语言模型:掌握BERT和GPT模型
- BERT模型
- BERT的基本原理
- BERT的整体架构
- BERT的输入
- BERT的输出
- BERT的预训练
- 掩码语言模型
- 预测下一个句子
- BERT的微调
- BERT的特征提取
- 使用PyTorch实现BERT
- GPT模型
- GPT模型的整体架构
- GPT的模型结构
- GPT-2的Multi-Head与BERT的Multi-Head之间的区别
- 只有Decoder的模块
- 了解GPT-2模型
- 深度理解GPT-2的细节
- GPT-2的输入
- 沿着层向上流动
- 回顾Self-Attention
- Self-Attention过程
- GPT-2的输出
- GPT与GPT-2的异同
- GPT与ELMo的异同
- GPT与BERT的异同
- 参考资料
ELMo模型可以根据上下文更新词的特征表示,实现了词向量由静态向动态的转变。但是由于ELMo依赖于双向语言模型的架构,导致其训练只能适用于小规模的语料库,计算效率并不高。为了解决这些问题,基于Transformer框架的BERT和GPT模型被提出来。
BERT模型
BERT的基本原理
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。BERT论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,令人目瞪口呆。
该模型有以下主要优点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
BERT的整体架构
BERT利用MLM进行预训练,并且采用深层的双向Transformer组件(单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token)来构建整个模型,因此最终生成能融合左右上下文信息的深层双向语言表征。整体架构如下所示:
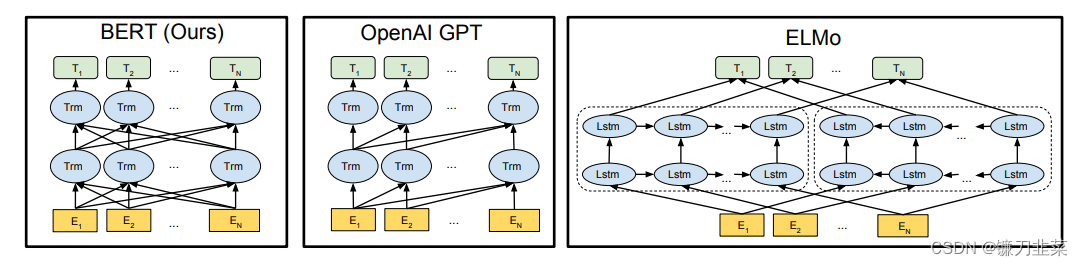
