Python之列表操作和内存模型
列表list
-
一个排列整齐的队伍,Python采用顺序表实现
-
列表内的个体称作元素,由若干元素组成
-
列表 元素可以是任意对象(数字、字符串、对象、列表等)
-
列表内元素有顺序,可以使用索引
-
线性的数据结构 使用 [ ] 表示
-
列表是可变的
列表是非常重要的数据结构,对其内存结构和操作方法必须烂熟于心。

索引
-
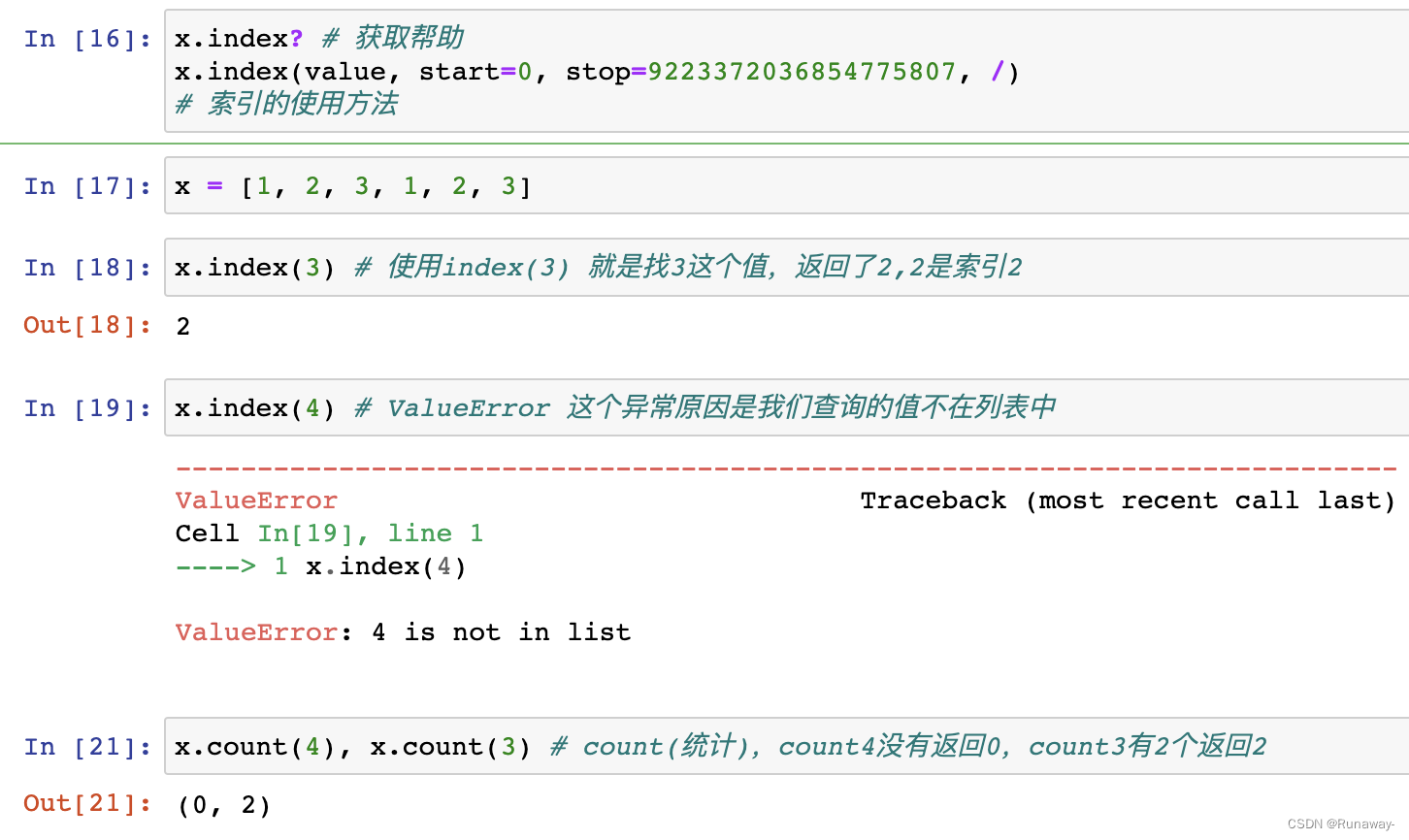
索引,也叫下标
-
正索引:从左至右,从0开始,为列表中每一个元素编号
- 如果列表有元素,索引范围[0, 长度-1]
-
负索引:从右至左,从-1开始
- 如果列表有元素,索引范围[-长度, -1]
-
正、负索引不可以超界,否则引发异常IndexError
-
