本章介绍Ceph的一致性检查工具Scrub机制。首先介绍数据校验的基本知识,其次介绍Scrub的基本概念,然后介绍Scrub的调度机制,最后介绍Scrub具体实现的源代码分析。
1. 端到端的数据校验
在存储系统中可能会发生数据静默损坏(Silent Data Corruption),这种情况的发生大多是由于数据的某一位发生异常反转(Bit Error Rate)。
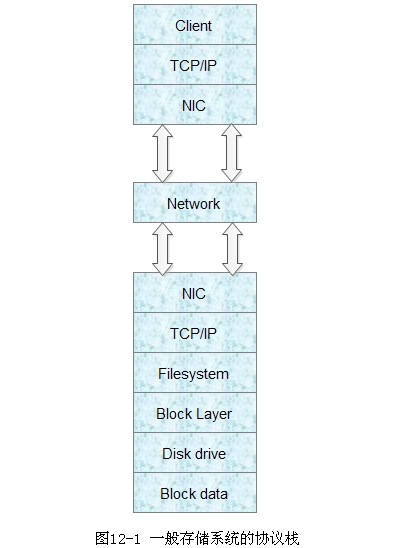
下图12-1是一般存储系统的协议栈,数据损坏的情况会发生在系统的所有模块中:
-
硬件错误,例如内存、CPU、网卡等;
-
数据传输过程中的信噪干扰,例如SATA、FC等协议;
-
固件bug,例如RAID控制器、磁盘控制器、网卡等;
-
软件bug,例如操作系统内核的bug,本地文件系统的bug,SCSI软件模块的bug等。
在传统的高端磁盘阵列中,一般采用端到端的数据校验实现数据的一致性。所谓端到端的数据校验,指客户端(应用层)在写入数据时,为每个数据块都计算一个CRC校验信息,并将这个校验信息和数据块发送至磁盘(Disk)。磁盘在接收到数据包之后,会重新计算校验信息,并和接收到的校验信息作对比。如果不一致,那么就认为在整个IO路径上存在错误,返回IO操作失败;如果校验成功,就把数据校验信息和数据保存在磁盘上。同样,在数据读取时,客户端再获取数据块和磁盘读取校验信息时,也需要再次检查是否一致。
通过这种方法,应用层可以很明确地知道一次IO请求的数据是否一致。如果操作成功,那么磁盘上的数据必然是正确的。
这种方式在不影响IO性能或者影响比较小的情况下,可以提高数据读写的完整性。但这种方式也有一些缺点:
-
无法解决目的地址错误导致的数据损坏问题;
-
端到端的解决方案需要在整个IO路径上附加校验信息。现在的IO协议栈涉及的模块比较多,每个模块都附加这种校验信息实现起来比较困难。
由于这种实现方式对Ceph的IO性能影响比较大,所以Ceph并没有实现端到端的数据校验,而是实现Ceph Scrub机制,采用一种通过在后台扫描的方案来解决Ceph一致性检查。
2. Scrub概念介绍
Ceph在内部实现了一致性检查的一个工具: Ceph Scrub。其原理为:通过对比各个对象副本的数据和元数据,完成副本一致性检查。
这种方法的优点是后台可以发现由于磁盘损坏而导致的数据不一致现象。缺点是发现的时机往往比较滞后。
Scrub按照扫描的内容分为两种方式:
-
一种叫做Scrub,它仅仅通过对比对象各副本的元数据,来检查数据的一致性。由于只检查元数据,读取数据量和计算量都比较小,是一种比较轻度的检查。
-
另一种叫deep-scrub,它进一步检查对象的数据内容是否一致,实现了深度扫描,几乎要扫描磁盘上的所有数据并计算crc32校验值,因此比较耗时,占用系统资源更多。
Scrub按照扫描的方式分为两种:
-
在线扫描: 不影响系统正常的业务;
-
离线扫描: 需要整个系统暂停或者冻结
Ceph的Scrub功能实现了在线检查,即不中断系统当前读写请求,客户端可以继续完成读写访问。整个系统并不会暂停,但是后台正在进行Scrub的对象要被锁定暂时阻止访问,直到该对象完成Scrub操作后才能解锁允许访问。
3. Scrub调度
Scrub的调度解决了一个PG何时启动Scrub扫描机制。主要有以下方式:
-
手动立即启动执行扫描;
-
在后台设置一定的时间间隔,按照时间间隔的时间来启动。比如默认时间为一天执行一次;
-
设置启动的时间段。一般设定一个系统负载比较轻的时间段来执行Scrub操作。
3.1 相关数据结构
在类PG里有下列与Scrub相关的数据结构(src/osd/osd.h):
class OSDService{
...