图1. 预训练模型架构的差异。 其中的Trm指Transformer的Encoder模块。BERT 使用双向 Transformer。 OpenAI GPT 使用从左到右的 Transformer。 ELMo 使用独立训练的从左到右和从右到左 LSTM 的串联来生成下游任务的特征。 在这三者中,只有 BERT 表示在所有层中同时以左右上下文为条件。 除了架构差异之外,BERT 和 OpenAI GPT 是微调方法,而 ELMo 是基于特征的方法。
TransformerBlock代码如下:
class TransformerBlock(nn.Module):
def __init__(self, k, heads):
super().__init__()
self.attention = SelfAttention(k, heads = heads)
self.norm1 = nn.LayerNorm(k)
self.norm2 = nn.LayerNorm(k)
self.mlp = nn.Sequential(
nn.Linear(k, 4*k)
nn.ReLU()
nn.Linear(4*k, k)
)
def forward(self, x):
attended = self.attention(x)
x = self.norm1(attended + x)
feedforward = self.mlp(x)
return self.norm2(feedforward + x)
BERT提供了简单和复杂两个模型,对应的超参数分别如下:
- BERT B A S E \text{BERT}_{BASE} BERTBASE:L=12, H=768, A=12, 参数总量为110MB;
- BERT L A R G E \text{BERT}_{LARGE} BERTLARGE:L=24, H=1024, A=16,参数总量为340MB;
BERT在海量语料的基础上进行自监督学习(所谓自监督学习就是指在没有人工标注的数据集上运行的监督学习)。在下游的NLP任务中,可以直接使用BERT的特征表示作为该下游任务的词嵌入特征。所以BERT提供的是一个供下游任务迁移学习的模型,该模型可以在根据下游任务微调或者固定之后作为特征提取器。
BERT的输入
BERT的输入的编码向量(d_model=512)是3个嵌入特征的单位和。如下图所示:
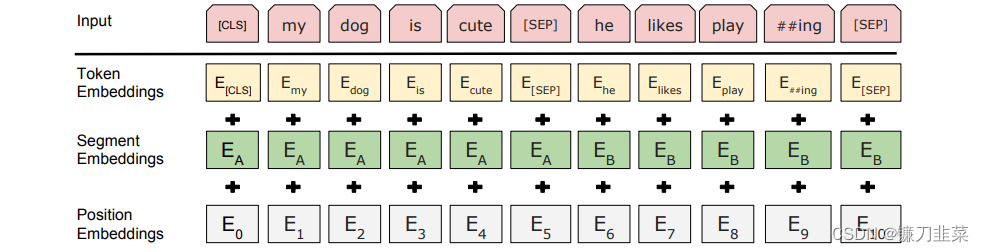
