1、SDS:动态字符串
src/sds.h:50
struct sdshdr {
// 记录buf数组中已使用的字节数,即SDS字符串长度
int len;
// 记录buf数组中未使用的字节数
int free;
// 字节数组,用于保存字符串
char buf[];
}
- 杜绝缓冲区溢出。
- 减少修改字符串长度时所需的内存重分配次数。
- 二进制安全。
- 兼容部分C字符串函数。
2、链表
src/adlist.h:68
/*
* 双端链表节点
*/
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;

- 双端:链表节点带有 prev 和 next 指针,获取某个节点的前置节点和后置节点的复杂度都是 O(1)。
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点。
- 带表头指针和表尾指针:通过 list 结构的 head 指针和 tail 指针,程序获取链表的表头节点和表尾节点的复杂度为 O(1)。
- 带链表长度计数器:程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数,程序获取链表中节点数量的复杂度为 O(1)。
- 多态:链表节点使用 void* 指针来保存节点值,并且可以通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
链表被广泛用于实现 Redis 的各种功能,比如列表键、发布与订阅、慢查询、监视器等。
3、字典
Redis中字典使用的是hash表来作为底层实现,每个字典有两个hash表,一个平时使用,另一个仅仅在rehash使用。
Redis使用MurmurHash2算法来计算哈希值,使用链地址法来解决键冲突,即发生hash冲突的时候,以链表的方式存储键值对。
采取渐进式hash方式进行收缩或者扩容。

/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
/*
* 字典类型特定函数
*/
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
/*
* 字典迭代器
*
* 如果 safe 属性的值为 1 ,那么在迭代进行的过程中,
* 程序仍然可以执行 dictAdd 、 dictFind 和其他函数,对字典进行修改。
*
* 如果 safe 不为 1 ,那么程序只会调用 dictNext 对字典进行迭代,
* 而不对字典进行修改。
*/
typedef struct dictIterator {
// 被迭代的字典
dict *d;
// table :正在被迭代的哈希表号码,值可以是 0 或 1 。
// index :迭代器当前所指向的哈希表索引位置。
// safe :标识这个迭代器是否安全
int table, index, safe;
// entry :当前迭代到的节点的指针
// nextEntry :当前迭代节点的下一个节点
// 因为在安全迭代器运作时, entry 所指向的节点可能会被修改,
// 所以需要一个额外的指针来保存下一节点的位置,
// 从而防止指针丢失
dictEntry *entry, *nextEntry;
long long fingerprint; /* unsafe iterator fingerprint for misuse detection */
} dictIterator;
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
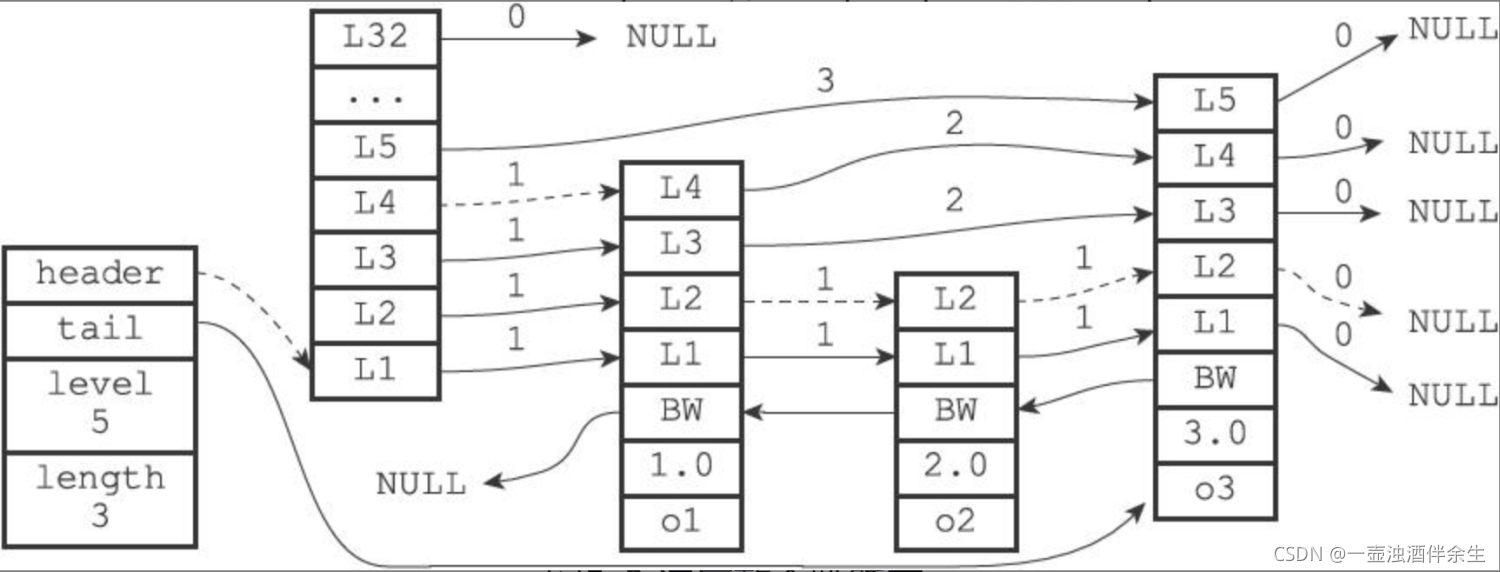
4、跳跃表
/* ZSETs use a specialized version of Skiplists */
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
5、整数集合

