分布式系统将数据复制到多个服务器上,以获得更好的容错性、可扩展性和可靠性。一致性模式(一致性模型)是一组用于在分布式系统中进行数据存储和数据管理的技术。一致性模式决定了数据在分布式系统中的传播。因此,一致性模式将影响分布式系统的可扩展性和可靠性。
在分布式系统中有许多一致性模式。选择哪种一致性模式取决于系统的需求和使用案例,因为每种一致性模式都有其优点和缺点。一致性模式必须是多数据中心系统架构的核心,因为在多个数据中心之间维护一致性并不是一个简单的任务。一致性模式可以大致分为以下几类:
-
强一致性
-
最终一致性
-
弱一致性
对于重视高可用性和性能而不是一致性的分布式系统,最终一致性模型是最佳选择。当需要在分布式系统中无延迟地查看相同的数据视图时,强一致性是最佳的一致性模型。总的来说,每种一致性模型都适用于不同的使用案例和系统要求。
更多技术干货请关注公号【云原生数据库】
强一致性
在强一致性模式中,对任何服务器执行的读操作必须始终检索包含在最新写操作中的数据。强一致性模式通常在多个服务器之间同步复制数据。换句话说,当在服务器上执行写操作时,其他每个服务器上的后续读操作必须返回最新写入的数据。
强一致性的好处如下:
-
简化应用程序逻辑。
-
增加数据持久性。
-
保证系统各处的一致数据视图。
强一致性的局限性如下:
-
服务的可用性降低。
-
延迟增加。
-
资源密集型。
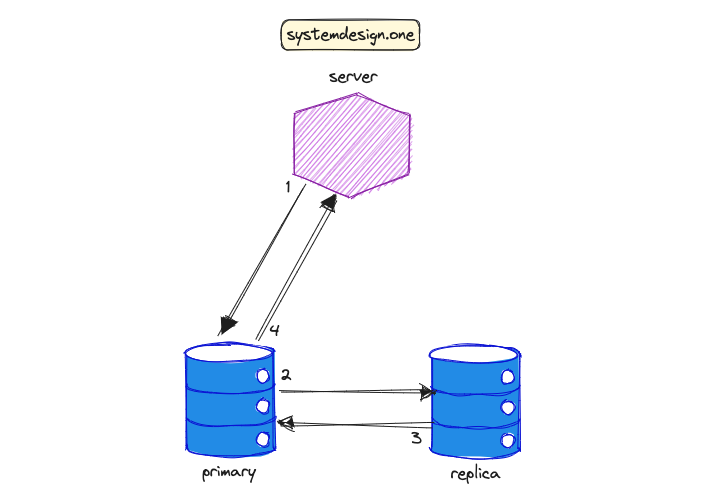
强一致性
为了在数据复制中达到强一致性,工作流程如下:
-
服务器(客户端)对主数据库实例执行写操作。
-
主实例将写入的数据传播到副本实例。
-
副本实例向主实例发送确认信号。
-
主实例向客户端发送确认信号。
强一致性模型的典型用例如下:
-
文件系统。
-
关系数据库。
-
如银行等金融服务。
-
半分布式共识协议,如两阶段提交(2PC)。
-
完全分布式共识协议,如Paxos。
例如,用户的银行账户余额的任何变化都必须立即复制以提高持久性和可靠性。Google的Bigtable和Google的Spanner数据库是强一致性的实际应用。
最终一致性
