文章目录
- 1. torch.nn.Conv2d
- 2. torch.nn.MaxPool2d
- 3. torch.nn.ReLU
- 4. torch.nn.Linear
- 5. torch.nn.Dropout
卷积神经网络详解:csdn链接
其中包括对卷积操作中卷积核的计算、填充、步幅以及最大值池化的操作。
1. torch.nn.Conv2d
对由多个输入平面组成的输入信号应用2D卷积。
官方文档:torch.nn.Conv2d
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
主要参数:
- in_channels(int):输入图像中的通道数
- out_channels(int):卷积产生的通道数
- kernel_size(int或tuple):卷积内核的大小
默认参数:
- stride(int或tuple,可选):卷积的步幅。默认值:1
- padding(int,tuple或str,可选):添加到输入的所有四边的填充。默认值:0
- padding_mode(str,可选):‘zeros’ 、 ‘reflect’ 、 ‘replicate’ 或 ‘circular’ 。默认值: ‘zeros’
- dilation(int或tuple,可选):内核元素之间的间距。默认值:1
- groups(int,可选):从输入通道到输出通道的阻塞连接数。默认值:1
- bias(bool,可选):如果 True ,则向输出添加可学习的偏置。默认值: True
举例说明
import torch
from torch import nn
# 内核方正,步调一致
m1 = nn.Conv2d(16, 33, 3, stride=2)
# 非方形内核和不等距步长,并有填充
m2 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
# 非方形内核和不等步长,以及填充和扩张
m3 = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
卷积核通过选取内核大小,其中参数值是随机的
import torch
from torch import nn
k = nn.Conv2d(1, 1, 3, stride=1)
print(list(k.parameters()))

使用CIFAR10数据进行卷积操作,并进行可视化操作
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 使用CIFAR10的训练数据