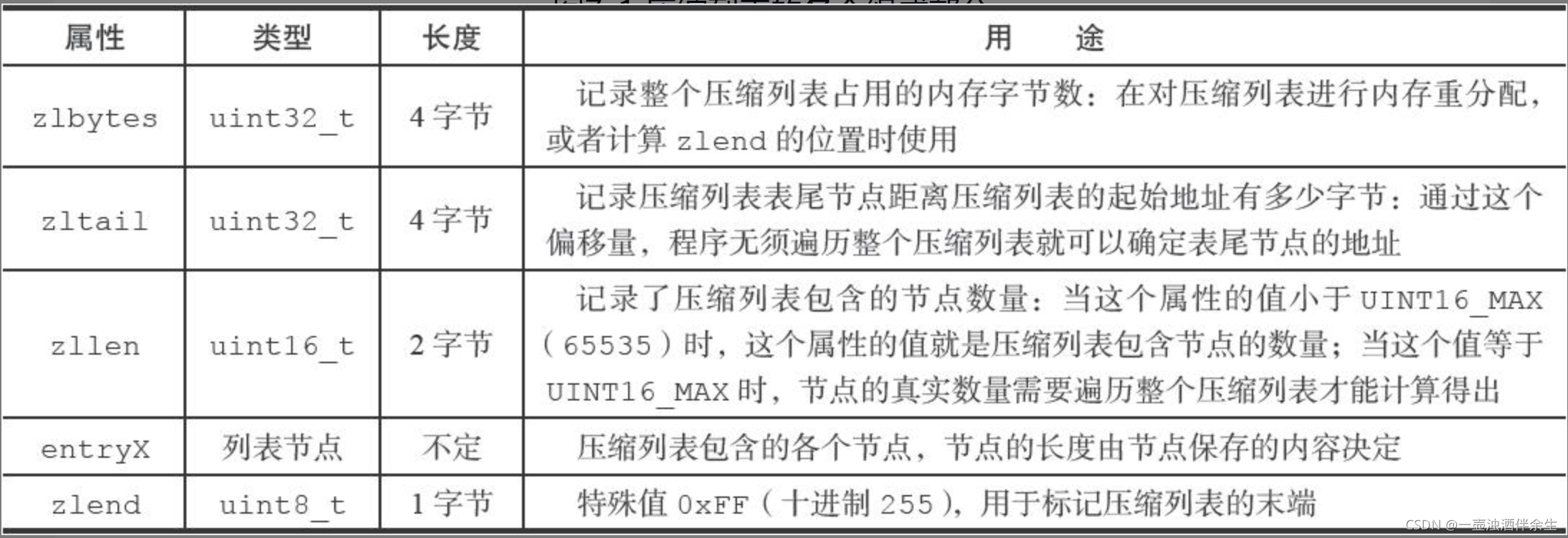
7、压缩表







![[附源码]Nodejs计算机毕业设计基于社区人员管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/68b5707b3b674272844e3cb4ff4d5819.png)


![[go]分布式系统之snowflake与锁](https://img-blog.csdnimg.cn/c0e566cdad434679a6643237e9488009.png#pic_center)


![[附源码]Node.js计算机毕业设计孤儿院救助平台Express](https://img-blog.csdnimg.cn/f1c57db5c77048ca941617a082e60b28.png)