图2. BERT 输入表示。 输入embeddings是token embeddings、segmentation embeddings和position embeddings的总和。图中的粉红色块就是token,黄色块就是token对应的表征,单词字典是采用WordPiece算法来进行构建。为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话(文本情感分类,序列标注任务)或者两句话以上(文本摘要,自然语言推断,问答任务)。如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
1)在序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
2)为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
因此最后模型的输入序列tokens为下图(如果输入序列只包含一个句子的话,则没有[SEP]及之后的token):
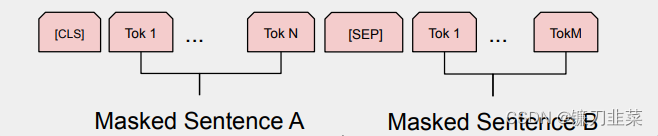
正如上文所讲,BERT的输入为每一个token对应的表征,实际上该表征是由三部分组成的,分别是对应的token,分割和位置embeddings:
- Token Embeddings
英文语料库一般采用词块嵌入(WordPiece Embedding),也就是说,将单词划分成一组有限的公共子词单元,这样能在单词的有效性和字符的灵活性之间取得平衡。如把”playing“拆分成"play"和”ing“。如果是中文语料库,设置成word级别即可。 - Position Embeddings
位置嵌入是指将单词的位置信息编码成特征向量,是向模型中引入单词位置关系的至关重要的一环。这里的位置嵌入和之前文章中的Transformer的位置嵌入不一样,它不是三角函数,而是学习出来的。 - Segment Embeddings
用于区分两个句子,例如B是否是A的下文(如对话场景、问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1.
BERT的输出
因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

C为分类token([CLS])对应最后一个Transformer的输出,
