从人类反馈中强化学习(RLHF)在使大型语言模型(LLMs)与人类偏好保持一致方面非常有效,但收集高质量的人类偏好标签是一个关键瓶颈。我们进行了RLHF与来自AI反馈的强化学习(RLAIF)的头对头比较 - RLAIF是一种技术,在这种技术中,偏好由现成的LLM标注,而不是由人类标注,我们发现它们导致类似的改进效果。在摘要任务中,人类评估者在约70%的情况下更喜欢RLAIF和RLHF生成的结果,而不是基线的监督微调模型。此外,当被要求评价RLAIF与RLHF的摘要时,人类以相等的比例偏好两者。这些结果表明,RLAIF可以实现人类水平的性能,为解决RLHF的可扩展性限制提供了潜在的解决方案
“从人类反馈中学习的强化学习(RLHF)哦“是一种有效的技术,用于使语言模型与人类偏好保持一致,并被引用为现代对话语言模型(如ChatGPT和Bard)成功的关键驱动因素之一。通过使用强化学习(RL)进行训练,语言模型可以在传统的监督微调中难以区分的复杂序列级目标上进行优化。
对于扩展RLHF,高质量的人工标签是一个障碍,一个自然的问题是人工生成的标签是否能够获得可比较的结果。一些研究已经表明,大型语言模型(LLMs)与人类判断高度一致 - 甚至在某些任务上超过人类。Bai等人首次探索了使用AI偏好来训练RL微调所使用的奖励模型的技术 - 这一技术称为“从AI反馈中学习的强化学习”(RLAIF)1。虽然他们表明,将人类和AI偏好的混合与“宪法AI”自我修正技术结合使用超越了监督微调的基线,但他们的工作并未直接比较人类和AI反馈的有效性,因此没有回答RLAIF是否可以成为RLHF的合适替代品的问题。
在这项工作中,我们直接比较了RLAIF和RLHF在摘要任务上的表现。给定一段文本和两个候选回应,我们使用现成的LLM分配一个偏好标签。然后,我们使用对比损失在LLM偏好上训练奖励模型(RM)。最后,我们使用RM提供奖励,使用强化学习微调策略模型。
我们的结果显示,RLAIF在两个方面的表现与RLHF相当。首先,我们观察到,人们在71%和73%的时间内分别更喜欢RLAIF和RLHF策略,而这两种胜率在统计上没有显着差异。其次,当被要求直接比较RLAIF与RLHF的生成时,人们以相等的比例(即50%的胜率)偏好两者。这些结果表明,RLAIF是RLHF的可行替代品,不依赖于人工标注,并具有吸引人的扩展性。
此外,我们研究了最大程度地提高AI生成的偏好与人类偏好一致性的技术。我们发现,用详细的说明提示我们的LLM,并征求思维链的推理可以提高一致性。令人惊讶的是,我们观察到,少量样本的上下文学习和自一致性 - 一个过程,在这个过程中,我们采样多个思维链的理由,并平均最终的偏好 - 不会提高准确性,甚至会降低准确性。最后,我们进行了扩展实验,以量化LLM标签制作者的规模和用于训练的偏好示例数量与与人类偏好一致性之间的权衡。
我们的主要贡献如下:
我们展示了RLAIF在摘要任务上实现了与RLHF相媲美的性能。
我们比较了用于生成AI标签的各种技术,并确定了RLAIF从业者的最佳设置。

实现结果
RLAIF vs. RLHF
我们的结果显示,RLAIF在性能上与RLHF相似。RLAIF在71%的情况下被人类评估者优选于基线的SFT策略。相比之下,RLHF在73%的情况下优于SFT。虽然RLHF略微优于RLAIF,但这种差异在统计上并不显著4。我们还直接比较了RLAIF与RLHF的胜率,发现它们被同样偏好 - 即胜率为50%。
我们还比较了RLAIF和RLHF的摘要与人工编写的参考摘要。RLAIF摘要在79%的情况下优于参考摘要,而RLHF在80%的情况下优于参考摘要。RLAIF和RLHF相对于参考摘要的胜率差异也在统计上不显著。
