Hashtable和HashMap的区别
HashMap和Hashtable都是哈希表数据结构,但是Hashtable是线程安全的,HashMap是线程不安全的
Hashtable实现线程安全就是简单的把关键方法都加上了synchronized关键字
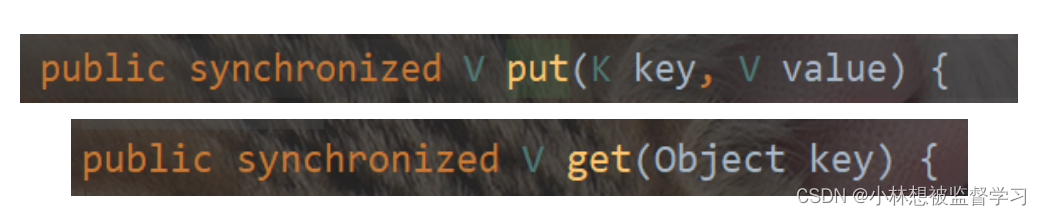
直接在方法上添加synchronized相当于针对this对象(Hashtable对象)加锁,一个Hashtable只有一把锁,所以当我们对Hashtable执行任何操作的时候都会触发锁冲突,效率是非常低的
Hashtable是存在很多问题
1.
由于直接对方法进行加锁,所以当有很多线程需要访问Hashtable时就会导致严重的锁冲突
2.
当我们向Hashtable中添加数据时,对应的size属性应该增加,此时就涉及到多个线程修改同一个变量,存在线程安全问题,而size属性也是通过synchronized来解决线程安全问题的,所以效率会很低
3.
哈希表有一个特性,当存放到哈希表中的数据越来越多,冲突率达到一定的数值,就会触发扩容,一旦触发扩容,就会由当前的线程去完成整个扩容过程,这个过程涉及到大量的元素拷贝,效率会很低
可能会出现一种情况:其他的线程都执行得很流畅,突然有一个线程就卡住了,并且卡了很长的时间,此时这个线程就可能触发了哈希表的扩容,这个扩容过程持续的时间很长
ConcurrentHashMap和Hashtable的区别
ConcurrentHashMap是线程安全的,并且在多线程编程中ConcurrentHashMap 是比Hashtable实用很多的
ConcurrentHashMap相比于Hashtable做了很多的优化
1.
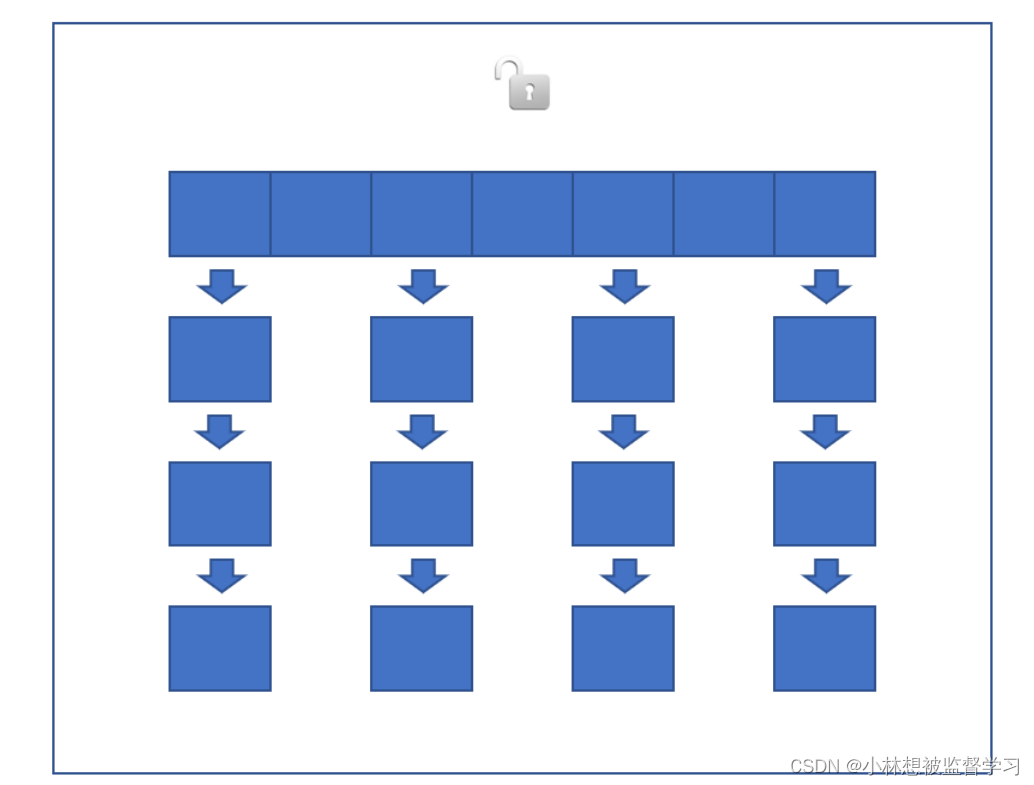
读操作没有加锁,只对写操作加锁,加锁用的也是synchronized,但是不是直接在方法上进行加锁,而是针对哈希表上的每个链表加锁,并且加锁用的也不是this对象,而是直接用每个链表的头结点作为锁对象进行加锁,相当于哈希表上每个链表都有各自的锁对象
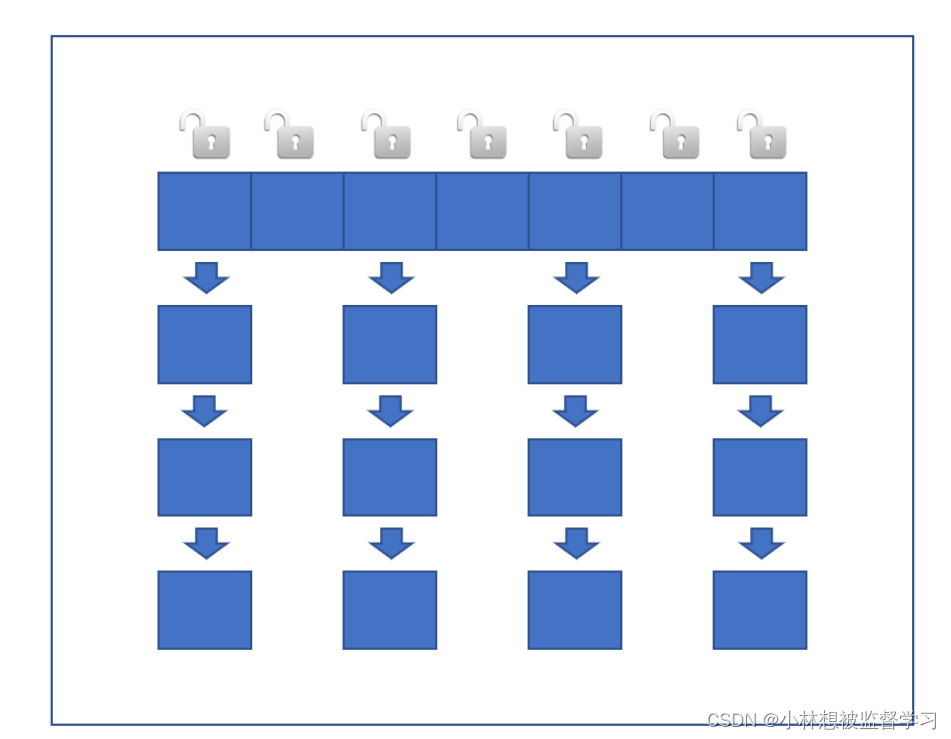