public:
Mutex sched_scrub_lock; //Scrub相关变量的保护锁
int scrubs_pending; //资源预约已经成功,正等待Scrub的PG
int scrubs_active; //正在进行Scrub的PG
set<ScrubJob> sched_scrub_pg; //PG对应的所有ScrubJob列表
};结构体ScrubJob封装了一个PG的Scrub任务相关的参数:
struct ScrubJob {
//Scrub对应的PG
spg_t pgid;
//Scrub任务的调度时间,如果当前负载比较高,或者当前的时间不在设定的Scrub工作时间段
//内,就会延迟调度
utime_t sched_time;
//调度时间的上限,过了该时间必须进行Scrub操作,而不受系统负载和Scrub时间段的限制
utime_t deadline;
}3.2 Scrub的调度实现
在OSD的初始化函数OSD::init()中,注册了一个定时任务:
tick_timer_without_osd_lock.add_event_after(cct->_conf->osd_heartbeat_interval, new C_Tick_WithoutOSDLock(this));该定时任务每隔osd_heartbeat_interval时间段(默认为1秒),就会触发定时器的回调函数OSD::tick_without_osd_lock(),处理过程的函数调用关系如下图12-2所示:
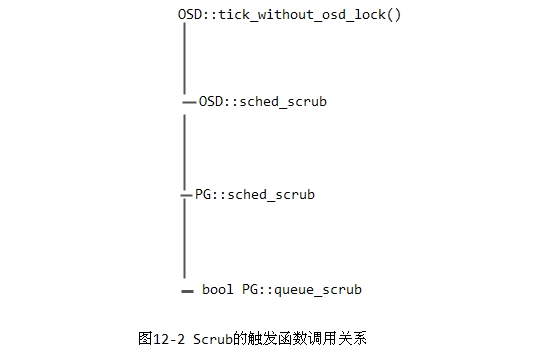
以上函数实现了PG的Scrub调度工作。下面将介绍处理过程中关键的两个函数OSD::sched_scrub()和PG::sched_scrub()函数的实现。
3.2.1 OSD::sched_scrub()函数
本函数用于控制一个PG的scrub过程启动时机,具体过程如下:
1) 调用函数can_inc_scrubs_pending()来检查是否有配额允许PG开始启动Scrub操作。变量scrubs_pending记录了已经完成资源预约正在等待Scrub的PG的数量,变量scrubs_active记录了正在进行Scrub检查的PG数量,其二者的数量之和不能超过系统配置参数cct->_conf->osd_max_scrubs的值。该值设置了同时允许Scrub的最大的PG数量。
2) 调用函数scrub_time_permit()检查是否在允许的时间段内。如果cct->_conf->osd_scrub_begin_hour小于cct->_conf->osd_scrub_end_hour,当前时间必须在二者设定的时间范围之间才允许。如果cct->_conf->osd_scrub_begin_hour大于等于cct->_conf->osd_scrub_end_hour,当前时间在二者设定的时间范围之外才允许。
3) 调用函数scrub_load_below_threshold()检查当前的系统负载是否允许。函数getloadavg()获取最近1分钟、5分钟、15分钟的系统负载:
a) 如果最近1分钟的负载小于cct->_conf->osd_scrub_load_threshold的设定值,就允许执行;
b) 如果最近一分钟的负载小于daily_loadavg的值,并且最近1分钟负载小于最近15分钟负载,就允许执行;
4) 获取第一个等待执行Scrub操作的ScrubJob列表,如果它的scrub.sched_time大于当前时间now值,说明时间不到,就跳过该PG先执行下一个任务。
5) 获取该PG对应的PG对象,如果该PG的pgbackend支持Scrub,并且处于active状态:
a) 如果scrub.deadline小于now值,也就是已经超过最后的期限,必须启动Scrub操作;
b) 或者此时time_permit并且load_is_low,也就是时间和负载都允许;
在上述两种情况下,调用函数pg->sched_scrub()来执行Scrub操作。
3.2.2 PG::sched_scrub()函数
本函数实现了对执行Scrub任务时相关参数的设置,并完成了所需资源的预约。其处理过程如下:
1) 首先检查PG的状态,必须是主OSD,并且处于active和clean状态,并且没有正在进行Scrub操作;
2) 设置deep_scrub_inerval值: 如果该PG所在的Pool选项中没有设置该值,就设置为系统配置参数cct->_conf->osd_deep_scrub_interval的值;
3) 检查是否启动deep_scrub,如果当前时间大于info.history.last_deep_scrub_stamp与deep_scrub_interval之和,就启动deep_scrub操作;
