关于网络爬虫,其实就是模拟浏览器向网站服务器发送请求,然后从响应的结果中提取出需要的数据。那么,该如何实现这一流程了?对于初学者来说,可能都不知道该如何入手,学习爬虫时需不需要了解HTTP、TCP、IP 层的网络传输通信和知道服务器的响应和应答原理,以及请求的这个数据结构需要自己实现吗,等等一系列问题产生疑惑。
不用担心,Python的强大之处就是提供了功能齐全的类库来帮助我们完成这些请求。最基础的 HTTP 库有 urllib、httplib2、requests、treq 等。就以 requests 库来说,有了它,我们只需要关注请求的链接是什么,需要传什么参数,以及如何设置请求头就可以了,不用深入地去看它的底层是怎样传输和通信的。
接下来,本篇内容中,笔者将先讲解如何使用Python里面的网络请求库对指定的网站地址发起一个请求并获取响应结果。然后讲解从结果中根据规则提取出指定的信息。
本篇主要涉及的知识点
□ 网络请求库的使用
□ 使用xpath表达式提取网页数据
□ 使用正则表达式提取数据
1.Python内置网络请求库 urllib
urllib 是 Python 中内置的一个用于网络请求的库,通过它可以实现模拟浏览器发送 HTTP 请求和获取请求返回结果等。本文将对 urllib 的基本使用进行讲解和演示。零基础读者在学习过程中可以跟着案例一边学习,一边动手操作。
1.1 请求一个简单的网页
在学习如何使用 urllib 发起网络请求之前,我们先来看一个网页,看看它的页面和源码长什么样,以百度百科的首页地址为例:
https://baike.baidu.com/
使用浏览器打开该网址之后,会出现如图1所示的页面。

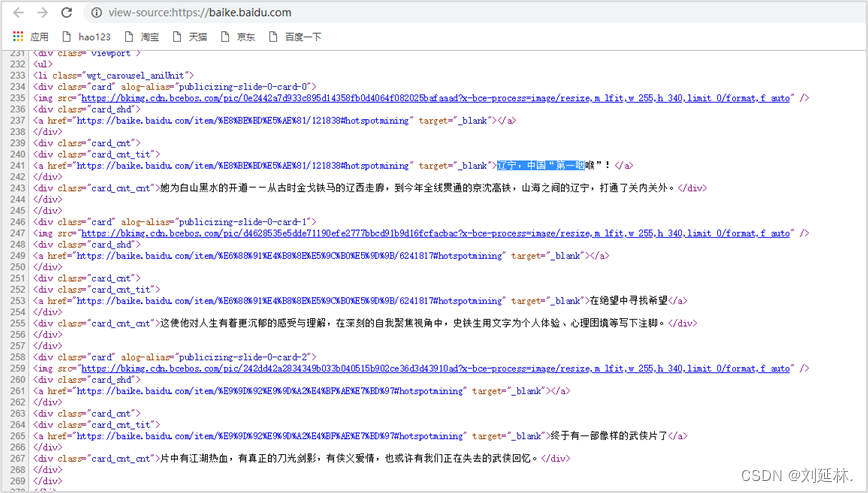
接着,再在页面任意位置上鼠标右击,在弹出的快捷菜单中选择【查看网页源码】命令,即可查看到该网页的 HTML 源代码,如图2所示。
接下来我们的目标是要使用 urllib 库模拟浏览器发起一个 HTTP 请求去获取此网页源码,得到的内容要跟我们直接在浏览器上看到的源码一样。要实现这个功能,就需要用到 urllib.request 模块。 通过 urllib.request 模块的 urlopen() 方法就可以对网页发起请求和获取返回结果。语法格式如下:
urllib.request.urlopen(
url,
data=None,
[timeout, ]*,
cafile=None,
capath=None,
context=None
)从语法格式中可以看到,在使用 urlopen() 方法的时候,需要传递很多的参数,事实上大多数时候只需要关注前面的 url、data、timeout 这 3 个参数就行。这些参数的具体含义如下。
(1)url 参数:String 类型的地址,也就是我们要访问的 URL。
(2)data:参数指的是在请求的时候,需要提交的数据。
(3)timeout:参数用于设置请求超时时间,单位是秒。
(4)cafile 和 capath:代表 CA 证书和 CA 证书的路径,如果使用 HTTPS,则需要用到。
(5)context 参数:用来指定 SSL 设置,必须是 ssl.SSLContext 类型。
这里只是为了获取该网页的源码,所以只需要传入 url 参数进行请求即可。请求完之后,会返回一个结果,再通过这个结果的 read() 方法便可以获取到真正的网页源码,示例代码如下:
import urllib.request
url = "https://baike.baidu.com/"
response = urllib.request.urlopen(url)
html = response.read()
print(html.decode('utf-8'))通过示例代码可看到,在使用 urllib.request 模块之前,需要先使用 import 关键词进行导入。同 理,在本书后面其他的示例代码中也是一样的,特别是新手读者需要多注意,在使用任何模块或库的时候,都需要先导入。在请求获取返回结果之后,如果在控制台输出打印发现有乱码,需要对结果进行解码,如上面代码中所示的decode()方法可以对字符串进行解码。运行代码结果如图3所示。