T
i
T_i
Ti则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把
T
i
T_i
Ti输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
BERT的预训练
实际上预训练的概念在CV(Computer Vision,计算机视觉)中已经是很成熟了,应用十分广泛。CV中所采用的预训练任务一般是ImageNet图像分类任务,完成图像分类任务的前提是必须能抽取出良好的图像特征,同时ImageNet数据集有规模大、质量高的优点,因此常常能够获得很好的效果。
虽然NLP领域没有像ImageNet这样质量高的人工标注数据,但是可以利用大规模文本数据的自监督性质来构建预训练任务。因此BERT构建了两个预训练任务,分别是Masked Language Model和Next Sentence Prediction。
掩码语言模型
掩码语言模型(Masked Language Model,MLM)是一种真正的双向的方法,是BERT能够不受单向语言模型所限制的原因。之前文章提到的ELMo模型只是将left-to-right和right-to-left分别训练拼接起来。两种模型的区别从它们的目标函数就可以明显看出来。
- ELMo以 P ( t k ∣ t 1 , . . . , t k − 1 ) , P ( t k ∣ t k + 1 ) , . . . , t n P(t_k|t_1,...,t_{k-1}), P(t_k|t_{k+1}),...,t_n P(tk∣t1,...,tk−1),P(tk∣tk+1),...,tn作为目标函数,然后独立训练,最后把结果拼接起来。
- BERT以 P ( t k ∣ t 1 , . . . , t k − 1 ) , t k + 1 , . . . , t n P(t_k|t_1,...,t_{k-1}),t_{k+1},...,t_n P(tk∣t1,...,tk−1),tk+1,...,tn作为目标函数,这样学到的词向量可同时关注左右词的信息。
简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。因此BERT采用了一个小技巧来解决这个问题,即在确定要遮掩掉的单词之后,80%会直接替换为[MASK],10%会将其替换为其他任意单词,10%会保留原始标识符。具体策略如下:
首先,在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第 i 个token被选中,则会被替换成以下三个token之一:
- 80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
- 10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
- 10%的时候是原来的token(保持不变,即是作为第2点所对应的负类)。如,my dog is hairy——>my dog is hairy
然后,再用该位置对应的 T i T_i Ti去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
整个MLM训练过程如下图所示:
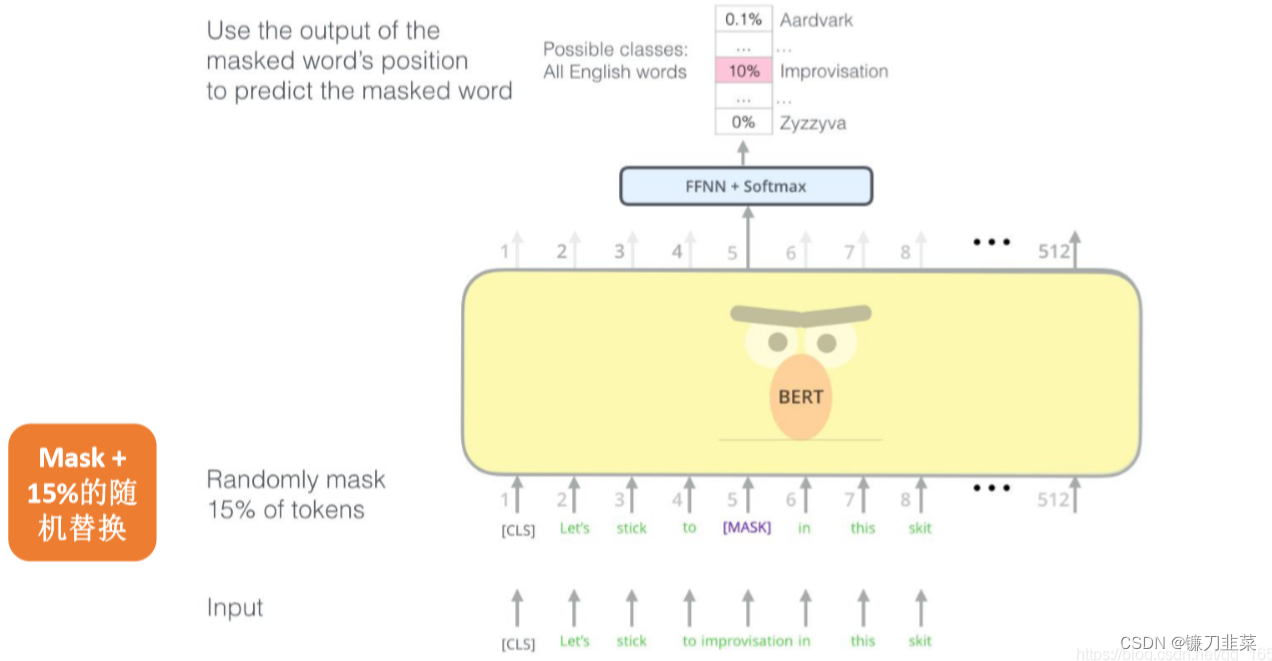
图3 BERT的MLM训练过程
预测下一个句子
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了Next Sentence Prediction(NSP)任务来预训练,简单来说就是预测两个句子是否连在一起。
具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
具体训练过程如下图所示:
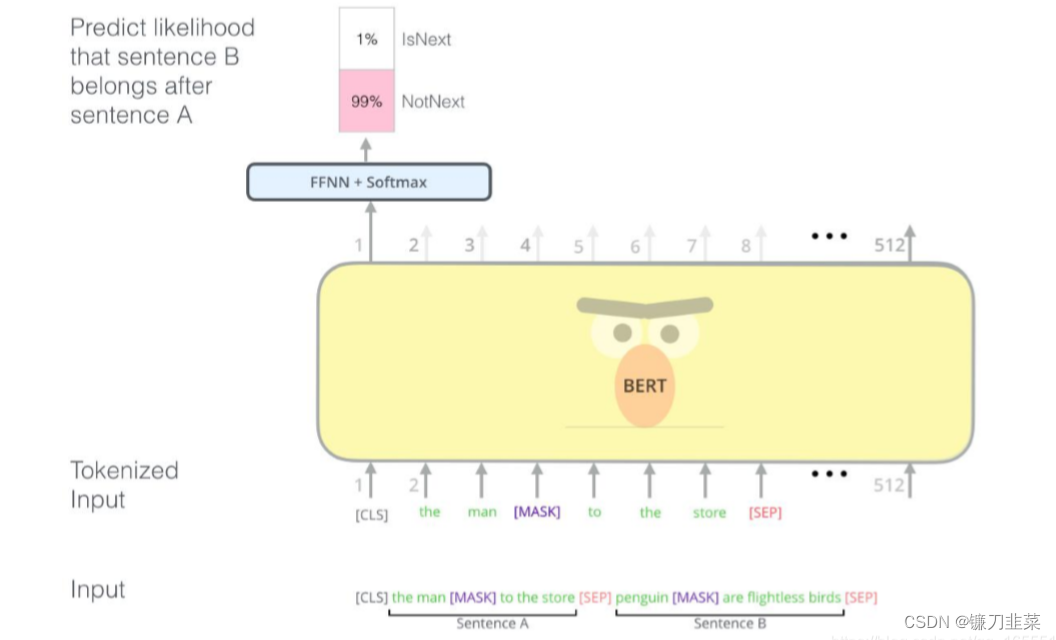
图4 BERT的NSP的预训练过程
最后训练样例长这样:
Input1=[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label1=IsNext
Input2=[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label2=NotNext
把每一个训练样例输入到BERT中可以相应获得两个任务对应的Loss,再把这两个Loss加在一起就是整体的预训练Loss(也就是两个任务同时进行训练)。
可以明显地看出,这两个任务所需的数据其实都可以从无标签的文本数据中构建(自监督性质)。
