创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!!
主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步!
更多算法分析与设计知识专栏:算法分析🔥
给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ

目录
- 一、分治法的基本思想
- 二、分治法的基本步骤
- 三、分治法的复杂性分析
- 分治法实现——二分搜索
- 二分搜索的时间复杂性
一、分治法的基本思想
分治法它的基本思想是将一个大问题分解成若干个与原问题相似的小问题,用相同的方法递归地解决这些小问题,最后将这些小问题的解合并起来,得到原问题的解决方案。
分治法所能解决的问题一般具有以下特征:
-
该问题的规模缩小到一定的程度就可以容易地解决。
因为问题的计算复杂性一般是随着问题规模的增加而增加,因此大部分问题满足这个特征。 -
该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
这条特征是应用分治法的前提,它也是大多数问题可以满足的,此特征反映了递归思想的应用。 -
利用该问题分解出的子问题的解可以合并为该问题的解。
能否利用分治法完全取决于问题是否具有这条特征,如果具备了前两条特征,而不具备第三条特征,则可以考虑贪心算法或动态规划。 -
该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
这条特征涉及到分治法的效率,如果各子问题是不独立的,则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然也可用分治法,但一般用动态规划较好。
在用分治法设计算法时,最好使子问题的规模大致相同。即将一个问题分成大小相等的k个子问题的处理方法是行之有效的。这种使子问题规模大致相等的做法是出自一种平衡(balancing)子问题的思想,它几乎总是比子问题规模不等的做法要好。
二、分治法的基本步骤
分治法通常包括三个步骤:
-
分解:将原问题分解成若干个子问题,这些子问题是原问题的规模较小的版本,且它们的结构与原问题相同或类似。
-
解决:递归地求解每个子问题。当子问题的规模足够小,可以直接求解时,则停止递归。
-
合并:将所有子问题的解合并成原问题的解。
divide-and-conquer(P)
{
if ( | P | <= n0) adhoc(P); //解决小规模的问题
divide P into smaller subinstances P1,P2,...,Pk;//1.分解
for (i=1,i<=k,i++)
yi=divide-and-conquer(Pi); //2.解决:递归的解各子问题
return merge(y1,...,yk); //3.合并:将各子问题的解合并为原问题的解
}
三、分治法的复杂性分析
一个分治法将规模为n的问题分成k个规模为n/m的子问题去解。
设分解阀值n0=1,且adhoc解规模为1的问题耗费1个单位时间。
再设将原问题分解为k个子问题以及用merge将k个子问题的解合并为原问题的解需用f(n)个单位时间。
那么,分治算法的时间复杂度可以表示为:
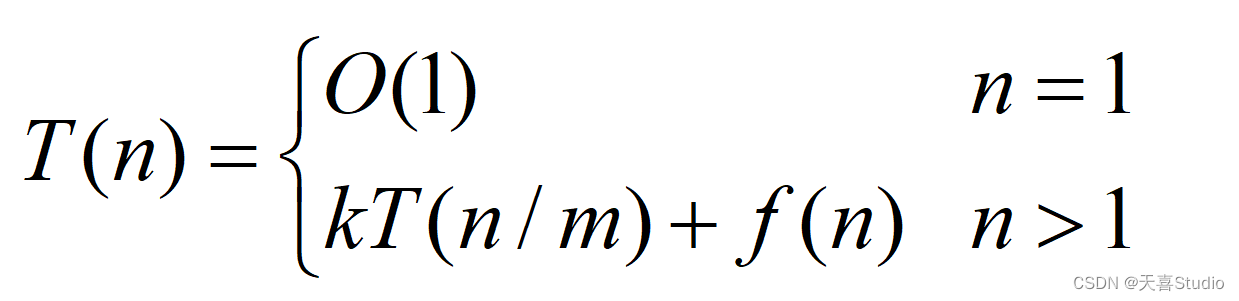
根据主定理,可以得到分治算法的时间复杂度为:T(n) = O(nlogk)
其中,k表示将问题分成k个子问题。
分治法实现——二分搜索
问题描述:
给定已按升序排好序的n个元素a[0:n-1],现要在这n个元素中找出一特定元素x
分析:
①该问题的规模缩小到一定的程度就可以容易地解决;
②该问题可以分解为若干个规模较小的相同问题;
③分解出的子问题的解可以合并为原问题的解
④分解出的各个子问题是相互独立的
满足分治法的四个条件
- 1.先将有序数组分成两部分,中间位置
mid为基准值 - 2.若该值等于目标值
key,则直接返回; - 若该值大于目标值,则在左半部分进行二分搜索;若该值小于目标值,则在右半部分进行二分搜索
循环执行二分搜索,直到左侧low标记大于右侧high标记

示例代码:
int binarySearch(int[] nums, int target)
{
int left = 0;
int right = nums.length - 1; // 注意:此处为数组下标
while(left <= right) //不是 < 搜索空间为空时终止循环,终止条件:left==right+1,如果使用<会漏掉一个元素
{
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
这里介绍一下我看过的labuladong的算法笔记中的内容:
二分查找的基本框架,几种二分搜索的变形都基于这个框架
int binarySearch(int[] nums, int target) {
int left = 0, right = ...;
while(...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
return ...;
}
二分搜索的时间复杂性
每执行一次算法的while循环, 待搜索数组的大小减少一半。
因此,在最坏情况下,while循环被执行了O(logn)次。循环体内运算需要O(1) 时间,因此整个算法在最坏情况下的计算时间复杂性为O(logn) 。

| 大家的点赞、收藏、关注将是我更新的最大动力! 欢迎留言或私信建议或问题。 |
| 大家的支持和反馈对我来说意义重大,我会继续不断努力提供有价值的内容!如果本文哪里有错误的地方还请大家多多指出(●'◡'●) |