train_data = torchvision.datasets.CIFAR10("../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(train_data, batch_size=64)
writer = SummaryWriter("logs")
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)
def forward(self, x):
x = self.model1(x)
return x
step = 0
# 创建模型
model = Model()
for data in train_loader:
imgs, targets = data
output = model(imgs)
writer.add_images("input", imgs, step)
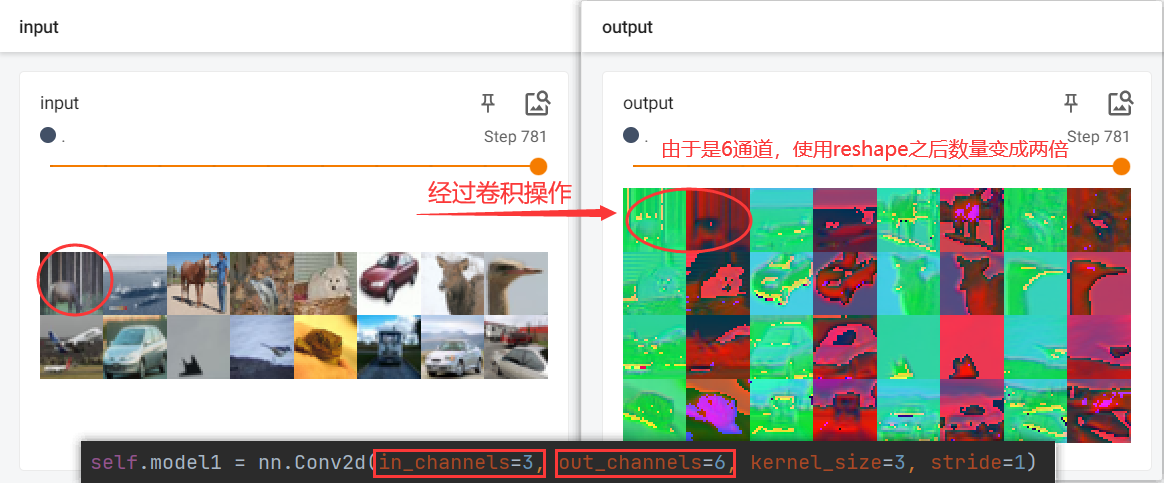
# output此时为6通道,为了可视化,现将其转换为3通道
# imgs 的形状大小为 [64, 3, 32, 32]
# 经过卷积操作后,output的高度和宽度为:32 - 3 + 1 = 30
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
writer.close()
打开命令行,输入以下代码,并打开TensorBoard的链接: http://localhost:6006/
tensorboard --logdir=logs
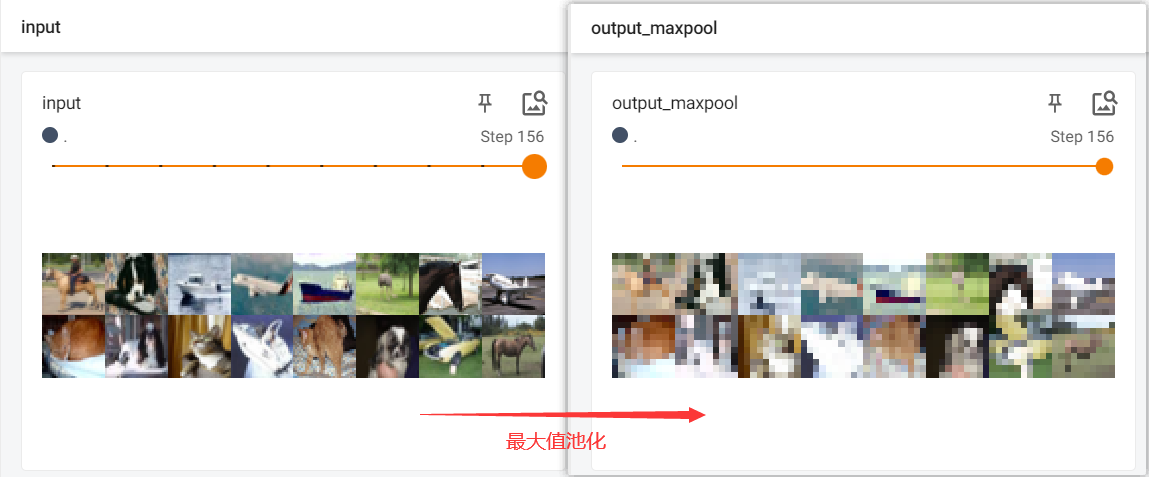
2. torch.nn.MaxPool2d
最大值池化层,对由多个输入平面组成的输入信号应用2D最大池化。
官方文档:torch.nn.MaxPool2d
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数 kernel_size 、 stride 、 padding 、 dilation 可以是:
- 单个 int-在这种情况下,高度和宽度尺寸使用相同的值
- 两个int的 tuple -在这种情况下,第一个int用于高度维度,第二个int用于宽度维度
主要参数:
- kernel_size(Union[int,Tuple[int,int]])-窗口的最大值
默认参数:
- stride(Union[int,Tuple[int,int]])-窗口的步幅。默认值为 kernel_size
- padding(Union[int,Tuple[int,int]])-要在两边添加的隐式负无穷大填充
