好, 因为我没怎么看懂, 所以我决定再看一遍PPO的代码, 再研究一遍。
事实证明, 重复是一个非常好,非常好的方法。 学习方法。
世界上几乎没有任何新知识是你一遍就能学会的。 你只能学一遍,再来一遍, 你才会理解。深刻的理解讲的是什么东西。
那我们再来看一遍代码吧!!!!
先不论算法。 直接看代码。
我们来看一个PPO的代码。 这份代码来自于蘑菇书。
Releases · datawhalechina/easy-rl · GitHub 这里下载代码解压就可以看到。
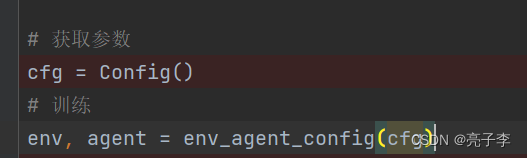
上来是一些设置和参数,

这个设置还挺关键的。 用PPO, 然后玩cart车, clip值等。

cart车这个游戏, 输入是4个数, 动作有两个。
然后创建代理模型。


动作网络就是一个非常普通的网络。 从4到256 再从256到256,再从256到2.

critic网络也差不多。 输入是4个状态, 输出是1维, 表示这个状态预期能够得到的奖励。

memory是一个队列。 定义了这些就可以训练了。

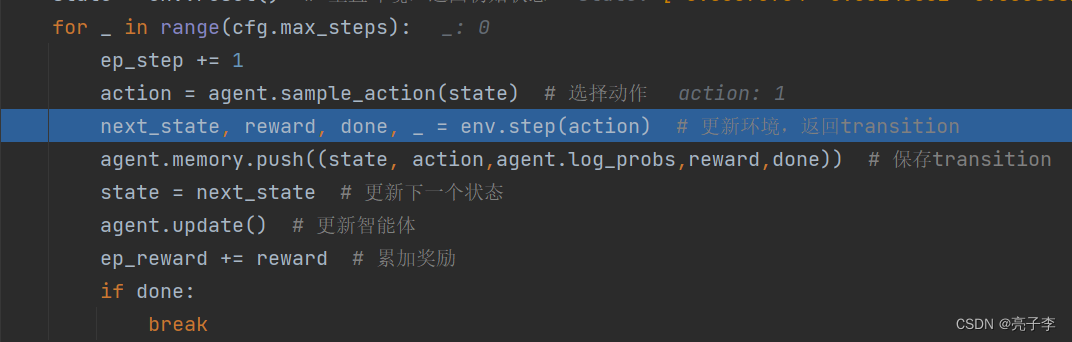 这个就是训练流程, sample_action就是通过actor取一个动作。
这个就是训练流程, sample_action就是通过actor取一个动作。

过程就是普通的让输入通过网络后得到输出的概率分布, 作为分布后再采样一个动作。 并且还要把这个动作的概率给记录下来。

输入动作 就会得到这一步的奖励R, 然后是否结束, 和下一步的状态。
把他存入队列当中去。
![]()
这里更新不是每次都更新, 而是经过一些轮次才更新。 多少呢? 就是100

采样一百次才更新一次。

开始更新, 取出模型 采样的数据, 包括当时的s, 当时的动作a, 当时的动作对应对数概率, 当时的奖励r, 当时是否结束等。 这里要注意的是, 这100个数据都是在同一轮游戏中采样出来的, 这样真的可以吗?????

看这里, done的时候就会结束这一轮的。

算出乘以时间因子的优势函数 A(s,a),并且归一化, 原来是还需要归一化的。 对应下面这个。


优势函数除了归一化外还需要减去一个baseline。 这个baseline来自于critic预测的value值。 也就是这个状态能得到的奖励的期望。

这里这个value就是这个baseline b 也就是这个状态平均能得到的奖励。

这里应该是固定的套路了。

实现的是这个优化目标。
这个surr1 就是
ratio 也就是两个的概率log值的商。 乘上优势函数。
下面就是那个剪

ratio第一次算出来全部都是1, 也就是说其实第一次肯定是一样的啦, 因为还没更新,这个时候, 两个都是一样的: surr1 和surr2是一样的, 因为他们比值都是1.

然后是critic的更新, 因为这个critic预测的是这个状态将会的得到的奖励。因此用真实的return 和它的预测值做一个mseloss。 然后critic和actor同时更新。

更新一轮之后, 基本上这个ratio就不是1了, 就需要徘徊一下了。
然后4轮更新后, 清除上一轮的数据, 开启下一轮的收集。 
所以这里的 模型 就是什么呢, 就是这4轮更新前的模型。
更新的那个模型是。 他们其实是同一个模型。 不过采样的时候, 用了
好了 感觉理解了, 我们可以开始用在自己项目了。