我们结果中的一个混淆因素是,我们的RLAIF和RLHF策略倾向于生成比SFT策略更长的摘要,这可以解释一部分质量改进。与Stiennon等人(2020)类似,我们进行事后分析,表明尽管RLAIF和RLHF策略都受益于生成更长的摘要,但在控制长度后,它们仍然以相似的幅度优于SFT策略。
这些结果表明,RLAIF是RLHF的一个可行替代方案,不依赖于人工标注。为了了解这些发现在其他自然语言处理任务中的普适性如何,需要在更广泛的任务范围上进行实验,这将留待未来的工作。
Prompt技术
我们进行了三种类型的提示技术实验 - 前导具体性,思维链推理和少样本上下文学习 - 并在表2中报告了结果。使用详细的OpenAI前导文本提高了对齐性+1.3%(77.4%的“OpenAI 0-shot”比76.1%的“Base 0-shot”高),而思维链推理提高了对齐性+1.4%(77.5%的“Base + COT 0-shot”比76.1%的“Base 0-shot”高)。虽然将这两种技术结合使用的改进效果不及它们各自的增益之和,但这些技术仍然是互补的,共同带来了+1.9%的改进。
我们观察到,少样本上下文学习并不提高对齐性,甚至可能降低对齐性。对于“OpenAI + COT k-shot”提示,我们看到准确性随着k从0增加到2而单调下降。一个假设是,LLM能够在自身生成更有用的思维链合理性,而不是遵循我们的1-shot和2-shot示例中给出的思维链合理性。
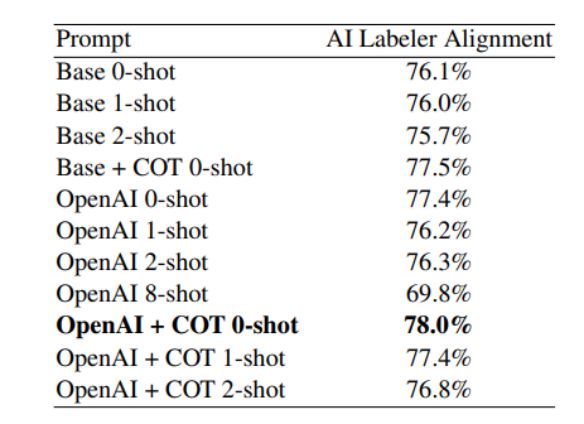 为了了解是否添加更多示例可能会带来改进,我们进行了一个8-shot提示的实验,并发现准确性下降了-7.6%(69.8%的“OpenAI 8-shot”比77.4%的“OpenAI 0-shot”低)。我们验证了在这个实验中使用的所有示例都符合我们的AI标签制作者的上下文长度。
为了了解是否添加更多示例可能会带来改进,我们进行了一个8-shot提示的实验,并发现准确性下降了-7.6%(69.8%的“OpenAI 8-shot”比77.4%的“OpenAI 0-shot”低)。我们验证了在这个实验中使用的所有示例都符合我们的AI标签制作者的上下文长度。
总体而言,我们观察到最佳配置包括详细的前导文本,思维链推理和不进行上下文学习(“OpenAI + COT 0-shot”)。这种组合实现了78.0%的AI标签制作者对齐度,比使用我们最基本的提示(“Base 0-shot”)高出+1.9%。
作为对比,Stiennon等人(2020)估计人类间标注者在人类偏好数据集上的一致性为73-77%,这表明我们的LLM表现相当不错。我们在所有其他实验中使用“OpenAI + COT 0-shot”提示。
自一致性

我们在自一致性方面进行了实验,使用了4个和16个样本,解码温度设置为1,如第3.1.3节所述。在这两种设置下,对比不使用自一致性,都显示出对齐性下降超过-5%。人工检查思维链合理性并没有发现自一致性可能导致准确性降低的常见模式。
准确性下降的一个假设是,使用温度为1会导致模型生成较低质量的思维链合理性,与贪婪解码相比,最终导致整体准确性下降。使用介于0和1之间的温度可能会产生更好的结果。
LLM标签制作者的规模 大型模型的规模通常不容易获得,并且可能运行速度较慢、成本较高。我们进行了使用不同模型规模来标记偏好的实验,并观察到对齐性与模型规模之间存在强烈的关系。当从PaLM 2 Large (L)转向PaLM 2 Small (S)时,对齐性下降了-4.2%,当继续转向PaLM 2 XS时,又下降了-11.1%。这个趋势与其他研究中观察到的扩展规律一致(Kaplan等人,2020)。导致性能下降的一个因素可能是较小的LLM中位置偏差的增加。
