参数宝典
- 如何正确设置参数
- flink Table模式下的参数
- Table 模式下参数类相关
- DataStream 模式下怎么设置参数?
- 总结
如何正确设置参数
很多人在应用flink DataStream 或者是Flinksql 的时候对于一些参数设置知道的不是很清晰,本文带领大家彻底搞定这一块。
- 在flink的配置文件中设置,这个就不多说了,缺点就是不够灵活
- 在代码层面设置
flink Table模式下的参数
public class SingleTableMain {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
}
public static void setStateBackendAndCheckpoint(StreamExecutionEnvironment env, String checkpointPath) {
env.setStateBackend(new EmbeddedRocksDBStateBackend(true)); // 设置状态后端
//每30秒启动一个检查点
env.enableCheckpointing(60000);
//允許几次檢查點失敗
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(3);
// 设置状态后端
env.setStateBackend(new EmbeddedRocksDBStateBackend(true));
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage(checkpointPath));
//检查点保存模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置最小间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(TimeUnit.MINUTES.toMillis(2));
//设置超时时长
env.getCheckpointConfig().setCheckpointTimeout(TimeUnit.MINUTES.toMillis(5));
// 最大并发检查点数量,如果上面设置了 最小间隔,其实这个参数已经不起作用了
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//可恢复
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//重试机制
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, org.apache.flink.api.common.time.Time.of(30, TimeUnit.SECONDS)));
}
public static void enableMiniBatch(StreamTableEnvironment tEnv, Duration duration, Long size) {
//The maximum number of input records can
// be buffered for MiniBatch.
// MiniBatch is an optimization to buffer input records to reduce state access.
// MiniBatch is triggered with the allowed latency interval and when the maximum number of buffered records reached.
// NOTE: MiniBatch only works for non-windowed aggregations currently.
// If table.exec.mini-batch.enabled is set true, its value must be positive.
Configuration configuration = new Configuration();
configuration.set(ExecutionConfigOptions.TABLE_EXEC_MINIBATCH_ENABLED, true);
configuration.set(ExecutionConfigOptions.TABLE_EXEC_MINIBATCH_ALLOW_LATENCY, duration);
configuration.set(ExecutionConfigOptions.TABLE_EXEC_MINIBATCH_SIZE, size);
tEnv.getConfig().addConfiguration(configuration);
}
public static void setTTL(StreamTableEnvironment tEnv, Duration duration) {
Configuration configuration = new Configuration();
configuration.set(ExecutionConfigOptions.IDLE_STATE_RETENTION, duration);
tEnv.getConfig().addConfiguration(configuration);
}
public static void enableSqlOptimizer(StreamTableEnvironment tEnv) {
Configuration configuration = new Configuration();
// 设置两阶段聚合
configuration.set(OptimizerConfigOptions.TABLE_OPTIMIZER_AGG_PHASE_STRATEGY, "TWO_PHASE");
//开启 Split Distinct
configuration.set(OptimizerConfigOptions.TABLE_OPTIMIZER_DISTINCT_AGG_SPLIT_ENABLED, true);
configuration.set(OptimizerConfigOptions.TABLE_OPTIMIZER_DISTINCT_AGG_SPLIT_BUCKET_NUM, 2048);
tEnv.getConfig().addConfiguration(configuration);
}
public static void setIdleTimeout(StreamTableEnvironment tEnv, Duration duration) {
Configuration configuration = new Configuration();
configuration.set(ExecutionConfigOptions.TABLE_EXEC_SOURCE_IDLE_TIMEOUT, duration);
tEnv.getConfig().addConfiguration(configuration);
}
public static void setJobName(StreamTableEnvironment tEnv, String jobName) {
Configuration configuration = new Configuration();
configuration.set(PipelineOptions.NAME, jobName);
tEnv.getConfig().addConfiguration(configuration);
}
public static void enableDynamicParam(StreamTableEnvironment tEnv){
Configuration configuration = new Configuration();
configuration.set(TableConfigOptions.TABLE_DYNAMIC_TABLE_OPTIONS_ENABLED,true);
tEnv.getConfig().addConfiguration(configuration);
logger.info("[SqlUntil] 开启动态table参数");
}
}
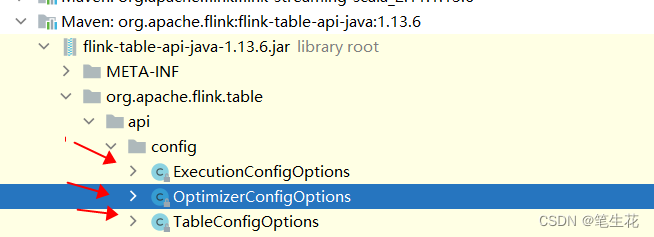
Table 模式下参数类相关
上面的代码对应下方的内部类,正好对应Table SQL模式下的:执行参数,优化参数,表参数
DataStream 模式下怎么设置参数?
Configuration configuration = new Configuration();
configuration.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY,"hdfs://xxx:8020/remote-default-checkpoints/penggan/");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
上面这种只是举了个例子,感兴趣的请看下图:

总结
上面是最为原始的设置参数的方式,支持的参数对应的其实就是:flink官网核心参数
flink tablesql 参数
所谓的参数就是控制程序的执行行为的, 参数分为
- 动态传参(启动程序在cmd传入)
- 程序代码设置
- 读取默认配置文件(flink-conf.yml)
上文讲的是代码设置, 其实参数底层解析的就是截图中的类, 可以看到根据参数的行为flink内部用不通的类去解析,这些类我们也可以直接拿来修改参数, 这就是本文的意义。


![java八股文面试[数据库]——InnoDB与MyISAM的区别](https://img-blog.csdnimg.cn/img_convert/4c96d3adbca45be82b6f2030810758d2.png)