观察结果中的内容可以发现,我们通过 urllib.request.urlopen() 方法发起请求拿到的结果跟在浏览器中看到的一模一样。至此,我们已经完成使用 urllib.request 模块实现请求第一个网页。
1.2 设置请求超时
在访问网页时常常会碰到这样的情况,因为某些原因,比如自己电脑网络慢或对方网站服务器压力大等,导致在打开网页或刷新的时候迟迟无法得到响应。同样,在程序中去请求的时候也会遇到这样的问题。因此我们可以手动设置超时时间。当爬虫程序在请求某一网站时,迟迟无法获得响应内容,可以采取进一步措施,例如,选择直接丢弃该请求或再请求一次。为了应对这个问题,在 urllib.urlopen() 中可以通过 timeout 这个参数去设置超时时间。下面还是以请求前面给的网页为例, 设置如果请求超过 3 秒未响应内容,就舍弃它或重新尝试访问。示例代码如下:
import urllib.request
url = "https://baike.baidu.com/"
response = urllib.request.urlopen(url,timeout=3)
html = response.read()
print(html.decode('utf-8'))1.3 使用data参数提交数据
urlopen() 方法里面的参数除了 url、timeout 之外,还有 data 参数也比较常用,data 参数是可选的。 如果要添加 data,它必须是字节流编码格式的内容,即 bytes 类型,通过 bytes() 函数可以进行转化。 另外,如果传递了这个 data 参数,它的请求方式就不再是 GET 方式请求,而是 POST 。所以一般在访问的网站需要使用 post 请求获取数据的情况下,才会传递 data 参数。这里查阅了一个网址可 以进行测试:http://httpbin.org。通过使用 POST 方式访问它的 http://httpbin.org/post 路径并且传递一个参数 word 和值,即可获取类似以下的响应内容. 如图4所示。

接下来我们使用代码实现这个过程,需要使用 urllib.parse.urlencode() 方法将要提交的 data 字典数 据转化为字符串,再使用 bytes()方法转换为字节流,最后使用 urlopen()方法发起请求,示例代码如下:
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word': '22222'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())运行输出结果:
b'{\n "args": {}, \n "data": "", \n "files": {}, \n "form": {\n "word": "22222"\n }, \n "headers": {\n "Accept-Encoding": "identity", \n "Content-Length": "10", \n "Content-Type": "application/x-www-form-urlencoded", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.10", \n "X-Amzn-Trace-Id": "Root=1-628a5cd3-2cfb1c893b672ba6115f0fbe"\n }, \n "json": null, \n "origin": "61.141.253.53", \n "url": "http://httpbin.org/post"\n}\n'1.4 Request方法
通过前面的知识知道,利用 urlopen() 方法可以发起简单的请求,但 urlopen() 这几个简单的参 数并不足以构建一个完整的请求,如果请求中需要加入 headers(请求头)、指定请求方式等信息, 我们就可以利用 urllib.request 模块中更强大的 Request 类来构建一个请求。其语法格式如下:
urllib.request.Request(
url,
data=None,
headers={},
origin_req_host=None,
unverifiable=False,
method=None
)
同样,通过语法格式可以看到,在使用 Request 方法的时候,也需要传递一些参数,这些参数 的含义如下。
(1)url 参数:请求链接,这个是必传参数,其他的都是可选参数。
(2)data 参数:跟 urlopen() 中的 data 参数用法相同。
(3)headers 参数:指定发起的 HTTP 请求的头部信息。headers 是一个字典。它除了在 Request 中添加,还可以通过调用 Request 实例的 add_header() 方法来添加请求头。
(4)origin_req_host 参数:指的是请求方的 host 名称或 IP 地址。
(5)unverifiable 参数:表示这个请求是否合法,默认值是 False。意思就是说用户没有足够权 限来选择接收这个请求的结果。例如,我们请求一个 HTML 文档中的图片,但是没有自动抓取图 像的权限,就要将 unverifiable 的值设置成 True。
(6)method 参数:指的是发起的 HTTP 请求的方式,有 GET、POST、DELETE、PUT 等。 下面使用它请求一下 https://www.baidu.com 这个网址,网页源码如图 5 所示。

编写代码,首先直接通过 urllib.request.Request() 方法只传入 url 这个参数进行请求,获取百度 首页的源码,示例代码如下:
import urllib.request
url = "https://www.baidu.com"
request = urllib.request.Request(url=url)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))运行代码之后,发现返回的结果与浏览器上看到的并不一样,如图 6 所示,只返回了少量的 几行代码,而且内容也跟图 5 所示的对不上。这是为什么呢?
这是因为百度这个网站对请求的 headers 信息进行了验证,我们直接使用 Request()方法进行请 求,默认的 User-Agent 是 Python-urllib/ 版本号,百度会识别出来是程序在访问,所以会对其进行 拦截。这时候就需要对 headers 进行伪装,伪装成浏览器上的 header 信息。所以当我们在请求的时候, 就需要传递一个 headers 参数,才能正确地拿到结果。例如下面的示例代码所示,这里将自己的 headers 信息里面的 User-Agent 伪装成了跟浏览器上的一样。
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/56.0.2924.87Safari/537.36'
}
url = "https://www.baidu.com"
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))修改代码,在加上 headers 参数之后,再次运行代码发起请求,将会发现返回的百度首页源代码已经正常了,跟浏览器上看到的一模一样,如图 7 所示。
除此之外,Request方法还可以传递一些其它的参数,不过都不太常用,笔者这里不做讲解,有兴趣的读者可以查阅相关资料进行了解。
下一篇文章:Python第三方网络请求库requests


![kali 安装AWVS [赠附件]](https://img-blog.csdnimg.cn/img_convert/295aba7090e9806b6b5e1fc61daf4e58.png)