4) 如果scrubber.must_scrub的值为true,为用户手动强制启动deep_scrub操作。如果该值为false,则需系统自动以一定的概率来启动deep_scrub操作,具体实现就是:自动产生一个随机数,如果该随机数小于cct->_conf->osd_deep_scrub_randomize_ratio,就启动deep_scrub操作。
5) 决定最终是否启动deep_scrub,在步骤3)和步骤4)中只要有一个设置好,就启动deep_scrub操作;
6) 如果osdmap或者pool中带有不支持deep_scrub的标记,就设置time_for_deep为false,不启动deep_scrub操作;
7) 如果osdmap或者pool中带有不支持Scrub的标记,并且也没有启动deep_scrub操作则返回并退出;
8) 如果cct->_conf->osd_scrub_auto_repair设置了自动修复,并且pgbackend也支持,而且是deep_scrub操作,则进行如下判断过程:
a) 如果用户设置了must_repair,或者must_scrub,或者must_deep_scrub,说明这次Scrub操作是用户触发的,系统尊重用户的选择,不会自动设置scrubber.auto_repair的值为true;
b) 否则,系统就设置scrubber.auto_repair的值为true来自动进行修复。
9) Scrub过程和Recovery过程类似,都需要耗费系统大量资源,需要去PG所在的OSD上预约资源。如果scrubber.reserved的值为false,还没有完成资源的预约,需进行如下操作:
a) 把自己加入到scrubber.reserved_peers中;
b) 调用函数scrub_reserve_replicas(),向OSD发送CEPH_OSD_OP_SCRUB_RESERVE消息来预约资源;
c) 如果scrubber.reserved_peers.size()等于acting.size(),表明所有的从OSD资源预约成功,把PG设置为PG_STATE_DEEP_SCRUB状态。调用函数queue_scrub()把该PG加入到工作队列op_wq中,触发Scrub任务开始执行;
4. Scrub的执行
Scrub的具体执行过程大致如下:通过比较对象各个OSD上副本的元数据和数据,来完成元数据和数据的校验。其核心处理流程在函数PG::chunky_scrub()里控制完成。
4.1 相关数据结构
Scrub操作相关的主要数据结构有两个:一个是Scrubber控制结构,它相当于一次Scrub操作的上下文,控制一次PG的操作过程。另一个是ScrubMap保存需要比较的对象各个副本的元数据和数据的摘要信息。
1) Scrubber 结构体Scrubber用来控制一个PG的Scrub的过程(src/osd/pg.h):
// -- scrub --
struct Scrubber {
// 元数据
set<pg_shard_t> reserved_peers; //资源预约的shard
bool reserved, reserve_failed; //是否预约资源,预约资源是否失败
epoch_t epoch_start; //开始Scrub操作的epoch
// common to both scrubs
bool active; //Scrub是否开始
/*
* 当PG有snap_trim操作时,如果检查Scrubber处于active状态,说明正在进行Scrub操作,那么
* snap_trim操作暂停,设置queue_snap_trim的值为true。当PG完成Scrub任务后,如果queue_snap_trim
* 的值为true,就把PG添加到相应的工作队列里,继续完成snap_trim操作
*/
bool queue_snap_trim;
int waiting_on; //等待的副本计数
set<pg_shard_t> waiting_on_whom; //等待的副本
int shallow_errors; //轻度扫描错误数
int deep_errors; //深度扫描错误数
int fixed; //已修复的对象数
ScrubMap primary_scrubmap; //主副本的ScrubMap
map<pg_shard_t, ScrubMap> received_maps; //接收到的从副本的ScrubMap
OpRequestRef active_rep_scrub;
utime_t scrub_reg_stamp; //stamp we registered for
// For async sleep
bool sleeping = false;
bool needs_sleep = true;
utime_t sleep_start;
// flags to indicate explicitly requested scrubs (by admin)
bool must_scrub, must_deep_scrub, must_repair;
