熟悉我们的朋友都知道,在 Milvus 和 Zilliz Cloud 中,有一个至关重要的组件——Knowhere。
Knowhere 是什么?如果把向量数据库整体看作漫威银河护卫队宇宙,那么 Knowhere 就是名副其实的总部,它的主要功能是对向量精确搜索其最近邻或通过构建索引进行低延迟、近似的最近邻搜索(ANNS)。
Knowhere 2.x 版本自 2022 年 7 月开始重构,经过多次方案讨论、设计、开发和测试的迭代,终于随着 Milvus 2.3 和各位见面了。对于用户而言,相较于 1.x 版本,Knowhere 2.x 版本提供了更规范的接口以及更丰富的功能,例如支持 GPU 索引、Cosine 相似性类型、ScaNN 索引和 ARM 架构等。对于开发者来说,升级后的 Knowhere 可以更方便地增加新的索引算法,利于后期维护。
接下来我将详细为大家介绍 Knowhere 2.x 的新功能、优化及设计理念。
支持 GPU 索引
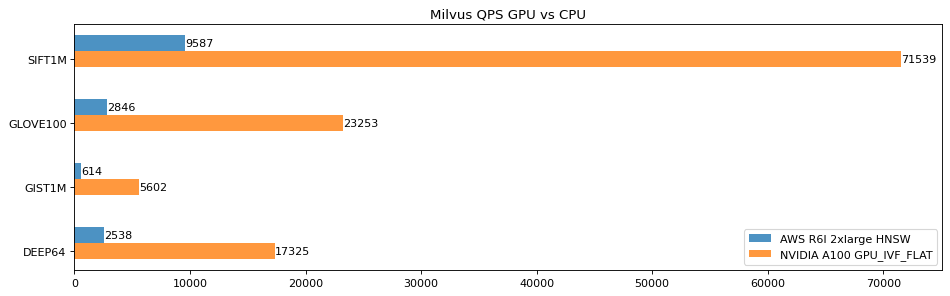
Zilliz 一直都非常欢迎外部开发者提出想法和贡献代码,此前,英伟达(Nvidia)公司在 Knowhere 2.x 版本贡献了其向量搜索库 RAFT 中的 GPU_FLAT 和 GPU_IVFPQ 索引。GPU 强劲的算力在一些场景下可以显著地加速索引搜索的过程。相较于 CPU 版本,Milvus 端到端性能在 Nvidia A100 上的吞吐量有了显著提升(SIFT1M 近 70 倍)。GPU 索引详细内容请访问 https://milvus.io/docs/install_standalone-gpu-docker.md。
支持 Cosine 相似性类型
在 Knowhere 1.x 版本上,如果想使用 Cosine 相似性类型,用户需要使用 Inner Product 相似性类型并在插入向量前进行归一化操作,使得其在数学上是等价的。这不仅对于用户有更高理论知识的要求,也增加了使用的成本和接入的难度。
Knowhere 2.x 版本原生支持 Cosine 距离并在库内部自动归一化传入向量并适配对应的索引类型,大大减少了理解成本,提升了用户体验。
支持 ScaNN 索引
Faiss 实现的 ScaNN,又名 FastScan,使用更小的 PQ 编码和相应的指令集可以更为友好地访问 CPU 寄存器,从而使其拥有优秀的索引性能。该索引在 Cohere 数据集,Recall 约 95% 的时候,Milvus 使用 Knowhere 2.x 版本端到端的 QPS 是 IVF_FLAT 的 7 倍,HNSW 的 1.2 倍。
支持 ARM 架构
ARM 架构对比 x86 架构,虽然其性能弱于后者,但因为更简单的设计和指令集,ARM 架构的能效和功耗更低,所以价格更为便宜。在 AWS 云平台相同 CPU 规格,如 1 vCPU,16GB 内存的情况下,ARM 实例比 x86 实例的价格低 15% 左右。Knowhere 2.x 版本支持了 ARM 架构,使得用户可以在此架构上运行和搭建上层服务。
支持 Range Search
最近邻问题包括 K 近邻问题 (KNN) 和范围搜索 (Range Search)。前者解决的问题是给定一个向量集合 X,参数 k 和查询向量 q,索引返回在向量集合 X 中由相似性类型定义的离查询向量 q 最“近”的 k 个向量。范围搜索则不给定参数 k,它需要给定一个范围 (radius),索引返回在向量集合 X 中与查询向量 q 的距离在范围内的所有向量。
Knowhere 2.x 为库中的多个索引提供了范围搜索的功能,例如 HNSW,DiskANN 还有 IVF 系列等。不同于 K 近邻问题,范围搜索返回向量的数目是预先不可知的。这对于结果的返回也提出了更高的要求,试考虑查询范围取查询向量 q 与向量集合 X 中最远向量的距离,结果将尝试返回整个向量集合。对此,Milvus 提供了对查询结果分页的功能,具体可参考 https://milvus.io/docs/within_range.md。
优化过滤查询
在向量查询中,可能存在有部分向量已经被删除的情况。或者在标量与向量的混合查询中,有一部分向量已经被标量查询先行过滤,例如数据库中有日期的标量列,并且用户只希望在满足特定日期的向量中进行查询。在大部分向量被过滤的场景下,Knowhere 2.x 针对 HNSW 的过滤向量查询进行了优化,使其相较于之前版本有至多 6 到 80 倍的性能提升。
优化代码结构和编译
Knowhere 2.x 版本简化了 C++ 类之间的继承关系,减少了函数调用;使用代理模式来规范新索引的接入,使得错误使用的风险更低;重构了 Config 模块,使用起来更为方便快捷;使用 conan 作为包管理工具,简化和加速了编译流程;使用 Folly 中的线程池来获得对于线程更为精准的把控。
支持 MMAP
MMAP (Memory Mapping) 将文件或设备映射到内存,即进程的地址空间。一些用户可能数据量较大但苦于没有足够的内存空间放置索引。用户之前可以尝试使用磁盘索引 DiskANN,现在也可以尝试使用 MMAP。用户选择开启后,Milvus 和 Knowhere 2.x 会自动将大文件进行内存映射,从而可以在内存不足的情况下使用大索引数据。
支持从索引获得原始向量
用户在搜索完成后,可能需要通过返回的 ID 取得原始向量,进一步进行定制化的计算或筛选。在之前版本的 Milvus 中,需要通过从例如 S3 或其他远程存储中获得。Knowhere 2.x 版本支持从索引中直接获得原始向量。因为索引本身已经被加载到内存(除 DiskANN 以外),该操作的延时会远低于从 S3 获取。值得注意的是并不是所有索引都支持,例如 IVFPQ 对原始向量进行了量化处理,从而丢失了这一信息。具体索引支持的表格详见 https://github.com/zilliztech/knowhere/releases/tag/v2.2.0。
至此,我们罗列了部分 Knowhere 2.x 重要的新功能和优化。希望本文能帮助大家对此有更为清晰的认识,也欢迎大家在 Knowhere 仓库的 issue https://github.com/zilliztech/knowhere/issues 中提出宝贵的意见和建议。同时,Milvus 2.3 系列解读会持续更新,下一篇的主题是 Milvus 最新的消息队列 NATS,敬请期待!
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布