kibana设置ILM
1. 背景
kibana version: v7.9.3
2. 设置ILM
2.1 创建索引生命周期策略
2.1.1 热阶段
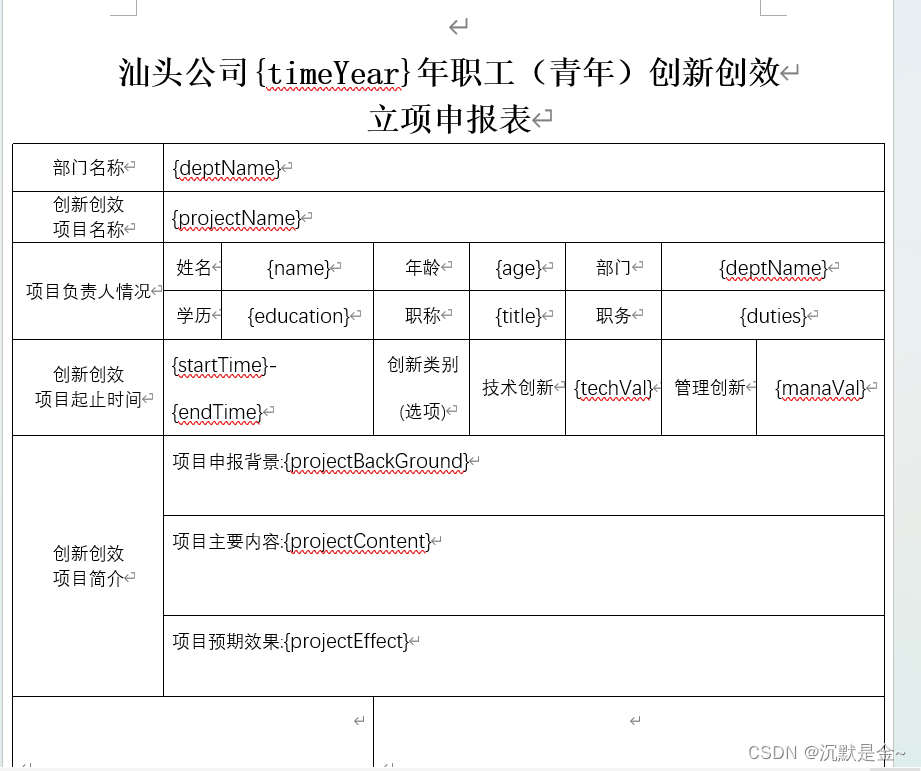
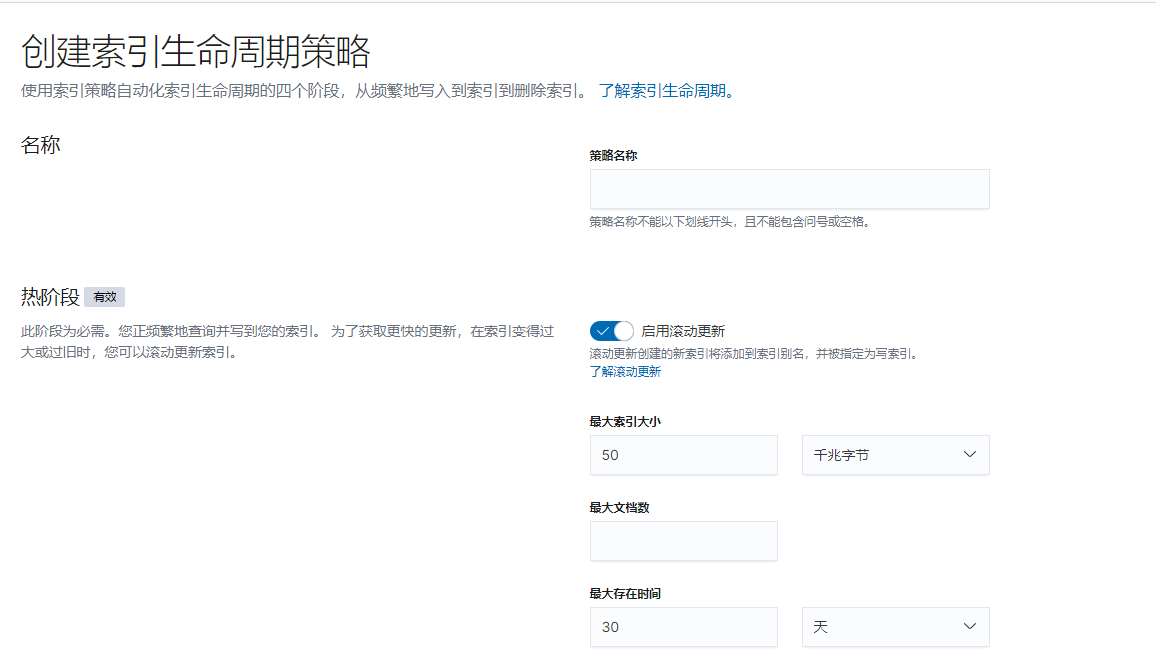
首先需要先创建索引生命周期策略,在索引模板中可以引用创建好的索引生命周期策略。
-
策略名称: 引用该策略是需要用,例如设置为:filebeat-index-ilm
-
最大索引大小:设置单个索引最大字节数,此处为50千兆字节,即50G.