// Priority to use for scrub scheduling
unsigned priority;
// this flag indicates whether we would like to do auto-repair of the PG or not
bool auto_repair;
// Maps from objects with errors to missing/inconsistent peers
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator> missing; //扫描出的缺失对象
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator> inconsistent; //扫描出的不一致对象
/*
* Map from object with errors to good peers
* 如果所有副本对象中有不一致的对象,authoritative记录了正确对象所在的OSD
*/
map<hobject_t, list<pair<ScrubMap::object, pg_shard_t> >, hobject_t::BitwiseComparator> authoritative;
// Cleaned map pending snap metadata scrub
ScrubMap cleaned_meta_map;
// digest updates which we are waiting on
int num_digest_updates_pending; //等待更新digest的对象数
// chunky scrub
hobject_t start, end; //扫描对象列表的开始和结尾
eversion_t subset_last_update; //扫描对象列表中最新的版本号
// chunky scrub state
enum State {
INACTIVE,
NEW_CHUNK,
WAIT_PUSHES,
WAIT_LAST_UPDATE,
BUILD_MAP,
WAIT_REPLICAS,
COMPARE_MAPS,
WAIT_DIGEST_UPDATES,
FINISH,
} state;
std::unique_ptr<Scrub::Store> store;
bool deep; //是否为深度扫描
uint32_t seed; //计算crc32校验码的种子
list<Context*> callbacks;
};2) ScrubMap
数据结构ScrubMap保存准备校验的对象以及相应的校验信息(src/osd/osd_types.h):
struct ScrubMap {
struct object {
map<string,bufferptr> attrs; //对象的属性
set<snapid_t> snapcolls; //该对象所有的snap序号
uint64_t size; //对象的size
__u32 omap_digest; //omap的crc32c校验码
__u32 digest; //对象数据的crc32校验码
uint32_t nlinks; //snap对象(clone对象)对应的snap数量
bool negative:1;
bool digest_present:1; //是否计算了数据的校验码标志
bool omap_digest_present:1; //是否有omap的校验码标志
bool read_error:1; //读对象的数据出错标志
bool stat_error:1; //调用stat获取对象的元数据出错标志
bool ec_hash_mismatch:1; //
bool ec_size_mismatch:1;
};
bool bitwise; // ephemeral, not encoded
//需要校验的对象(hobject) -> 校验信息(object)的映射
map<hobject_t,object, hobject_t::ComparatorWithDefault> objects;
eversion_t valid_through;
eversion_t incr_since;
};内部类object用来保存对象需要校验的信息,包括以下5个方面:
-
对象的大小(size)
-
对象的属性(attrs)
-
对象omap的校验码(digest)
-
对象数据的校验码(digest)
-
对象所有clone对象的快照序号
4.2 Scrub的控制流程
Scrub的任务由OSD的工作队列OpWq来完成,调用对应的处理函数pg->scrub(handle)来执行。
void PG::scrub(epoch_t queued, ThreadPool::TPHandle &handle){
...
