT为每个令牌构造了三种类型的嵌入:
- 令牌嵌入捕获令牌的语义含义。
- 段嵌入具有两个可能的值之一,并指示令牌属于哪个序列。
- 位置嵌入包含有关序列中令牌的相对位置的信息。

输入处理
对这些嵌入进行汇总,并将结果传递给BERT模型的第一个编码器。
七、输出
每个编码器将 n 个嵌入作为输入,然后输出相同数量的相同维度的已处理嵌入。最终,整个BERT输出还包含n个嵌入,每个嵌入对应于其初始令牌。
八、训练
BERT培训包括两个阶段:
- 预培训。BERT在两个预测任务中对未标记的序列对进行训练:掩蔽语言建模(MLM)和自然语言推理(NLI)。对于每对序列,模型对这两个任务进行预测,并根据损失值执行反向传播以更新权重。
- 微调。BERT使用预先训练的权重进行初始化,然后针对标记数据上的特定问题进行优化。
九、预培训
与微调相比,预训练通常需要相当大比例的时间,因为模型是在大量数据语料库上进行训练的。这就是为什么存在许多预先训练模型的在线存储库,然后可以相对较快地对其进行微调以解决特定任务。
我们将详细研究BERT在预训练期间解决的两个问题。
9.1 遮罩语言建模
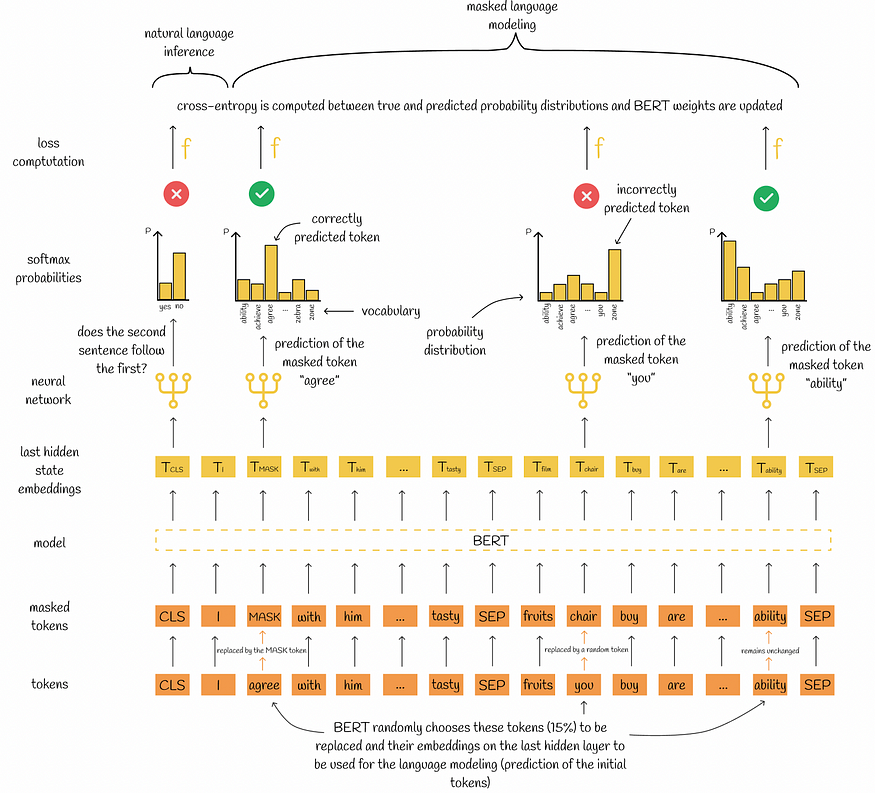
作者建议通过在初始文本中屏蔽一定数量的标记并预测它们来训练BERT。这使BERT能够构建弹性嵌入,该嵌入可以使用周围的上下文来猜测某个单词,这也导致为遗漏的单词构建适当的嵌入。此过程的工作方式如下:
- 标记化后,随机选择15%的令牌进行屏蔽。然后,所选令牌将在迭代结束时进行预测。
- 所选令牌以以下三种方式之一替换:
- 80% 的令牌由 [MASK] 令牌替换。
示例:我买了一本书→买了一个[MASK]
- 10%的代币被随机代币取代。
示例:他正在吃一个水果→他正在抽一个水果
- 10%的代币保持不变。
示例:房子在我附近 → 房子在我附近 - 所有令牌都传递给BERT模型,该模型为其作为输入接收的每个令牌输出嵌入。
4. 与步骤 2 中处理的令牌对应的输出嵌入独立用于预测屏蔽的令牌。每个预测的结果是词汇表中所有标记的概率分布。