-
最大文档数:设置单个索引所内容乃的最大文档数,超过该数则创建新的索引。
-
最大存在时间: 指的是索引在温热阶段中可以存在的最长时间。一旦索引达到这个时间限制,它将被自动转移到冷却阶段,并最终被归档或删除。
"最大存在时间"是一个可选的参数,你可以根据实际需求来决定是否设置这个参数。如果你没有设置这个参数,索引将会一直保持在温热阶段,直到你手动将其转移到冷却阶段或删除。
在设置"最大存在时间"时,你可以选择一个固定的时间长度,例如30天。这意味着索引在温热阶段中最多存在30天,之后它将被自动转移到冷却阶段。这个参数可以帮助你控制索引的生命周期,避免过多的旧索引占用存储空间和资源。
需要注意的是,具体的索引生命周期策略还受到其他参数的影响,例如滚动布署的频率、索引模板、索引生命周期策略等。因此,在实际应用中,需要根据具体的业务需求和数据量来调整和优化这些参数。
2.1.2 温阶段和冷阶段
温阶段和冷阶段不再设置,解释一下这两个阶段:
在 Kibana 中创建索引生命周期策略时,warm phase和Cold phase的存在有意义,它们适用于不同的场景。
-
Warm phase(温阶段): Warm phase是索引生命周期的中间阶段,适用于处理活跃但不再频繁更改的数据。在这个阶段,索引被用于的搜索和查询操作较多,因此需要保持良好的搜索性能。在温阶段,索引可以被滚动更新,以保持其当前的索引结构、映射和设置。
温阶段适用于以下场景:
- 数据检索:如果您的应用程序需要从历史数据中检索信息,并且这些数据已经过了一段时间但仍然活跃,那么可以将索引设置为在温阶段。
- 数据归档和分析:如果您的应用程序需要将数据存储一段时间以便进行进一步的分析、报告或可视化,那么可以将索引设置为在温阶段。
-
Cold phase(冷阶段): Cold phase是索引生命周期的后期阶段,适用于处理不再活跃的数据。在这个阶段,索引被用于的搜索和查询操作较少,因此可以降低存储成本和索引维护开销。在冷阶段,索引可以被归档和压缩,以进一步降低存储成本。
冷阶段适用于以下场景:
- 数据归档:如果您的应用程序需要长期存储数据,并且这些数据不再被频繁地搜索和查询,那么可以将索引设置为在冷阶段。
- 数据保留策略:如果您的应用程序需要保留某些数据一段时间后将其删除,那么可以将索引设置为在冷阶段,并在达到保留期限时自动删除索引。