为了理解方便,可以认为列表是从左至右排列的,左边是头部,右边是尾部,左边是下界,右边是
上界 -
列表通过索引访问,list[index] ,index就是索引,使用中括号访问
使用索引定位访问元素的时间复杂度为O(1),这是最快的方式,是列表最好的使用方式。
查询
- index(value,[start,[stop]])
- 通过值value,从指定区间查找列表内的元素是否匹配
- 匹配第一个就立即返回索引
- 匹配不到,抛出异常ValueError
- count(value)
- 返回列表中匹配value的次数
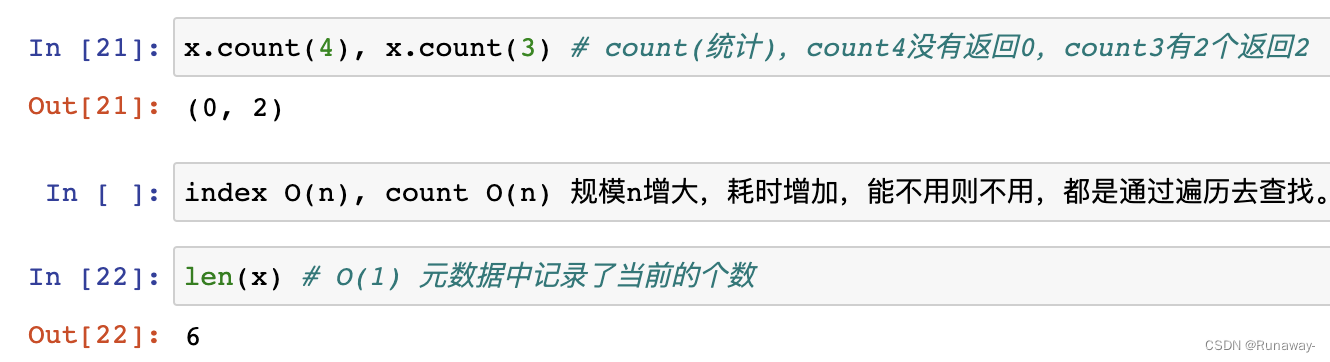
- 时间复杂度
- index和count方法都是O(n)
- 随着列表数据规模的增大,而效率下降
增加单个元素
- append(object) -> None
- 列表尾部追加元素,返回None