5. 交叉熵损失是通过将概率分布与真实掩蔽令牌进行比较来计算的。
6. 使用反向传播更新模型权重。
9.2 自然语言推理
对于此分类任务,BERT尝试预测第二个序列是否遵循第一个序列。整个预测是通过仅使用 [CLS] 令牌的最终隐藏状态的嵌入来进行的,该令牌应该包含来自两个序列的聚合信息。
与MLM类似,构造的概率分布(在本例中为二进制)用于计算模型的损失并通过反向传播更新模型的权重。
对于NLI,作者建议选择50%的序列对,这些序列在语料库中相互跟随(正对)和50%的序列对,其中序列是从语料库中随机获取的(负对)。
伯特预培训
9.3 培训详情
根据该论文,BERT在BooksCorpus(800亿字)和英语维基百科(2,500M字)上进行了预训练。为了提取较长的连续文本,作者从维基百科中只阅读了忽略表格,标题和列表的段落。
BERT在256万个批次上训练,大小等于40个序列,相当于3亿个单词的3个epoch。每个序列最多包含 128(90% 的时间)或 512(10% 的时间)令牌。
根据原论文,训练参数如下:
- 优化器:亚当(学习率 l = 1e-4,权重衰减 L₂ = 0.01,β₁ = 0.9,β₂ = 0.999,ε = 1e-6)。
- 学习率预热在前 10 步内执行,然后线性降低。
- 所有图层都使用压差 (α = 0.1) 图层。
- 激活功能:格鲁。
- 训练损失是平均MLM和平均下一句预测可能性的总和。
9.4 微调
一旦预训练完成,BERT就可以从字面上理解单词的语义含义,并构建几乎可以完全表示其含义的嵌入。微调的目标是逐步修改BERT权重以解决特定的下游任务。
十、数据格式
由于自我注意机制的稳健性,BERT可以很容易地针对特定的下游任务进行微调。BERT的另一个优点是能够构建双向文本表示。这提供了在处理对时发现两个序列之间正确关系的更高机会。以前的方法包括独立编码两个序列,然后对它们应用双向交叉注意力。BERT统一了这两个阶段。
根据某个问题,BERT接受多种输入格式。使用BERT解决所有下游任务的框架是相同的:通过将文本序列作为输入,BERT输出一组令牌嵌入,然后将其馈送到模型。大多数情况下,并非所有输出嵌入都使用。