综上所述,温阶段和冷阶段的存在意义在于进一步优化索引生命周期的管理。通过将索引分阶段管理,可以更好地平衡性能、存储成本和维护开销,以满足不同的业务需求。
2.1.3 删除阶段
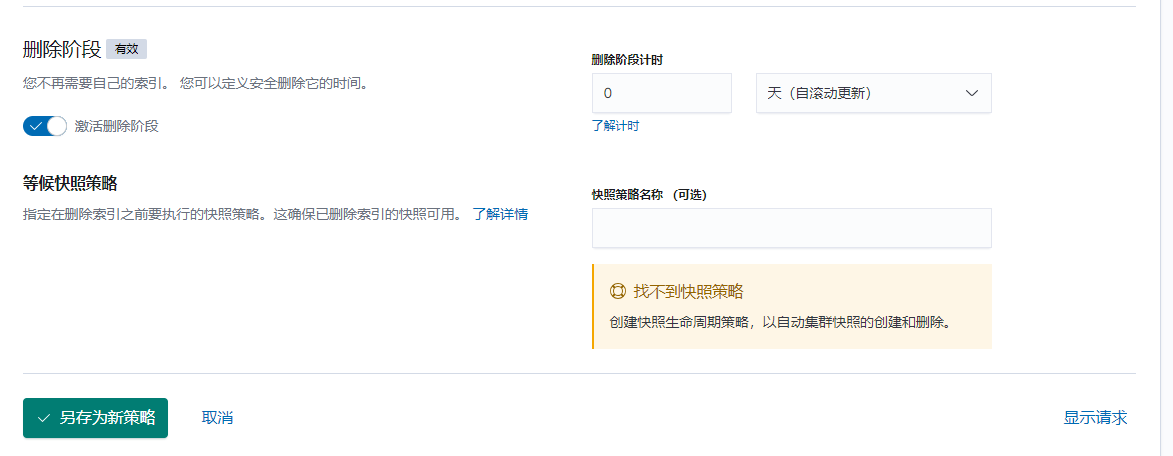
- 删除倒计时: 设置日志多久之后删除。
2.2 创建索引模板

-
名称:索引模板名
-
索引模式: 用来匹配应用于哪些索引,例如匹配filebeat-开头的索引;filebeat-*
-
优先级:是一个整数值,用于确定索引模板的优先级。较高的优先级值表示该索引模板具有更高的优先级。当多个索引模板匹配到同一个索引时,优先级最高的索引模板将被应用。
-
版本:是一个整数值,用于跟踪索引模板的版本号。你可以根据需要为每个索引模板设置一个唯一的版本号。当索引模板需要更新时,你可以增加版本号以确保新版本的索引模板被应用。
-
_meta 字段:_meta 字段是一个 JSON 对象,用于存储与索引模板相关的元数据。你可以在 _meta 字段中添加自定义的键值对,例如索引模板的创建时间、作者等信息。这些元数据可以在使用 Elasticsearch API 管理索引模板时进行访问和操作。
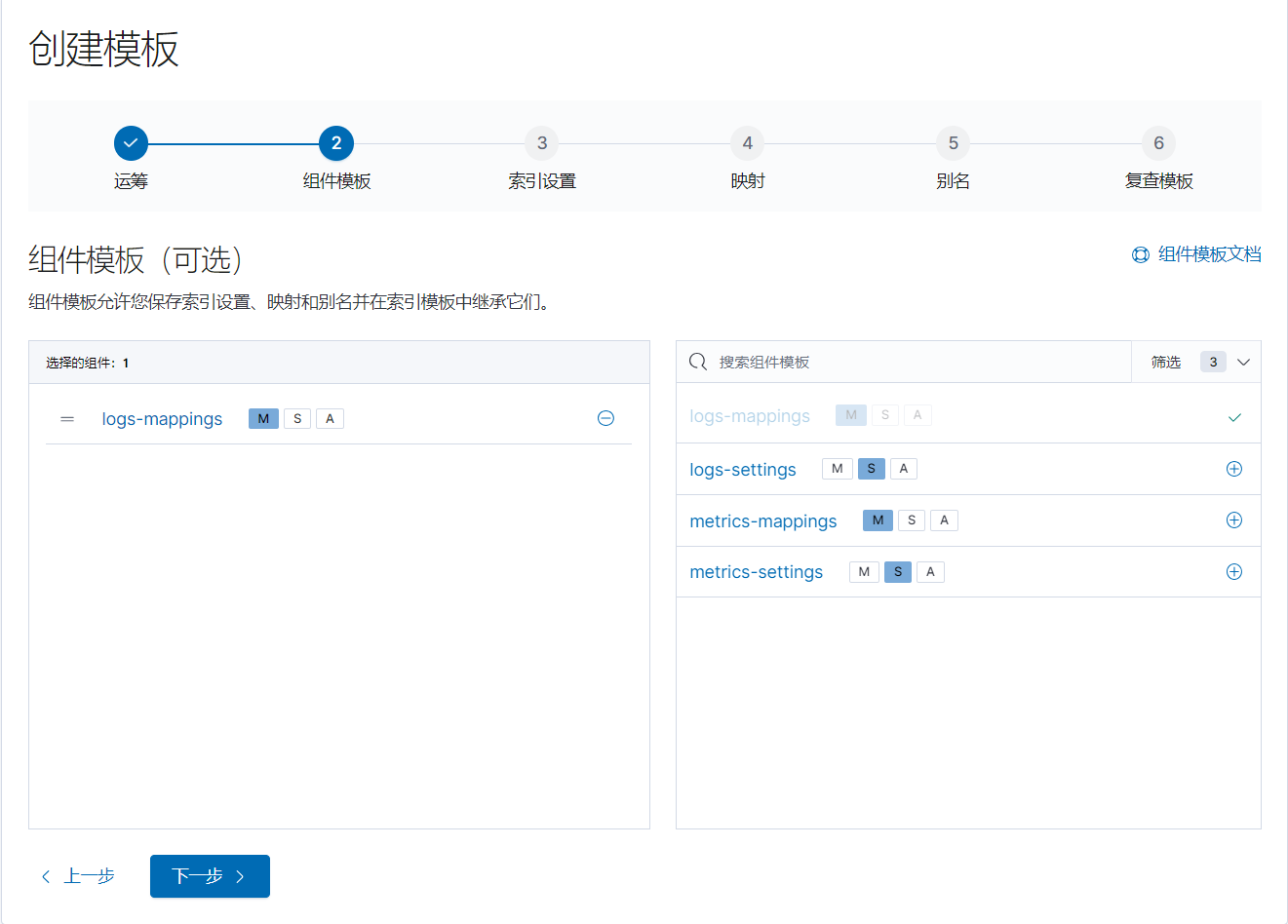
- 选择组件: 引用已经创建好的组件模板

- 索引设置: 图中设置了生命周期相关内容,lifecycle:指的就是索引的生命周期,这里就是我们之前创建的索引生命周期;rollover_alias:滚动别名,当我们配置了索引大小,超过这个大小后,会以这个名称命名。
- 映射字段:
映射字段是指将文档中的字段与特定的数据类型和属性进行映射。在创建索引模板时,可以手动添加映射字段,以便在索引文档时将字段映射为指定的数据类型和属性。例如,可以添加一个名为 "message" 的映射字段,将其映射为文本类型,并设置其分析器为 "standard"。
映射字段适用于以下场景:
-
数据类型已知且固定的场景:当文档中的字段类型固定且已知时,可以手动添加映射字段,以确保索引的准确性和性能。
-
需要自定义数据类型的场景:当文档中存在自定义的数据类型时,可以手动添加映射字段,并将其映射为相应的数据类型,以便在查询和聚合时能够正确地处理数据。
- 动态模板:
动态模板是指根据文档中的字段名、数据类型等动态地设定字段类型。在创建索引模板时,可以定义动态模板规则,以便根据文档的实际情况动态地设定字段类型。例如,可以定义一个名为 "text" 的动态模板,将所有以 "message" 开头的字段映射为文本类型。
动态模板适用于以下场景:
-
数据类型未知或动态变化的场景:当文档中的字段类型未知或动态变化时,可以使用动态模板来自动识别字段类型,并将其映射为相应的数据类型。
-
需要灵活处理不同数据类型的场景:当文档中存在多种数据类型时,可以使用动态模板来根据字段名、数据类型等信息动态设定字段类型,以便在查询和聚合时能够正确地处理数据。
- 高级选项:
高级选项是指在创建索引模板时可以配置的一些高级设置,例如索引分片数、索引副本数、分析器等。这些设置可以优化索引的性能和存储效率。
高级选项适用于以下场景:
- 需要优化索引性能的场景:可以通过配置索引分片数和索引副本数来优化索引的性能,提高查询和聚合的速度。
- 需要优化存储效率的场景:可以通过配置存储设置和分析器来优化索引的存储效率,减少存储空间的使用.。
-
设置索引别名
- 方便对多个索引进行查询:如果你有许多索引并且经常需要同时查询这些索引,使用别名可以方便地将这些索引组合在一起进行查询。
- 简化索引引用:在查询时,只需要引用别名,而不需要写出完整的索引名称,这使得查询语句更加简洁。
- 方便索引的版本控制:如果你在系统中对索引进行更新或替换,使用别名可以使得对已有查询的影响最小化。例如,你可以创建一个别名,使其始终映射到最新的索引版本,这样在更新索引时,不需要更改所有查询。
在 Elasticsearch 中创建别名的方法是通过使用 "alias" API。例如,如果你有一个索引 "test-20190120",并想为其创建一个别名 "test",你可以使用以下的请求:
bash复制代码PUT /_aliases { "actions": [ { "add": { "index": "test-20190120", "alias": "test" } } ] }在上述请求中,"add" 动作告诉 Elasticsearch 将别名 "test" 添加到索引 "test-20190120" 上。之后,你可以使用别名 "test" 来查询该索引的内容。
完成模板创建。
3. 生效
创建索引生命周期之前的创建的索引不会受索引生命周期影响,之后创建的索引会进入到索引生命周期的策略管理中。