- dilation(Union[int,Tuple[int,int]])-控制窗口中元素步幅的参数
- return_indices(bool)-如果 True ,将返回最大索引沿着输出。 torch.nn.MaxUnpool2d 以后有用
- ceil_mode(bool)-当为True时,将使用ceil而不是floor来计算输出形状
最大汇聚层,也叫做最大池化层,代码实现
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 使用测试数据集
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
writer = SummaryWriter("logs")
class Model(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
# 创建模型
model = Model()
step = 0
for data in dataloader:
imgs, targets = data
output = model(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output_maxpool", output, step)
step = step + 1
writer.close()
3. torch.nn.ReLU
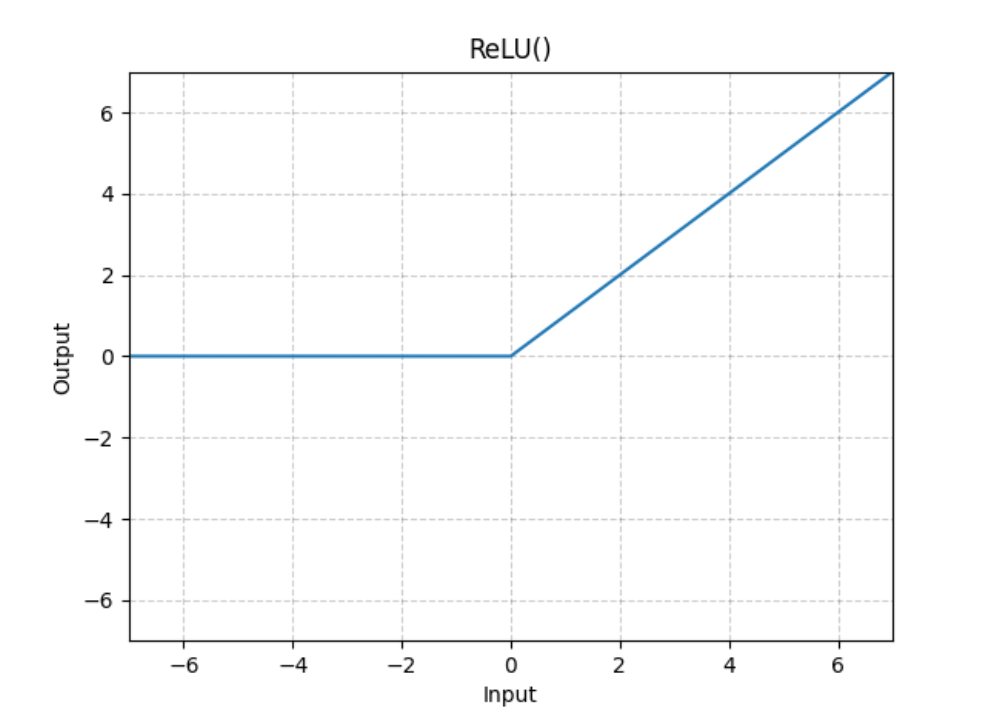
非线性激活函数,逐元素应用整流线性单位函数:
输入与输出形状相同
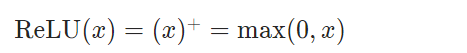
官方文档:torch.nn.ReLU
CLASS torch.nn.ReLU(inplace=False)
主要参数:
- inplace(bool):可以选择就地执行操作。默认值: False
代码实现
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 使用测试数据集
dataset = torchvision.datasets.CIFAR10("../dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
writer = SummaryWriter("logs")
class Model(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = nn.ReLU()
def forward(self, input):