在最终一致性模式中,当对服务器执行写操作时,对其他服务器执行的立即后续读操作不一定返回最新写入的数据。系统最终会收敛到相同的状态,其他服务器在后续的读操作中会返回最新的数据。最终一致性模式通常在多个服务器之间异步复制数据。用通俗的话说,任何数据更改只会最终在系统中传播,预期在数据收敛发生之前都会出现旧的数据视图。
最终一致性可以通过多主或无主复制拓扑实现。
系统通常在几秒钟内收敛到相同的状态,但时间框架取决于实现和系统要求。最终一致性模式的好处如下:
-
简单。
-
高可用性。
-
可扩展。
-
低延迟。
最终一致性的缺点如下:
-
较弱的一致性模型。
-
潜在的数据丢失。
-
潜在的数据冲突。
-
数据不一致。
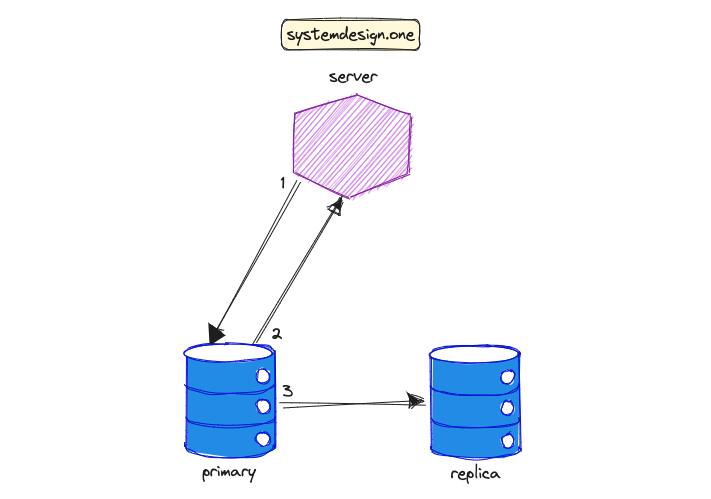
最终一致性
为了在数据复制中实现最终一致性,工作流程如下:
-
客户端对主数据库实例执行写操作。
-
主实例向客户端发送确认信号。
-
主实例最终将写入的数据传播到副本实例。
最终一致性模式是数据过时性和可扩展性之间的权衡。最终一致性的典型用例如下:
-
搜索引擎索引。
-
URL缩短器。
-
域名服务器(DNS)。
-
简单邮件传输协议(SMTP)。
-
例如Amazon S3的对象存储。
-
例如Facebook上的评论或帖子。
-
分布式通信协议,如流言协议。
-
领导者-跟随者和多领导者复制。
-
分布式计数器和实时评论服务。
例如,域名记录的任何更改都会被DNS最终复制。如Amazon Dynamo和Apache Cassandra的分布式数据库是最终一致性模式的实际应用。最终一致性不是设计缺陷,而是为满足某些使用案例而提供的功能。业务所有者应确定应用数据是否适合最终一致性模式。
弱一致性
在弱一致性模式中,当对服务器执行写操作时,对其他服务器执行的后续读操作可能返回或不返回最新写入的数据。换句话说,执行了最大努力的数据传播 - 数据可能不会立即传播。在可以返回最新写入的数据之前,分布式系统必须满足各种条件,如时间的流逝。
弱一致性的优点如下:
-
高可用性。
-
低延迟。
弱一致性的缺点如下:
-
可能的数据丢失。
-
数据不一致。
-
数据冲突。

弱一致性
写后缓存(写回)模式是弱一致性的一个例子。如果缓存在将数据传播到数据库之前崩溃,则数据将丢失。写后缓存模式的工作流程如下:
-
客户端对缓存服务器执行写操作。
-
缓存将接收到的数据写入消息队列。
-
缓存向客户端发送确认信号。