大型模型的规模通常不容易获得,并且可能运行速度较慢、成本较高。我们进行了使用不同模型规模来标记偏好的实验,并观察到对齐性与模型规模之间存在强烈的关系。当从PaLM 2 Large (L)转向PaLM 2 Small (S)时,对齐性下降了-4.2%,当继续转向PaLM 2 XS时,又下降了-11.1%。这个趋势与其他研究中观察到的扩展规律一致(Kaplan等人,2020)。导致性能下降的一个因素可能是较小的LLM中位置偏差的增加。
在这个趋势的尽头,这些结果还表明,增加AI标签制作者的规模可能会产生更高质量的偏好标签。由于AI标签制作者仅在生成偏好示例时使用一次,并且在RL训练期间不进行查询,因此使用更大的AI标签制作者不一定会带来不可承受的成本。此外,第5.5节表明,少量示例可能足以训练强大的奖励模型(例如,大约O(1k)的数量级),从而进一步降低使用较大标签制作者模型的成本。
Preference Examples的数量
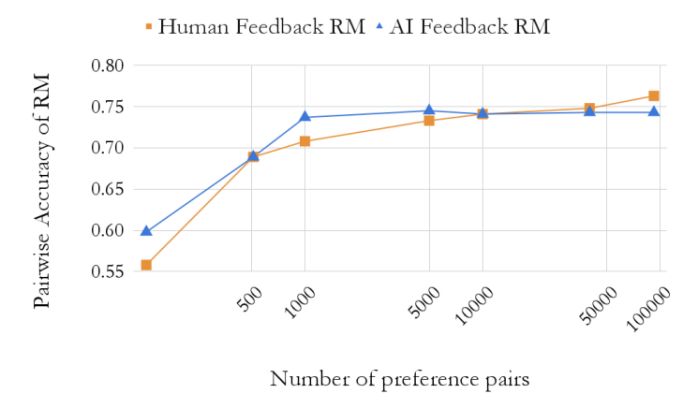
在这段文本中,提到进行了一系列实验来了解RM的准确性如何随着训练示例数量的变化而变化。他们使用不同数量的AI标记的偏好示例来进行训练,并在一组人类偏好的保留集上评估成对准确性。通过对全套偏好数据集进行随机子采样,获得不同数量的训练示例。实验结果在图5中显示。
他们观察到,在训练了几千个示例后,AI偏好RM的性能很快趋于稳定。当仅使用128个示例进行训练时,RM的准确性约为60%,然后当仅使用5,000个示例进行训练时(大约是全套数据集的1/20)准确性接近于使用完整数据集进行训练时的准确性。
他们还在人类偏好上进行了一组平行实验。他们发现人类偏好和AI偏好的RM遵循类似的扩展曲线。一个不同之处是,随着训练示例数量的增加,人类偏好的RM似乎会持续改善,尽管更多的训练示例只会带来小幅的准确性提高。这一趋势表明,受过AI偏好训练的RM可能不会像受过人类偏好训练的RM那样从增加训练示例数量中受益。
考虑到增加AI偏好示例数量所带来的有限改进,更多的资源可能最好用于使用更大的模型规模进行标记,而不是标记更多的偏好示例。
结论
在这项工作中,我们展示了RLAIF在不依赖于人工标注的情况下可以产生与RLHF相媲美的改进。我们的实验表明,RLAIF在很大程度上优于SFT基线,改进幅度与RLHF相当。在头对头的比较中,人们对RLAIF和RLHF的偏好率相似。我们还研究了各种AI标注技术,并进行了扩展研究,以了解生成一致的偏好的最佳设置。
尽管这项工作突显了RLAIF的潜力,但我们需要注意这些发现的一些局限性。首先,这项工作只探讨了摘要任务,对于其在其他任务上的泛化性留下了一个开放的问题。其次,我们没有估算LLM推理在经济成本方面是否有优势,与人工标注相比。此外,还存在许多有趣的未解问题,例如RLHF与RLAIF的结合是否可以优于单一方法,直接使用LLM分配奖励的效果如何,提高AI标签制作者的对齐度是否能够转化为改进的最终策略,以及使用与策略模型大小相同的LLM标注器是否可以进一步改进策略(即模型是否能够“自我改进”)。我们将这些问题留待未来的研究。
我们希望本文能激发在RLAIF领域的进一步研究。








![【java】【项目实战】[外卖十二]【完结】项目优化(前后端分离开发)](https://img-blog.csdnimg.cn/00a39f852e854930b1f8ca3e1fad12c2.png)