output = self.relu1(input)
return output
# 创建模型
model = Model()
step = 0
for data in dataloader:
imgs, targets = data
output = model(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step = step + 1
writer.close()
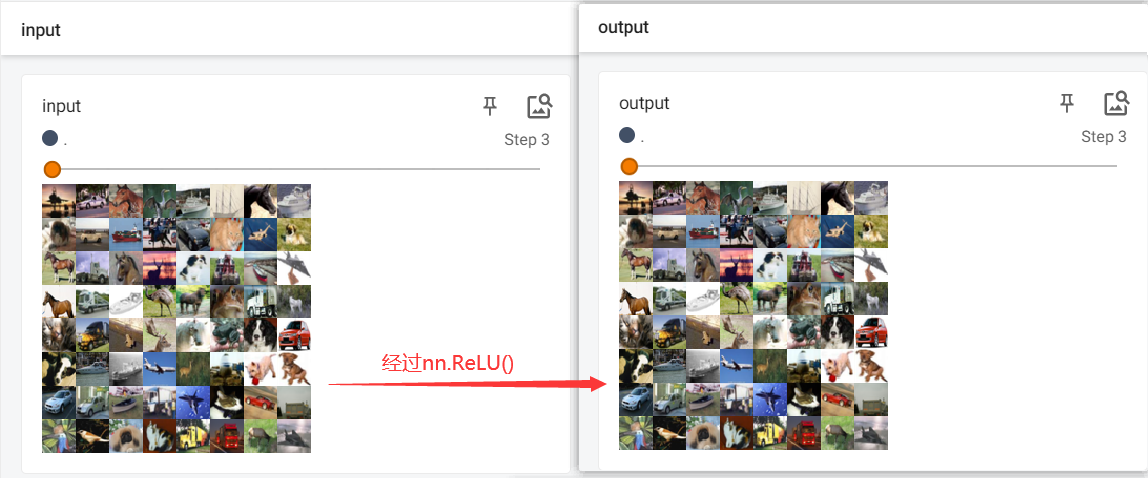
nn.ReLU()不是很明显,这里用nn.Sigmoid()更为清除
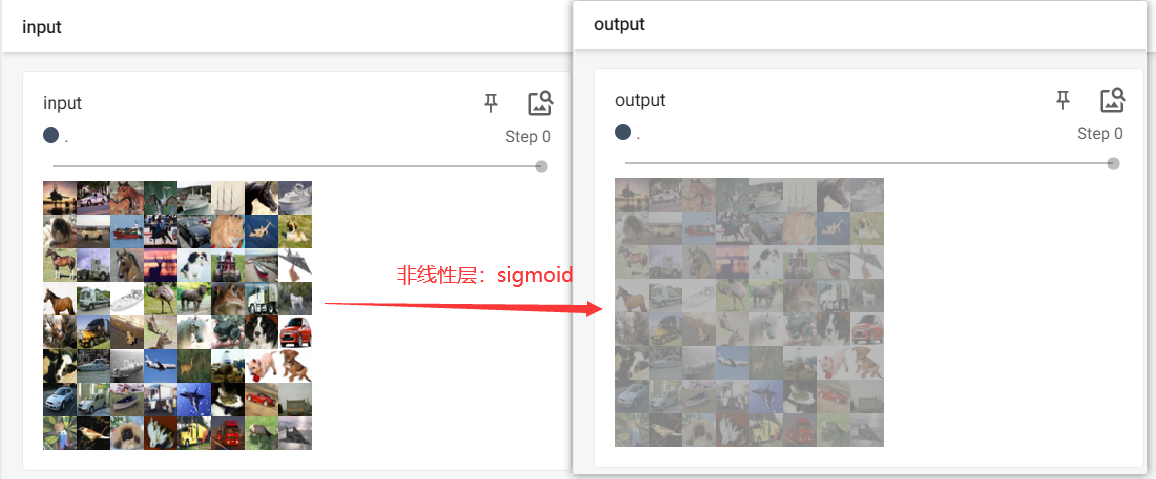
4. torch.nn.Linear
线性层,对传入数据应用线性变换: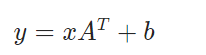
官方文档:torch.nn.Linear
CLASS torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
主要参数:
- in_features(int):每个输入样本的大小
- out_features(int):每个输出样本的大小
默认参数:
- bias(bool):如果设置为 False ,则层将不会学习加性偏置。默认值: True
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
module = Module()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs)
print(output.shape)
output = module(output)
print(output.shape)

5. torch.nn.Dropout
在训练期间,使用来自伯努利分布的样本以概率 p 随机地将输入张量的一些元素归零。每个信道将在每次前向呼叫时独立地归零。
官方文档:torch.nn.Dropout
CLASS torch.nn.Dropout(p=0.5, inplace=False)
主要参数:
- p(float)-元素被置零的概率。默认值:0.5
- inplace(bool)-如果设置为 True ,将就地执行此操作。默认值: False


![[uniapp]踩坑日记 unexpected character > 1或‘=’>1 报错](https://img-blog.csdnimg.cn/3555966dca0d450ab549205d4f2786f6.png)