chunky_scrub(handle);
}PG::scrub()函数最终调用PG::chunky_scrub()函数来实现。PG::chunky_scrub()函数控制了Scrub操作状态转移和核心处理过程。
具体分析过程如下:
1) Scrubber的初始状态为PG::Scrubber::INACTIVE,该状态的处理如下
a) 设置scrubber.epoch_start的值为info.history.same_interval_since;
b) 设置scrubber.active的值为true
c) 设置状态scrubber.state的值为PG::Scrubber::NEW_CHUNK
d) 根据peer_features,设置scrubber.seed的类型,这个seed是计算crc32的初始化哈希值
2) PG::Scrubber::NEW_CHUNK状态的处理如下
a) 调用get_pgbackend()->objects_list_partial()函数从start对象开始扫描一组对象,一次扫描的对象数量在如下两个配置参数之间:cct->_conf->osd_scrub_chunk_min(默认值为5)和cct->_conf->osd_scrub_chunk_max(默认值为25)
b) 计算出对象的边界。相同的对象具有相同的哈希值。从列表后面开始查找哈希值不同的对象,从该地方划界。这样做的目的是把一个对象的所有相关对象(快照对象、回滚对象)划分在一次扫描校验过程中;
c) 调用函数_range_available_for_scrub()检查列表中的对象,如果有被阻塞的对象,就设置done的值为true,退出PG本次Scrub过程;
d) 根据pg_log计算start到end区间对象最大的更新版本号,这个最新版本号设置在scrubber.subset_last_update里;
e) 调用函数_request_scrub_map()向所有副本发送消息,获取相应ScrubMap的校验信息;
f) 设置状态为PG::Scrubber::WAIT_PUSHES。
3) PG::Scrubber::WAIT_PUSHES状态的处理如下
a) 如果active_pushes的值为0,设置状态为PG::Scrubber::WAIT_LAST_UPDATE,进入下一个状态处理;
b) 如果active_pushes不为0,说明该PG正在进行Recovery操作。设置done的值为true,直接结束。在进入chunky_scrub()时,PG应该处于CLEAN状态,不可能有Recovery操作,这里Recovery操作可能是上次进行chunky_scrub()操作后的修复操作;
4) PG::Scrubber::WAIT_LAST_UPDATE状态的处理如下:
a) 如果last_update_applied的值小于scrubber.subset_last_update的值,说明虽然已经把操作写入了日志,但是还没有应用到对象中。由于Scrub操作后面的步骤有对象的读操作,所以需要等待日志应用完成。设置done的值为true结束本次PG的Scrub过程;
b) 否则就设置状态为PG::Scrubber::BUILD_MAP。
5) PG::Scrubber::BUILD_MAP状态的处理如下:
a) 调用函数build_scrub_map_chunk()构造主OSD上对象的ScrubMap结构;
b) 如果构造成功,计数scrubber.waiting_on的值减1,并从队列中删除scrubber.waiting_on_whom,则相应的状态设置为PG::Scrubber.WAIT_REPLICAS。
6) PG::Scrubber::WAIT_REPLICAS状态的处理如下:
a) 如果scrubber.waiting_on不为零,说明有replica请求没有回答,设置done的值为true,退出并等待;
b) 否则,进入PG::Scrubber::CAMPARE_MAPS状态;
7) PG::Scrubber::COMPARE_MAPS状态的处理如下:
a) 调用函数scrub_compare_maps()比较各副本的校验信息;
b) 将参数scrubber.start的值更新为scrubber.end。
c) 调用函数requeue_ops(),把由于Scrub而阻塞的读写操作重新加入操作队列里执行;
d) 状态设置为PG::Scrubber::WAIT_DIGEST_UPDATES;
8) PG::Scrubber::WAIT_DIGEST_UPDATES状态的处理如下:
a) 如果有scrubber.num_digest_updates_pending等待,等待更新数据的digest或者omap的digest;
b) 如果scrubber.end小于hobject_t::get_max(),本PG还有没有Scrub操作完成的对象,设置状态scrubber::state为PG::Scrubber::NEW_CHUNK,继续把PG加入到osd->scrub_wq中;
c) 否则,设置状态为PG::Scrubber::FINISH值;
9) PG::Scrubber::FINISH状态的处理如下:
a) 调用函数scrub_finish()来设置相关的统计信息,并触发修复不一致的对象;
b) 设置状态为PG::Scrubber::INACTIVE;
4.3 构建ScrubMap
构建ScrubMap有多个函数实现,下面分别介绍。
1. build_scrub_map_chunk()函数
函数build_scrub_map_chunk()用于构建从start到end之间的所有对象的校验信息并保存在ScrubMap结构中:
int PG::build_scrub_map_chunk(
ScrubMap &map,
hobject_t start, hobject_t end, bool deep, uint32_t seed,
ThreadPool::TPHandle &handle);处理过程分析如下:
1) 设置map.valid_through的值为info.last_update;
2) 调用get_pgbackend()->objects_list_range()函数列出所有的start和end范围内的对象,ls队列存放head和snap对象,rollback_obs队列存放用来回滚的ghobject_t对象;
3) 调用函数get_pgbackend()->be_scan_list()扫描对象,构建ScrubMap结构;
4) 调用函数_scan_rollback_obs()来检查回滚对象:如果对象的generation小于last_rollback_info_trimmed_to_applied值,就删除该对象;
5) 调用_scan_snaps()来修复SnapMapper里保存的snap信息;
2. _scan_snaps()
函数_scan_snaps()扫描head对象保存的snap信息和SnapMapper中保存的该对象的snap信息是否一致。它以前者保存的对象snap信息为准,修复SnapMapper中保存的对象snap信息。
void PG::_scan_snaps(ScrubMap &smap);具体实现过程为:对于ScrubMap里的每一个对象循环做如下操作:
1) 如果对象的hoid.snap的值小于CEPH_MAXSNAP的值,那么该对象是snap对象,从o.attrs[OI_ATTR]里获取object_info_t信息;
2) 检查oi的snaps。如果oi.snaps.empty()为0,设置nlinks等于1;如果io.snaps.size()为1,设置nlinks等于2;否则设置nlinks等于3;
3) 从oi获取oi_snaps,从snap_mapper获取cur_snaps,比较两个snap信息,以oi的信息为准:
a) 如果函数snap_mapper.get_snaps(hoid, &cur_snaps)的结果为-ENOENT,就把信息添加到snap_mapper里;
b) 如果信息不一致,先删除snap_mapper里不一致的对象,然后把该对象的snap信息添加到snap_mapper里。
3. be_scan_list()
函数be_scan_list()用于构建ScrubMap中对象的校验信息:
void PGBackend::be_scan_list(
ScrubMap &map, const vector<hobject_t> &ls, bool deep, uint32_t seed,
ThreadPool::TPHandle &handle);具体处理过程就是循环扫描ls向量中的对象:
1) 调用store->stat()获取对象的stat信息:
a) 如果获取成功,设置o.size的值等于st.st_size,并调用store->getattrs()把对象的attr信息保存在o.attrs里;
b) 如果stat返回结果r为-ENOENT,就直接跳过该对象(该对象在本OSD上可能缺失,在后面比较结果时会检查出来);
c) 如果stat返回结果r为-EIO,就设置o.stat_error的值为true;
2) 如果deep的值为true,调用函数be_deep_scrub()进行深度扫描,获取对象的omap和data的digest信息;
4. be_deep_scrub()
函数be_deep_scrub()实现对象的深度扫描:
void ReplicatedBackend::be_deep_scrub(
const hobject_t &poid, //深度扫描的对象
uint32_t seed, //crc32的种子
ScrubMap::object &o, //保存对应的校验信息
ThreadPool::TPHandle &handle);实现过程分析如下:
1) 设置data和omap的bufferhash的初始值都为seed;
2) 循环调用函数store->read()读取对象的数据,每次读取长度为配置参数cct->_conf->osd_deep_scrub_stride(512k),并通过bufferhash计数crc32校验值。如果中间出错(r==-EIO),就设置o.read_error的值为true。最后设置o.digest为计算出crc32的校验值,设置o.digest_present的值为true;
3) 调用函数store->omap_get_header()获取header,迭代获取对象的omap的key-value值,计算header和key-value的digest信息,并设置在o.omap_digest中,标记o.omap_digest_present的值为true;
综上可知,通过函数be_scan_list()来获取对象的元数据,通过be_deep_scrub()函数获取对象的数据和omap的digest信息保存在ScrubMap结构中;
4.4 从副本处理
当从副本接收到主副本发送来的MOSDRepScrub类型消息,用于获取对象的校验信息时,就调用函数replica_scrub()来完成。
void PG::replica_scrub(
OpRequestRef op,
ThreadPool::TPHandle &handle);函数replica_scrub()具体实现如下:
1) 首先确保scrubber.active_rep_scrub不为空;
2) 检查如果msg->map_epoch的值小于info.history.same_interval_since的值,就直接返回。在这里从副本直接丢弃掉过时的MOSDRepScrub请求;
3) 如果last_update_applied的值小于msg->scrub_to的值,也就是从副本上完成日志应用的操作落后于主副本scrub操作的版本,必须等待它们一致。把当前的op操作保存在scrubber.active_rep_scrub中等待;
4) 如果active_pushes大于0,表明有Recovery操作正在进行,同样把当前的op操作保存在scrubber.active_rep_scrub中等待;
5) 否则就调用函数build_scrub_map_chunk()来构建ScrubMap,并发送给主副本。
当等待的本地操作应用完成之后,在函数ReplicatedPG::op_applied()检查,如果scrubber.active_rep_scrub不为空,并且该操作的版本等于msg->scrub_to,就会把保存的op操作重新放入osd->op_wq请求队列,继续完成该请求。
4.5 副本对比
当对象的主副本和从副本都完成了校验信息的构建,并保存在相应的结构ScrubMap中,下一步就是对比各个副本的校验信息来完成一致性检查。首先通过对象自身的信息选出一个权威的对象,然后用权威对象和其他对象做比较来检验。下面介绍用于比较的函数。
4.5.1 scrub_compare_maps()
函数scrub_compre_maps()实现比较不同的副本信息是否一致,处理流程如下:
void PG::scrub_compare_maps();1) 首先确保acting.size()大于1,如果该PG只有一个OSD,则无法比较;
2) 把actingbackfill对应OSD的ScrubMap放置到maps中;
3) 调用函数be_compare_scrubmaps()来比较各个副本的对象,并把对象完整的副本所在shard保存在authoritative中;
4) 调用_scrub()函数继续比较snap之间对象的一致性;
4.5.2 be_compare_scrubmaps()
函数be_compare_scrubmaps()用来比较对象各个副本的一致性,其具体处理过程分析如下:
void PGBackend::be_compare_scrubmaps(
const map<pg_shard_t,ScrubMap*> &maps,
bool repair,
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator> &missing,
map<hobject_t, set<pg_shard_t>, hobject_t::BitwiseComparator> &inconsistent,
map<hobject_t, list<pg_shard_t>, hobject_t::BitwiseComparator> &authoritative,
map<hobject_t, pair<uint32_t,uint32_t>, hobject_t::BitwiseComparator> &missing_digest,
int &shallow_errors, int &deep_errors,
Scrub::Store *store,
const spg_t& pgid,
const vector<int> &acting,
ostream &errorstream);1) 首先构建master set,也就是所有副本OSD上对象的并集;
2) 对master set中的每一个对象进行如下操作:
a) 调用函数be_select_auth_object()选择出一个具有权威对象的副本auth,如果没有选择出权威对象,变量shallow_errors加1来记录这种错误;
b) 调用函数be_compare_scrub_objects(),比较各个shard上的对象和权威对象:分别对data的digest、omap的omap_digest和属性进行对比:
* 如果结果为clean,表明该对象和权威对象的各项比较完全一致,就把该shard添加到auth_list列表中;
* 如果结果不为clean,就把该对象添加到cur_inconsistent列表中,分别统计shallow_errors和deep_errors的值;
* 如果该对象在该shard上不存在,添加到cur_missing列表中,统计shallow_errors的值;
c) 检查该对象所有的比较结果: 如果cur_missing不为空,就添加到missing队列;如果有cur_inconsistent对象,就添加到inconsistent对象里;如果该对象有不完整的副本,就把没有问题的记录放在authoritative中;
d) 如果权威对象object_info里记录的data的digest和omap的omap_digest和实际扫描出数据计算的结果不一致,update的模式就设置为FORCE,强制修复。如果object_info里没有data的digest和omap的digest,修复的模式update设置为MAYBE。
e) 最后检查,如果update模式为FORCE,或者该对象存在的时间age大于配置参数g_conf->osd_deep_scrub_update_digest_min_age的值,就加入missing_digest列表中;
4.5.3 be_select_auth_object()