- 返回None就意味着没有新的列表产生,就地修改
- 定位时间复杂度是O(1)
- insert(index, object) -> None
- 在指定的索引index处插入元素object
- 返回None就意味着没有新的列表产生,就地修改
- 定位时间复杂度是O(1)
- 索引能超上下界吗?
- 超越上界,尾部追加
- 超越下界,头部追加
增加多个元素
- extend(iteratable) -> None
- 将可迭代对象的元素追加进来,返回None
- 就地修改,本列表自身扩展
+ -> list- 连接操作,将两个列表连接起来,产生新的列表,原列表不变
- 本质上调用的是魔术方法__add__()方法
* -> list- 重复操作,将本列表元素重复n次,返回新的列表


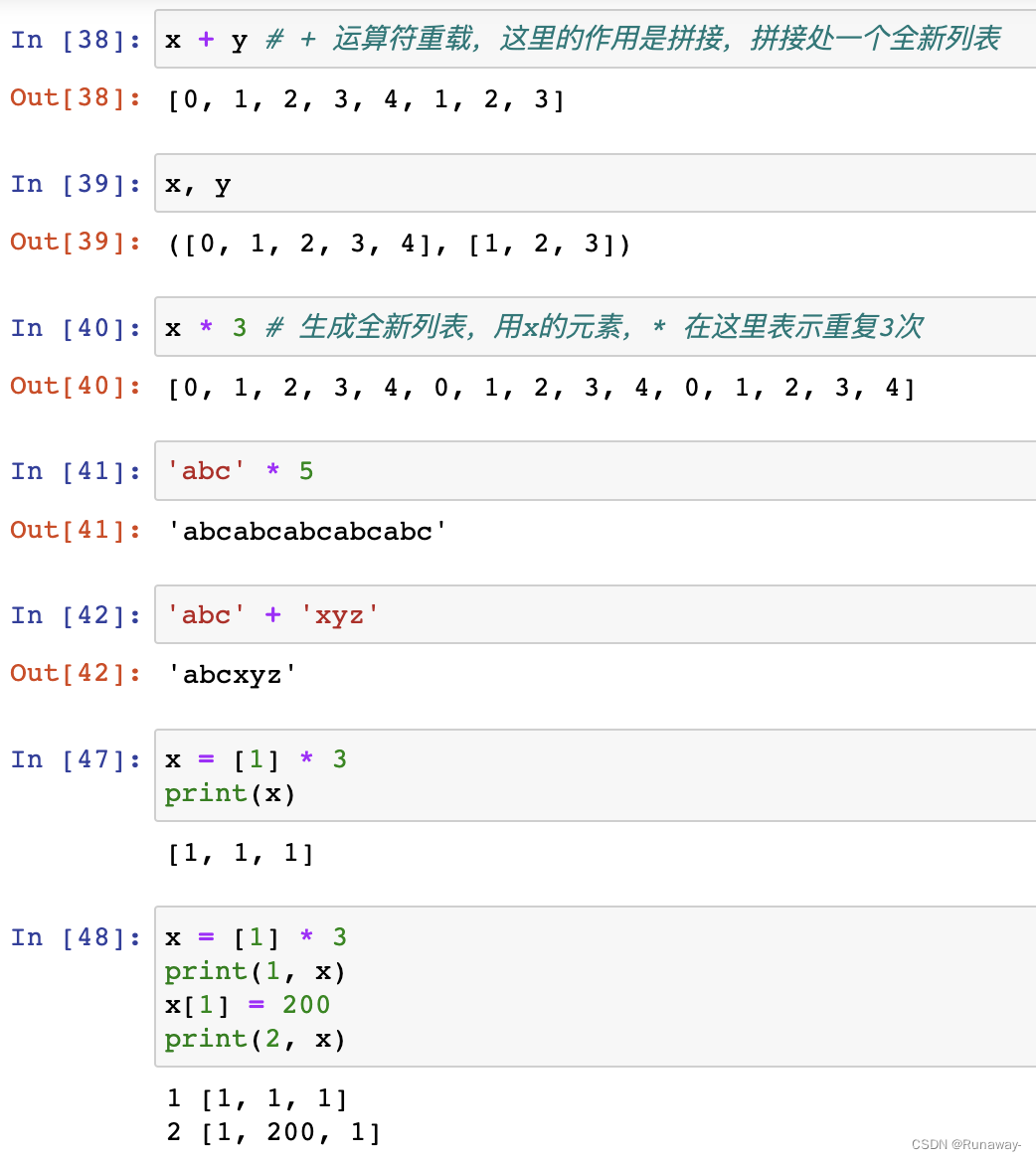
