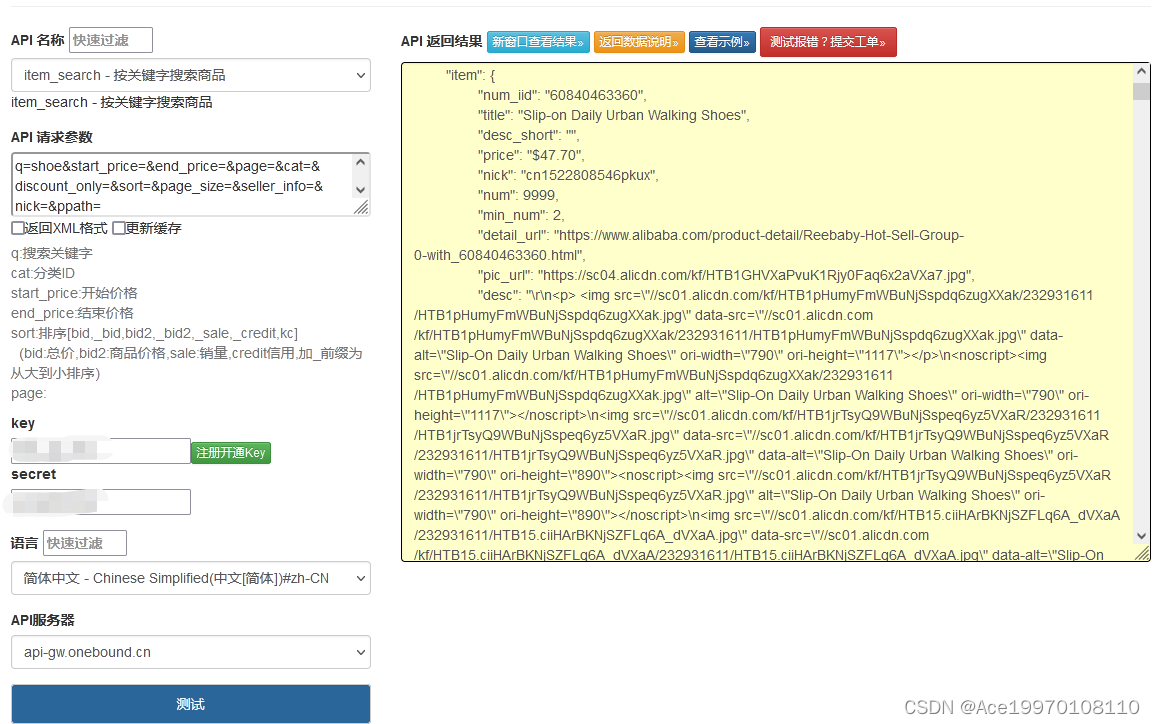
论文地址:https://arxiv.org/pdf/2308.09711.pdf
源码地址:https://github.com/md4all/md4all
概述
现有SOTA的单目估计方法在理想的环境下能得到满意的结果,而在一些极端光照与天气的情况下往往会失效。针对模型在极端条件下的表现不佳问题,文章提出一种用于解决这种安全问题的模型:md4all。该方法首先生成一组与正常样本对应的复杂样本,然后通过生成的样本来计算相应原始视图上的标准损失,引导其自监督或者全监督来训练模型,使得模型在不同条件下能够恢复原始的信息。在nuScenes 和 Oxford RobotCar 数据集上的结果表明该方法的有效性,在标准条件下和极端条件下的表现都超过了之前的工作。

模型架构

Self-Supervised Baseline
使用Monodepth2作为baseline模型,使用白天数据来进行蒸馏学习得到一个针对白天数据的初始模型,如图Fig.3 所示(x=0)。
md4all-AD: Always Daytime, No Bad Weather
核心思想是从简单的样本中学习,即使输入的是困难样本,也能将其转为简单样本后进行推理,如图Fig.4所示。

Day-to-adverse translation
为了训练模型,我们需要同时拥有简单样本与其所对应的困难样本
(
e
i
,
h
i
c
)
(e_i, h_i^c)
(ei,hic),
e
i
e_i
ei 表示简单样本,而
h
i
c
h_i^c
hic 表示困难样本,
c
c
c 代表困难的类型(下雪之类),在正向推理的过程中通过转换模型,将困难样本转换成简单样本然后进行推理。为此,需要先从简单样本中生成困难样本,对于每个简单样本
e
i
e_i
ei和对应的条件
c
c
c,训练一个转换模型来得到
h
i
c
=
T
c
(
e
i
)
.
h_{i}^{c}=T^{c}(e_{i}).
hic=Tc(ei).,通过此步骤,我们将训练的样本集扩充到了
C
×
E
C\times E
C×E。
Training scheme
训练策略如Fig4所示,深度估计模型的输入为
m
i
m_i
mi,是原始简单样本
e
i
e_i
ei 和经过转换的困难样本
h
i
c
h_i^c
hic 的混合。此外,根据记录时间来对输入归一化,用来学习与输入条件无关的鲁棒特征。在极困难的夜晚样本中,通过增加大量噪声来增强输入。对于姿态估计网络,使用采用简单样本序列
[
e
i
−
1
,
e
i
,
e
i
+
1
]
[e_{i-1},e_{i},e_{i+1}]
[ei−1,ei,ei+1]来作为输入。
Learning in all conditions
在困难样本对之间计算重投影误差损失和平滑损失会出现问题,因为在恶劣条件下难以建立有效的匹配。因此,在简单样本上训练,最后在困难样本上部署比同时训练更加有效。为此,作者通过始终在简单样本
E
E
E 上计算损失来提供可靠的训练信息。也就是在
e
i
e_i
ei上计算损失,即使深度模型的输入为
h
i
c
(
x
%
)
h^c_i(x%)
hic(x%),这样会让深度估计模型学习去提取鲁棒特征,无论输入属于
E
E
E还是
H
H
H。
Inference
训练玩深度估计和姿态估计模型后,只保留深度估计模型,在推理时使用参数相同的模型来预测深度,而不需要考虑输入条件。
md4all-DD: Day Distillation
md4all DD的核心思想与md4all AD 相同,通过简化训练方案将后者的性能提升到一个新的水平,md4all-DD框架模仿了理想设置
E
E
E中的模型,不考虑输入的样本难度。如Fig3所示,通过从早期在
E
E
E上训练的深度网络(基线)向新的深度模型DD进行知识蒸馏,以便同时适用于简单和复杂场景。后者使用
m
i
m_i
mi 来训练,即与md4all-AD(第3.1.2节)中的
e
i
e_i
ei和
h
i
c
h^c_i
hic 相同的混合,而前者使用
e
i
e_i
ei 来训练。 DD仅通过以下目标进行优化:
L
d
=
1
N
∑
j
=
1
N
∣
D
D
(
m
i
)
j
−
B
(
e
i
)
j
∣
D
D
(
m
i
)
j
(1)
\mathcal{L}_d=\frac1N\sum_{j=1}^N\frac{|DD(m_i)_j-B(e_i)_j|}{DD(m_i)_j}\tag{1}
Ld=N1j=1∑NDD(mi)j∣DD(mi)j−B(ei)j∣(1)
实验结果