为什么要这样设计呢?
因为多个线程对哈希表进行访问时,如果访问的是哈希表上不同的链表,实际上是不会出现线程安全问题的,只有多个线程访问哈希表上的同一个链表才会出现线程安全问题,所以我们不需要对整个哈希表加锁,我们只需要对每个链表进行加锁即可
加这么多锁不会消耗很多资源吗?
可能会有细心的小伙伴有这样的问题,但实际上我们用synchronized进行加锁时,一开始加上的是一个偏向锁,偏向锁就相当于是一个标记,此时并没有真正的实例化一个锁出来,也就没有消耗什么资源,只有当多个线程争夺同一把锁(出现锁竞争)时才会去真正的实例化具体的锁,而实际上多个线程去修改同一个链表上的数据,这种情况是很少发生的,所以我们加上的锁大多数都只是一个偏向锁,不消耗什么资源
2.
充分利用 CAS 特性. 比如 size 属性通过 CAS 来更新. 避免出现重量级锁的情况.(关于CAS推荐看CAS的ABA问题)
3.
优化了扩容方式,化整为零
当莫一个线程触发了哈希表的扩容操作,此时不需要这个线程完成所有的扩容过程,当前这个线程只需要创建一个更大的哈希表,然后搬运一小部分数据即可
在扩容的期间,新旧数组是同时存在的,之后每个访问ConcurrentHashMap的线程都会参与对数据的搬运,每个操作负责搬运一部分元素
在这个期间,我们修改数据会将数据直接修改到新数组上,添加数据会直接添加到新数组上,查找数据是新旧数组一起查找
当旧数组上的数据被全部搬运完成后,便会删除旧数组
ConcurrentHashMap的锁分段技术
简单的说就是把若干个哈希桶分成一个 "段" (Segment), 针对每个段分别加锁. 目的也是为了降低锁竞争的概率. 当两个线程访问的数据恰好在同一个段上的时候, 才触发锁竞争.,但现在锁分段技术技术已经被淘汰了,因为要对哈希表的链表进行分段,管理起来是很麻烦的,不如直接对每个链表进行加锁(锁对象是链表的头结点)






![删除文件PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。](https://img-blog.csdnimg.cn/e2e80b153bfb4f1a8ec5373441b805c7.png)