- 重复操作,将本列表元素重复n次,返回新的列表
删除
- remove(value) -> None
- 从左至右查找第一个匹配value的值,找到就移除该元素,并返回None,否则ValueError
- 就地修改
- pop([index]) -> item
- 不指定索引index,就从列表尾部弹出一个元素
- 指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
- 效率?指定索引的的时间复杂度?不指定索引呢?
- 需要查看弹出的位置,尾部弹效率高,没有影响,头部弹和中间弹都会引起数据挪动。
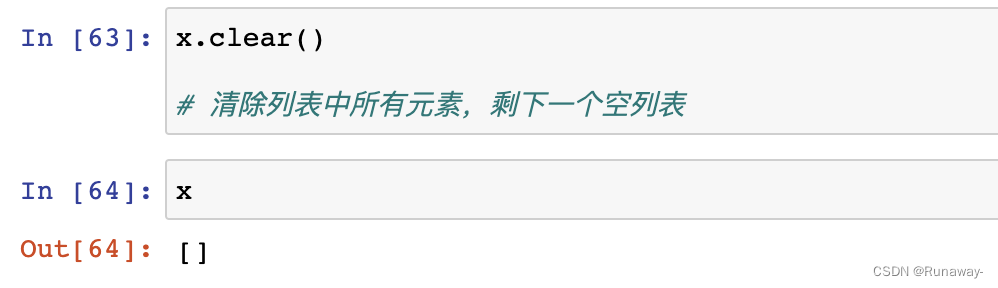
- clear() -> None
- 清除列表所有元素,剩下一个空列表
