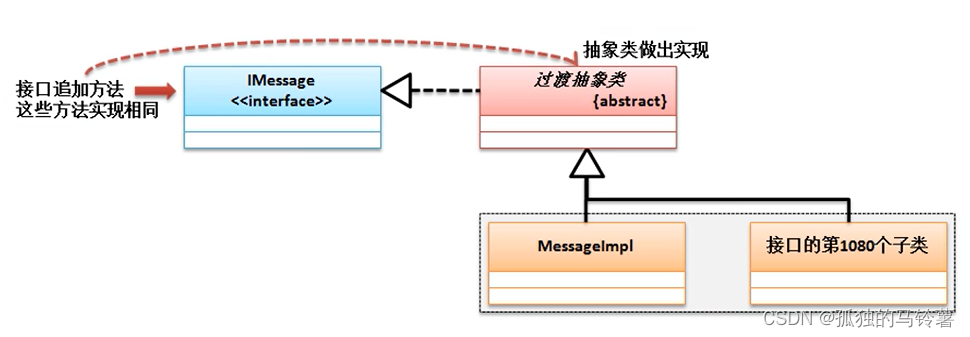
ALBEF(ALign BEfore Fuse)
为什么有5个loss?
两个ITC+两个MIM+1个ITM。ITM是基于ground truth的,必须知道一个pair是不是ground truth,同时ITM loss是用了hard negative,这个是和Momentum Distillation(动量蒸馏)是有冲突的,所以ITM只有一个loss没有给基于Momentum Distillation的loss。而另外两个都有基于Momentum Distillation版本的loss
为什么要做Momentum Distillation?
The image-text pairs used for pre-training are mostly collected from the web and they tend to be noisy. Positive pairs are usually weakly-correlated: the text may contain words that are unrelated to the image, or the image may contain entities that are not described in the text. For ITC learning, negative texts for an image may also match the image’s content. For MLM, there may exist other words different from the annotation that describes the image equally well (or better). However, the one-hot labels for ITC and MLM penalize all negative predictions regardless of their correctness.
Momentum Distillation是怎么做的?
To address this, we propose to learn from pseudo-targets generated by the momentum model. The momentum model is a continuously-evolving teacher which consists of exponential-moving-average versions of the unimodal and multimodal encoders. 简单说就通过exponential-moving-average(多数代码库都是自带EMA的,比如swin tranformer和Deit等)来产生一些伪标签。即预测的时候不光和原始的one-hot labeling接近,也和pseudo-targets接近,当one-hot labeling不够准时,pseudo targets就派上用场了
Momentum Distillation里为什么用KL散度代替了交叉熵?
简单来说,就是因为Distillation的结果是一个softmax结果而不是onehot,直接在Pytorch的CE里用不了,所以换了KL散度,下面有更详细的解释
KL散度和交叉熵在什么条件下是一样的?
不带label smoothing,label是完全的onehot形式(例如3个类,只能是[0,0,1]、[0,1,0]和[1,0,0]),这种情况下KL散度结果就和交叉熵是完全一样的,可以回顾下https://blog.csdn.net/taoqick/article/details/132650037。**但是在Pytorch实现中,交叉熵的输入对onehot限制非常死,比如有K分类,只能输入其中某一类类别的下标,输入强onehot。但是在Pytorch的KVDivLoss就可以是两个分布算loss,增加了灵活性。**但KVDivLoss针对
q
i
q_i
qi也就是logits对应的输入要预先过一下log(都是为了NLLLoss(Softmax)的CrossEntropyLoss进行对齐),而且KVDivLoss和数学上KL(P||Q)的参数顺序是反的,下面截图自
https://pytorch.org/docs/stable/generated/torch.nn.KLDivLoss.html