让我们看一下常见问题以及通过微调BERT解决它们的方法。
句子对分类
句子对分类的目标是了解给定序列对之间的关系。大多数常见的任务类型是:
- 自然语言推理:确定第二个序列是否遵循第一个序列。
- 相似性分析:查找序列之间的相似程度。

Sentence pair classification
为了进行微调,两个序列都传递给BERT。根据经验,[CLS] 令牌的输出嵌入随后将用于分类任务。根据研究人员的说法,[CLS]令牌应该包含有关句子关系的主要信息。
当然,也可以使用其他输出嵌入,但在实践中通常会省略它们。
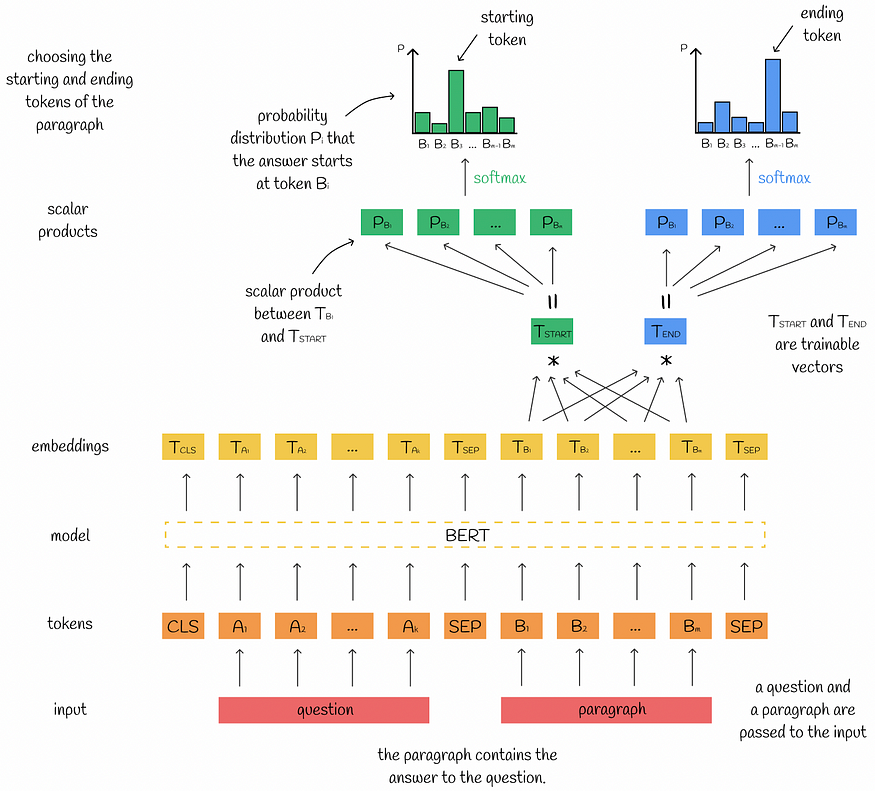
问答任务
问答的目的是在与特定问题对应的文本段落中找到答案。大多数时候,答案以两个数字的形式给出:通道的开始和结束令牌位置。
问答任务
对于输入,BERT接受问题和段落,并为它们输出一组嵌入。由于答案包含在段落中,因此我们只对与段落标记对应的输出嵌入感兴趣。
为了查找段落中开始答案标记的位置,计算每个输出嵌入与特殊可训练向量 Tstₐrt 之间的标量积。对于大多数情况下,当模型和向量 Tstₐrt 经过相应训练时,标量积应与相应令牌实际上是起始答案令牌的可能性成正比。为了规范化标量积,然后将它们传递给softmax函数,并且可以将其视为概率。与最高概率对应的令牌嵌入被预测为开始答案令牌。基于真实概率分布,计算损失值并执行反向传播。使用向量 Tₑnd 执行类似的过程来预测结束标记。
单句分类
与以前的下游任务相比,不同之处在于这里只传递了一个句子 BERT。此配置解决的典型问题如下:
- 情感分析:了解一个句子是积极的态度还是消极的态度。
- 主题分类:根据句子的内容将句子分类为几个类别之一。

单句分类
预测工作流与句子对分类相同:[CLS] 标记的输出嵌入用作分类模型的输入。
单句标记
命名实体识别(NER)是一个机器学习问题,旨在将序列的每个标记映射到相应的实体之一。

单句标记