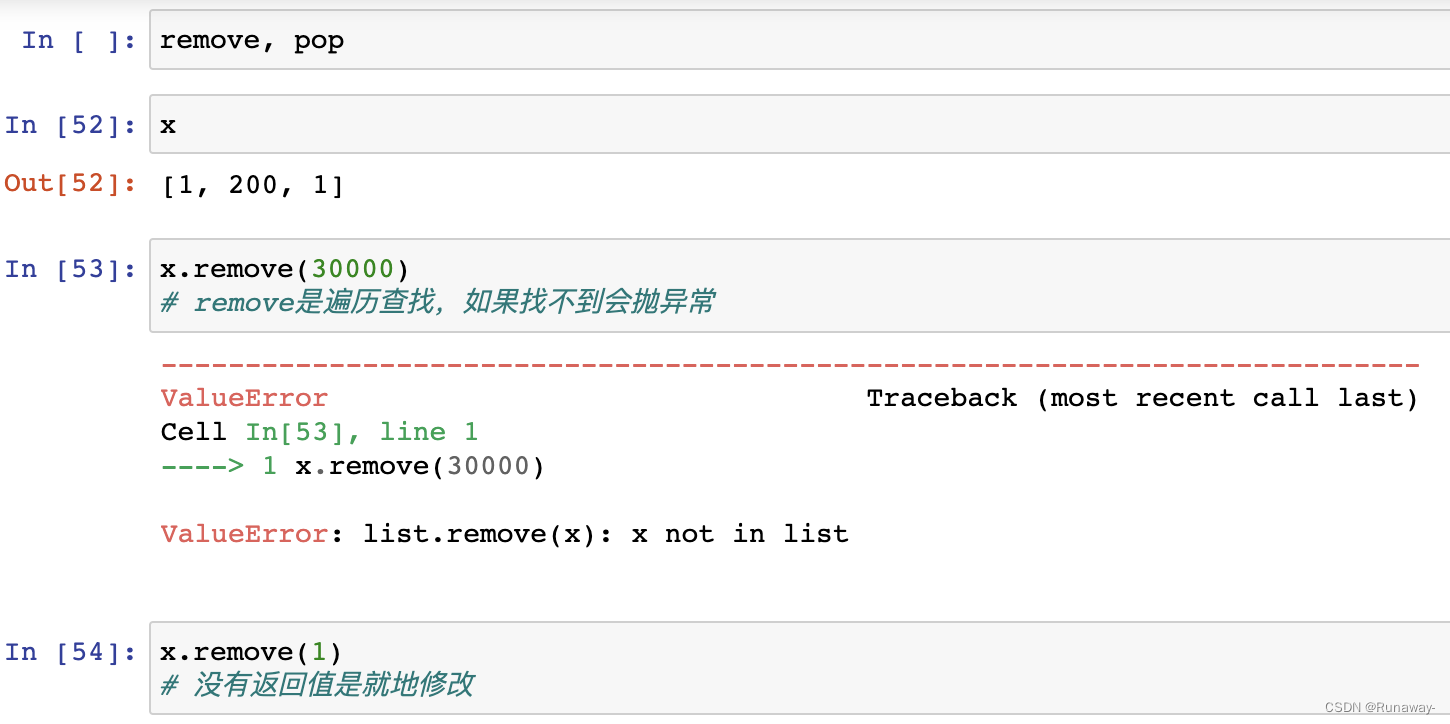
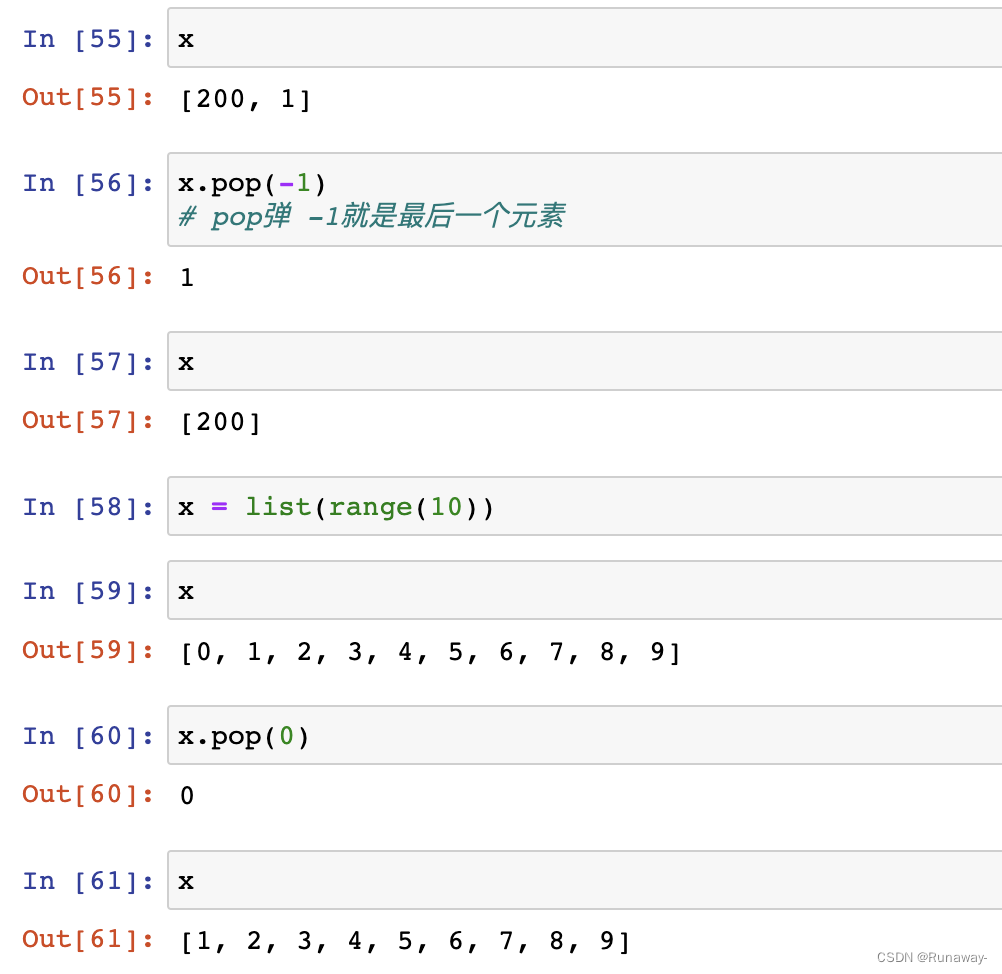
pop() 不给值,缺省值是-1也就是最后一个元素,pop的效率要看从哪弹,从尾部弹肯定效率高,从头部弹就效率不高了因为会发生元素的挪动。
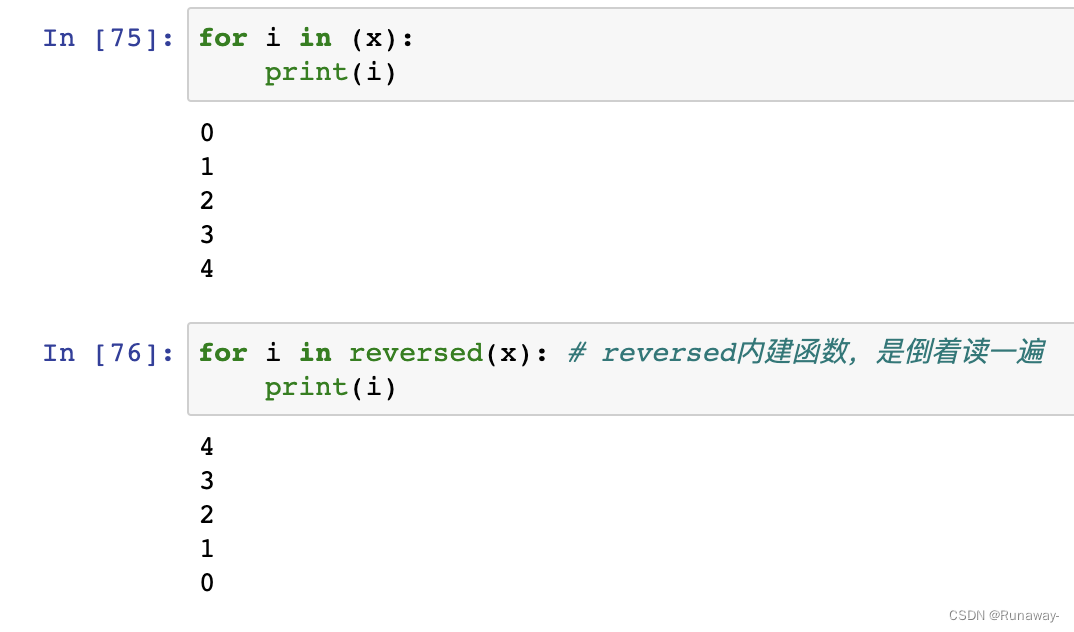
反转
- reverse() -> None
- 将列表元素反转,返回None
- 就地修改
这个方法最好不用,可以倒着读取,都不要反转。
排序
- sort(key=None, reverse=False) -> None
- 对列表元素进行排序,就地修改,默认升序
- reverse为True,反转,降序
- key一个函数,指定key如何排序,lst.sort(key=function)