函数be_select_auth_object()用于在各个OSD上副本对象中,选择出一个权威的对象:auth_obj对象。其原理是根据自身所带的冗余信息来验证自己是否完整,具体流程如下:
map<pg_shard_t, ScrubMap *>::const_iterator
PGBackend::be_select_auth_object(
const hobject_t &obj,
const map<pg_shard_t,ScrubMap*> &maps,
object_info_t *auth_oi,
map<pg_shard_t, shard_info_wrapper> &shard_map,
inconsistent_obj_wrapper &object_error);1) 首先确认该对象的read_error和stat_error没有设置,也就是在获取对象的数据和元数据的过程中没有出错,否则就直接跳过;
2) 确认获取的属性OI_ATTR值不为空,并将数据结构object_info_t正确解码,就设值当前的对象为auth_obj对象;
3) 验证保存在object_info_t中的size值和扫描获取对象的size值是否一致,如果不一致,就继续查找一个更好的auth_obj对象;
4) 如果是replicated类型的PG,验证在object_info_t里保存的data和omap的digest值是否和扫描过程计算出的值一致。如果不一致,就继续查找一个更好的auth_obj对象;
5) 如上述都一致,直接终止循环,当前已经找到满意的auth_obj对象;
由上述的选择过程可知,选中一个权威对象的条件如下:
-
步骤1),2)两点条件是基础,对象的数据和属性能正确读取;
-
步骤3),4)是利用了object_info_t中保存的对象size,以及omap和data的digest的冗余信息。用这些信息和对象扫描读取的数据计算出的信息比较来验证。
4.5.4 _scrub()
函数_scrub()检查对象和快照对象之间的一致性:
void ReplicatedPG::_scrub(
ScrubMap &scrubmap,
const map<hobject_t, pair<uint32_t, uint32_t>, hobject_t::BitwiseComparator> &missing_digest);如果pool有cache pool层,那么就允许拷贝对象有不一致的状态,因为有些对象可能还存在于cache pool中没有被刷回。通过函数pool.info.allow_incomplete_clones()来确定上述情况。
其实代码比较复杂,下面通过举例来说明其实现基本过程.
例12-1 _scrub()函数实现过程举例,如下表12-1所示

_scrub()实现过程说明如下:
1) 对象obj1 snap1为快照对象,就应该有head或者snapdir对象。但是该快照对象没有对应的head或者snapdir对象,那么该对象被标记为unexpected对象;
2) 对象obj2 head是一个head对象,这是预期的对象。通过head对象,获取snapset的clones列表为[6,4,2,1]
3) 检查对象obj2 snap7并没有在对象obj2的snapset的clones列表只能够,为异常对象;
4) 对象obj2的快照对象snap6,在snapset的clones列表中;
5) 对象obj2的快照对象snap4,在snapset的clones列表中;
6) 当遇到obj3 head对象时,预期的对象obj2中应该还有快照对象snap2和snap1为缺失的对象。继续获取snap3的snapset的clones值为列表[3,1];
7) 对象obj3的快照对象snap3和预期对象一致;
8) 对象obj3的快照对象snap1和预期对象一致;
9) 对象obj4的snapdir对象,符合预期。获取该对象的snapset的clones列表为[4]。
10) 扫描的对象列表结束了,但是预期对象为obj4的快照对象snap4,对象obj4 snap4缺失;
目前对于expected的对象和unexpected的对象,都只是在日志中标记出来,并不做进一步处理。
最后对于那些其他都正确但对象的digest不正确的数据对象,也就是missing_digest中需要更新digest的对象,发送更新digest请求。
4.6 结束Scrub过程
scrub_finish()函数用于结束Scrub过程,其处理过程如下:
void PG::scrub_finish();1) 设置了相关PG的状态和统计信息;
2) 调用函数scrub_process_inconsistent用于修复scrubber里标记的missing和inconsistent对象,其最终调用repair_object函数。它只是在peer_missing中标记对象缺失;
3) 最后触发DoRecovery事件发送给PG的状态机,发起实际的对象修复操作。
5. 本章小结
本章介绍了Scrub的基本原理,及Scrub过程的调度机制,然后介绍了校验信息的构建和比较验证的具体流程。
最后,总结一下Ceph的一致性检查Scrub功能实现的关键点:
-
如果做Scrub操作检查的对象范围start和end之间有对象正在进行写操作,就退出本次Scrub进程;如果已经开始启动了Scrub,那么在start和end之间的对象写操作需要等待Scrub操作的完成;
-
检查就是对比主从副本的元数据(size, attrs, omap)和数据是否一致。权威对象的选择是根据对象自己保存的信息(object info)和读取对象的信息是否一致来选举出。然后用权威对象对比其他对象副本来检查。