-
事件处理器异步将数据写入数据库。
弱一致性的常见用例如下:
-
实时多人视频游戏。
-
互联网电话协议 (VoIP)。
-
实时流。
-
缓存服务器。
-
数据备份。
例如,由于网络连接差导致的直播流中的丢失的视频帧不会重新传输。
一致性模式的权衡
与每种一致性模式相关的权衡可以概述如下:
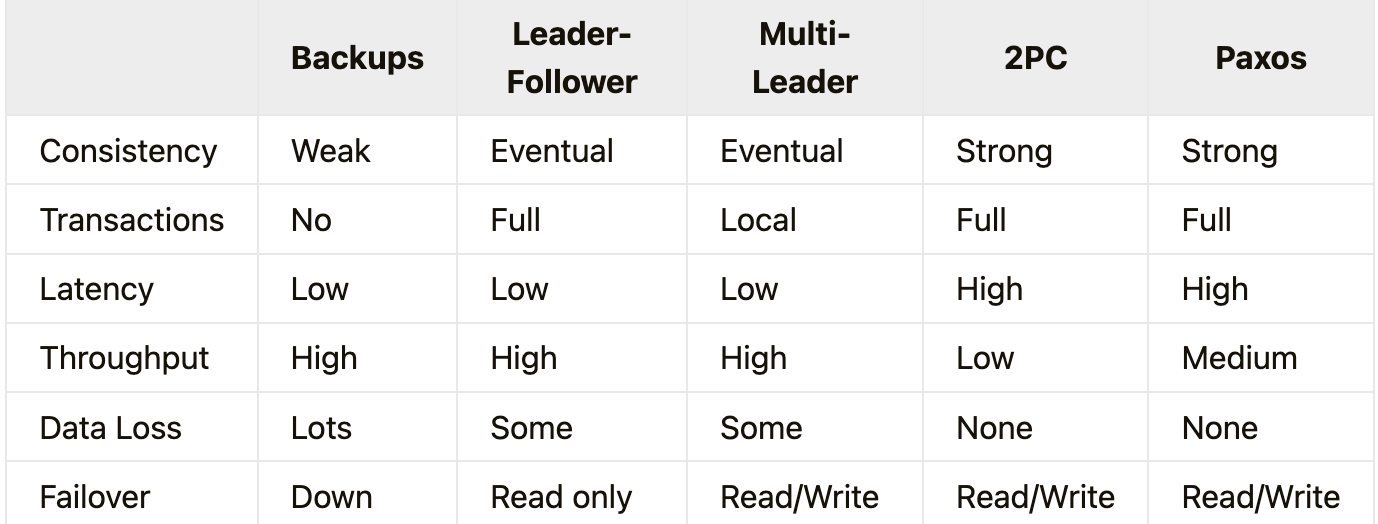
布式系统中的其他一致性模型
分布式仲裁可以用来实现各种一致性模式。仲裁参数的配置决定了将实现的一致性模式。
线性化
在线性化模式中,写入服务器的数据必须立即可见(在写操作的开始和结束之间)给其他服务器的后续读操作。线性化是强一致性的一个变体,也被称为原子一致性。以下技术可用于实现线性化:
-
单一领导者同时处理读和写操作。
-
分布式共识算法如Paxos。
-
分布式仲裁。
线性化的优点如下:
-
使分布式系统表现得像非分布式系统。
-
应用程序使用简单。
线性化的缺点如下:
-
性能下降。
-
有限的可扩展性。
-
可用性降低。
线性化模式的一个流行用例是在分布式系统中实现用户ID字段的唯一性约束。
因果一致性
在因果一致性模式中,其他服务器准确地观察到相关的事件(因果关系),而与其他服务器无关的事件可能没有特定的顺序被观察到。因果一致性是最终一致性的一个变体,并在最终一致性和强一致性之间出现为中间地带。在实时并行发生的因果无关的写操作被称为并发事件。因果一致性模式不保证并发事件的顺序。
因果一致性模式中的因果关系可以通过向量时钟来实现。因果一致性的好处如下:
-
低延迟。
-
降低同步成本。
-
高可用性。
-
相对更强的一致性。
因果一致性模式的广泛用例如下:
-
Apache Cassandra提供带有因果一致性的轻量级事务。
-
Bayou分布式数据库中的数据传播。
-
Reddit上的评论线程。
例如,在Reddit上对同一评论线程的回复必须因果有序。但是,无关的评论线程可以按任何顺序显示。因果一致性模式也用于例如Slack的实时聊天服务。
总结
在同一个分布式系统的不同部分可以使用多种一致性模式。在选择合适的一致性模式时,没有银弹,只有权衡。一致性模式的最佳选择取决于特定的用例和要求。
Squids DBMotion,专业的数据库迁移、同步、校验工具~