BERT训练过程包括MLM和NSP,其损失函数的具体定义可参考Hugging Face官方上对应的代码:https://huggingface.co/docs/transformers/main/en/model_doc/bert
BERT的微调
微调非常简单,因为 Transformer 中的自注意力机制允许 BERT 通过交换适当的输入和输出来对许多下游任务(无论它们涉及单个文本还是文本对)进行建模。对于涉及文本对的应用,常见的模式是在应用双向交叉注意力(bidirectional cross attention)之前独立编码文本对。
相反,BERT 使用自注意力机制来统一这两个阶段,因为使用自注意力对串联文本对进行编码,有效地包括两个句子之间的双向交叉注意力(bidirectional cross attention)。
在完成BERT对下游的分类任务时,只需要在BERT的基础上添加一个输出层即可完成对特定任务的微调(fine-tuning)。对分类问题可直接取第一个标识符(Token)的最后输出(即final hidden state,最后隐状态) C ∈ R H C\in R^H C∈RH,加一层权重 W W W后使用Softmax来预测标签的概率。 P = S o f t m a x ( C W T ) P=Softmax(CW^T) P=Softmax(CWT)
对于其他下游任务,则需要进行一些调整,如下图所示:
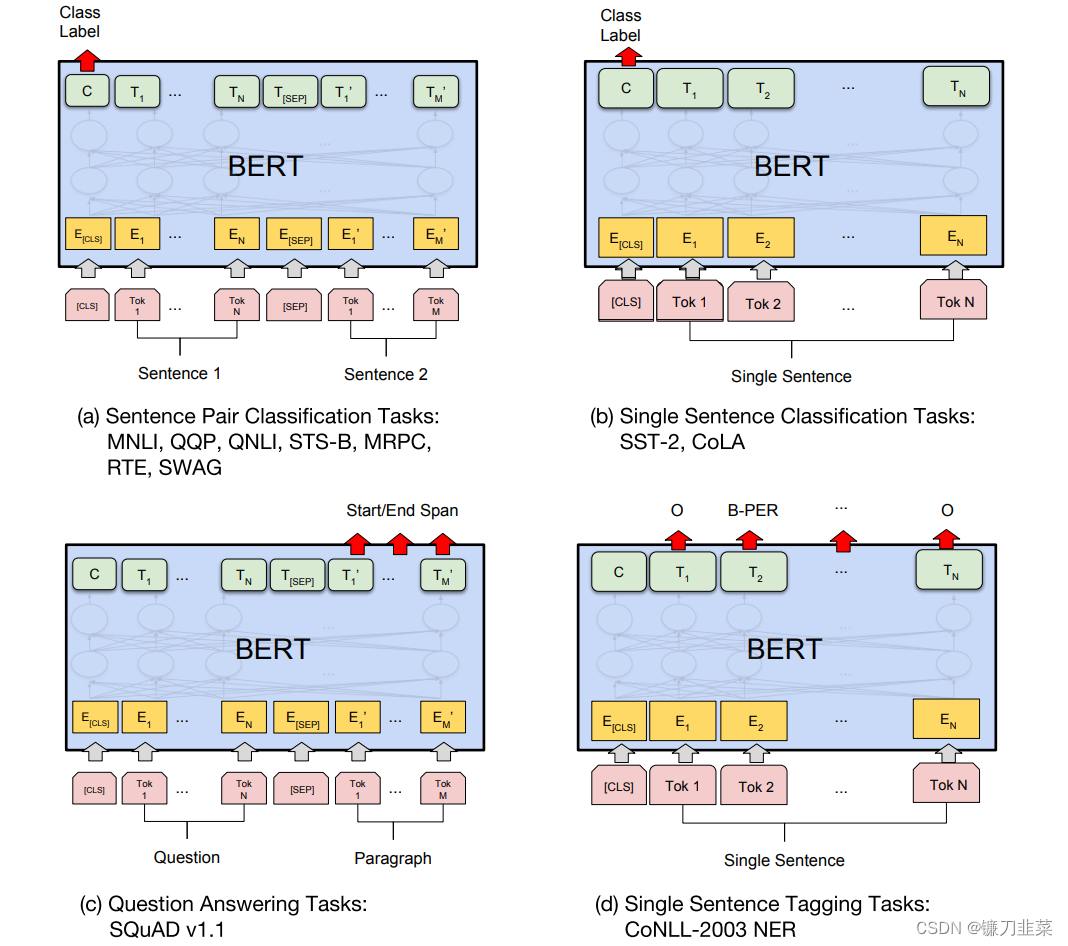
图5 对BERT预训练模型进行微调以完成相应下游任务。Tok表示不同的Token,E表示嵌入向量,
T
i
T_i
Ti表示第
i
i
i个Token经过BERT处理后得到的特征向量。
下面简单介绍几种下游任务及其需要微调的内容:
1)基于句子对的分类任务。如MNLL,给定一个前提,根据这个前提去推断假设与前提的关系;MRPC,判断两个句子是否等价。
2)基于单个句子的分类任务。如SST-2,电影评价的情感分析;CoLA,句子语义判断,是否是可接受的。
3)问答任务。如,SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
4)命名实体识别。如CoNLL-2023 NER:判断一个句子中的单词是不是人(Person)、组织(Organization)、位置(Location)或者其他实体。