为此,像往常一样计算输入句子标记的嵌入。然后,每个嵌入([CLS] 和 [SEP] 除外)都独立地传递给一个模型,该模型将它们中的每一个映射到给定的 NER 类(或者不是,如果不能)。
十一、特征提取
获取最后一个BERT层并将其用作嵌入并不是从输入文本中提取特征的唯一方法。事实上,研究人员完成了几个以不同方式聚合嵌入的实验,以解决CoNLL-2003数据集上的NER任务。为了进行实验,他们在应用分类层之前使用提取的嵌入作为随机初始化的双层 768 维 BiLSTM 的输入。
下图演示了嵌入(从BERT基中提取)的方式。如图所示,性能最高的方法是连接最后四个BERT隐藏层。
基于进行的实验,重要的是要记住,隐藏层的聚合是改善嵌入表示的潜在方法,以便在各种NLP任务上获得更好的结果。
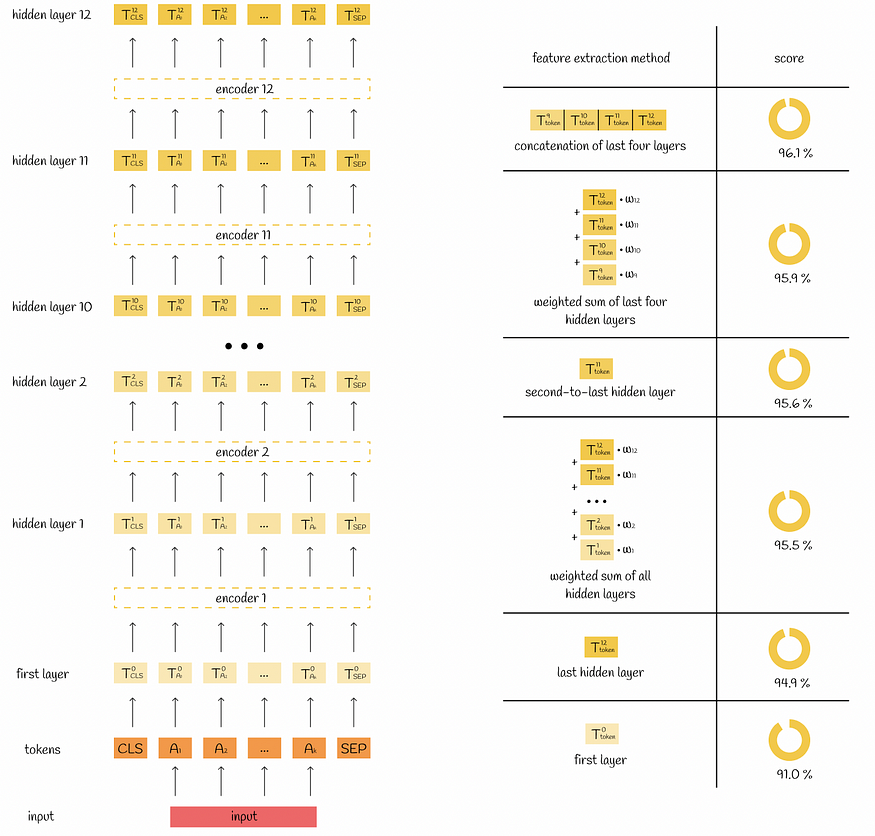
左图显示了带有隐藏层的扩展BERT结构。右表说明了嵌入的构造方式以及通过应用相应策略获得的相应分数。
十二、将BERT与其他功能相结合
例如,有时我们不仅处理文本,还处理数字特征。构建可以合并来自文本和其他非文本特征的信息的嵌入是自然可取的。以下是建议的应用策略:
- 文本与非文本功能的串联。例如,如果我们以文本形式处理有关人员的个人资料描述,并且还有其他单独的功能,例如他们的姓名或年龄,则可以以以下形式获得新的文本描述:“我的名字是<姓名>。<个人资料描述>。我<岁>”。最后,这样的文本描述可以输入到BERT模型中。
- 嵌入与特征的串联。如上所述,可以构建BERT嵌入,然后将它们与其他功能连接起来。配置中唯一更改的是下游任务的分类模型现在必须接受更高维度的输入向量。
维亚切斯拉夫·叶菲莫夫
十三、结论
在本文中,我们深入探讨了BERT训练和微调的过程。事实上,这些知识足以解决NLP中的大多数任务,值得庆幸的是,BERT允许几乎完全将文本数据合并到嵌入中。
最近,出现了其他类似BERT的模型(SBERT,RoBERTa等)。甚至还有一个名为“BERTology”的特殊研究领域,它深入分析BERT功能,以推导出新的高性能模型。这些事实强化了这样一个事实,即BERT指定了机器学习的一场革命,并使NLP的显着进步成为可能