Pytorch从零开始实战——MNIST手写数字识别
文章目录
- Pytorch从零开始实战——MNIST手写数字识别
- 环境准备
- 数据集
- 模型选择
- 模型训练
- 可视化展示
环境准备
本系列基于Jupyter notebook,使用Python3.7.12,Pytorch1.7.0+cu110,torchvision0.8.0,需读者自行配置好环境且有一些深度学习理论基础。
导入需要用到的包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torch.nn.functional as F
import random
from time import time
import random
import numpy as np
import pandas as pd
import datetime
import gc
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
创建设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type=‘cuda’)
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
数据集
本次实战使用MNIST数据集,这是一个包含了手写数字的灰度图像的数据集,每个图像都是28x28像素大小,并且标记了相应的数字,也是很多计算机视觉初学者第一个使用的数据集。
导入训练集与测试集,使用torchvision.datasets可以在线下载很多常见数据集,只需要将后面参数设置download=True即可直接下载,train=True为训练集,train=False为测试集
# 导入训练集和测试集
train_data = torchvision.datasets.MNIST('data', train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.MNIST('data', train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
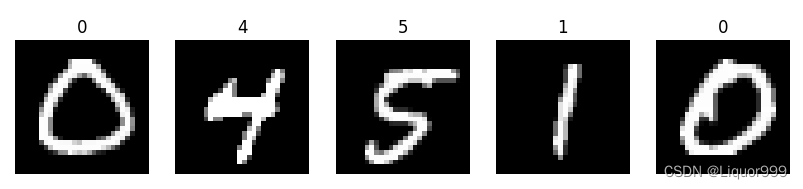
定义一个函数,随机查看5张图片
# 随机展示5个图片 data = torchvision.datasets.... 需要接受tensor格式的对象
def plotsample(data):
fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图
for i in range(5):
num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次
#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据
#而展示图像用的imshow函数最常见的输入格式也是3通道
npimg = torchvision.utils.make_grid(data[num][0]).numpy()
nplabel = data[num][1] #提取标签
#将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取
axs[i].imshow(np.transpose(npimg, (1, 2, 0)))
axs[i].set_title(nplabel) #给每个子图加上标签
axs[i].axis("off") #消除每个子图的坐标轴
plotsample(train_data)
使用DataLoder将它按照batch_size批量划分,并将训练集顺序打乱。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_data, batch_size=batch_size)
模型选择
由于数据集较为简单,所以本次实验使用简单的卷积神经网络。
第一次卷积和池化:
self.conv1 是第一个卷积层,将输入特征图的通道数从1增加到32,同时使用3x3的卷积核进行卷积。由于没有填充(padding)操作,卷积后的特征图大小减小为原来的大小减2(28x28 -> 26x26)。
self.pool1 是第一个最大池化层,将特征图的大小减半,从26x26变为13x13。
第二次卷积和池化:
self.conv2 是第二个卷积层,将输入特征图的通道数从32增加到64,同样使用3x3的卷积核进行卷积。由于没有填充操作,卷积后的特征图大小再次减小为原来的大小减2(13x13 -> 11x11)。
self.pool2 是第二个最大池化层,将特征图的大小再次减半,从11x11变为5x5。
全连接层:
在进入全连接层之前,需要将最后一个池化层的输出拉平成一个一维向量。这是通过 torch.flatten(x, start_dim=1) 完成的,它将5x5x64的三维张量转换为长度为5x5x64 = 1600的一维向量。
然后,self.fc1 是第一个全连接层,将1600个输入特征映射到64个输出特征。
最后进行10分类输出结果。
num_classes = 10 # 10分类
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(1600, 64)
self.fc2 = nn.Linear(64, num_classes)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = torch.flatten(x, start_dim=1) # 拉平
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
将模型转移到GPU中,并使用summary查看模型
from torchinfo import summary
# 将模型转移到GPU中
model = Model().to(device)
summary(model)

模型训练
定义损失函数、学习率、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.01
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)
定义训练函数,返回一个epoch的模型的准确率和损失
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
定义测试函数,与训练函数类似,只是停止梯度更新,节省计算内存消耗
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for X, target in dataloader:
X, target = X.to(device), target.to(device)
pred = model(X)
loss = loss_fn(pred, target)
test_acc += (pred.argmax(1) == target).type(torch.float).sum().item()
test_loss += loss.item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
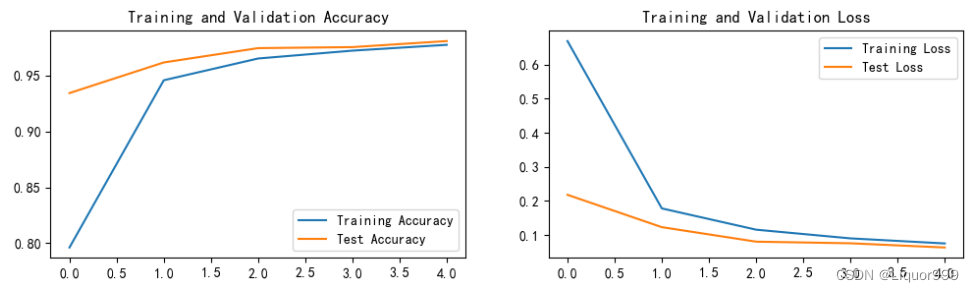
开始训练,一共进行了5轮epoch,最后在训练集准确率可达97.7%,测试集准确率可达98.1%
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval() # 确保模型不会进行训练操作
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"
% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print("Done")
可视化展示
使用matplotlib进行训练、测试的可视化
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()