BERT的特征提取
迄今为止提出的所有 BERT 结果都使用了微调方法,其中在预训练模型中添加了一个简单的分类层,并且所有参数在下游任务上联合微调。 然而,从预训练模型中提取固定特征的基于特征的方法具有一定的优势。 首先,并不是所有的任务都可以很容易地用 Transformer 编码器架构来表示,因此需要添加特定于任务的模型架构。 其次,预先计算一次昂贵的训练数据表示,然后在此表示之上使用更便宜的模型运行许多实验,具有重大的计算优势。
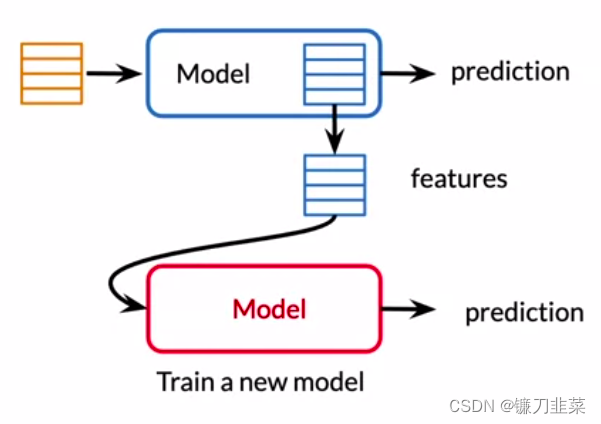
因此,使用预先训练好的BERT模型来创建上下文的单词嵌入,然后,将这些词嵌入现有的模型中。示例如下:
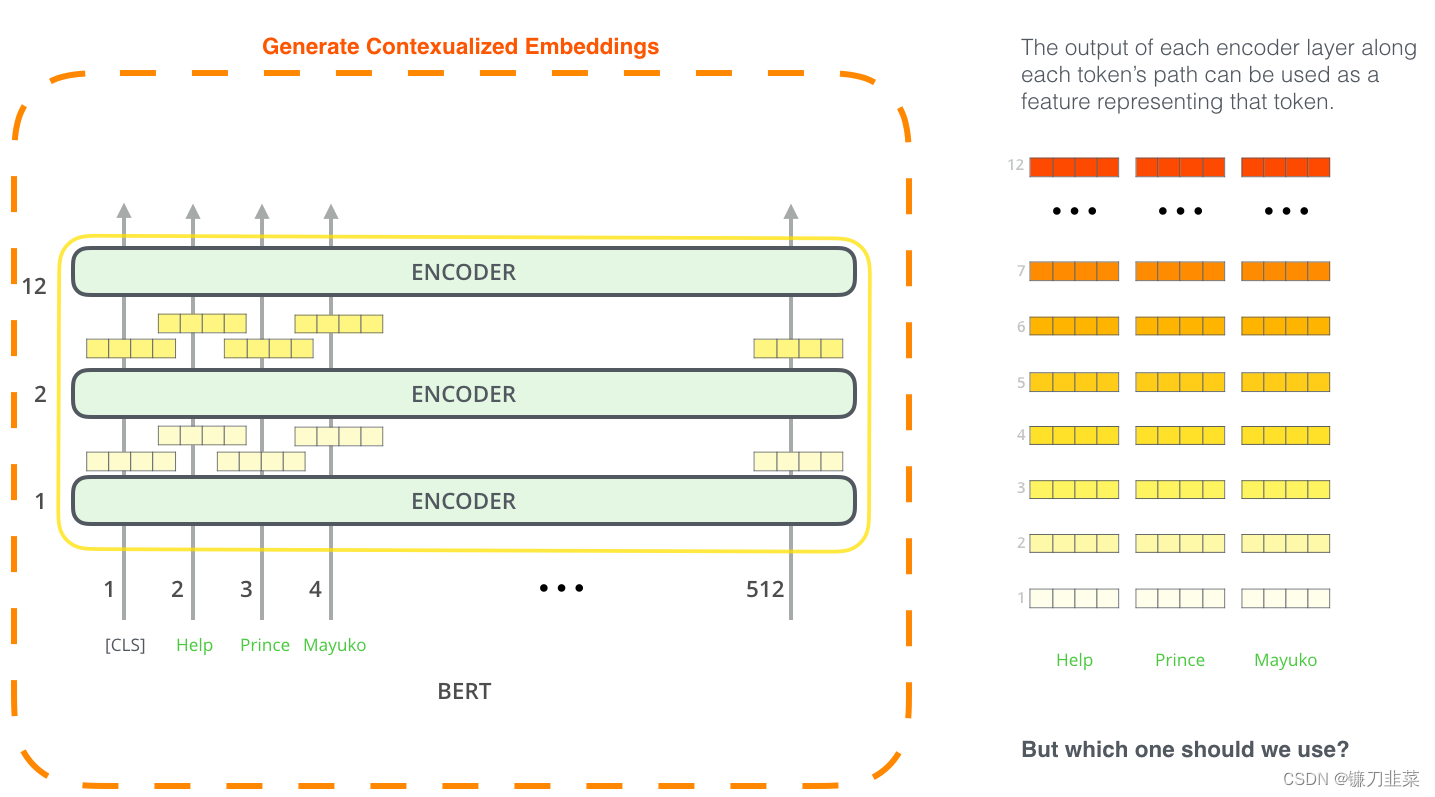
从上图我们可以看到,输入句子中每个单词的上下文嵌入都是由
B
E
R
T
b
a
s
e
BERT_{base}
BERTbase模型生成的。 由于
B
E
R
T
b
a
s
e
BERT_{base}
BERTbase 模型由 12 个 Transformer 编码器组成,因此每个编码器层都会为每个单词生成上下文嵌入,然后将其传递到上层 Transformer 编码器。 因此,我们有 12 种上下文词嵌入选择,它们是由 12 个 Transformer 编码器生成的。
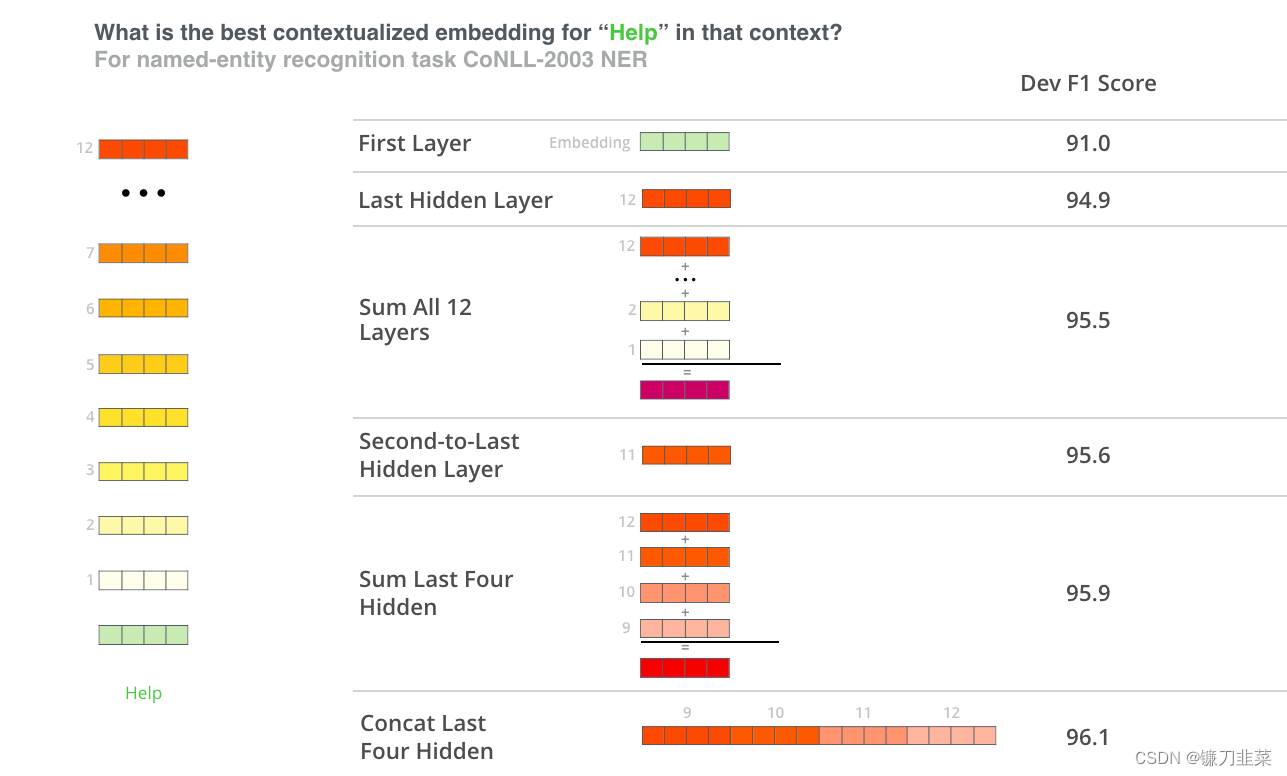
哪个向量作为上下文嵌入效果最好?个人认为这取决于任务。本文考察了六种选择(与获得96.4分的微调模型相比):
使用PyTorch实现BERT
试用BERT的最佳方式是通过Google Colab上托管的带有Cloud TPU notebook的BERT微调。如果你以前从未使用过Cloud TPU,这也是一个很好的起点,因为BERT代码也适用于TPU、CPU和GPU。
BERT官方代码仓库:https://github.com/google-research/bert,也可以参考Hugging face基于PyTorch实现的BERT版本:https://github.com/huggingface/transformers。AllenNLP库使用此实现来允许对任何模型使用BERT嵌入。
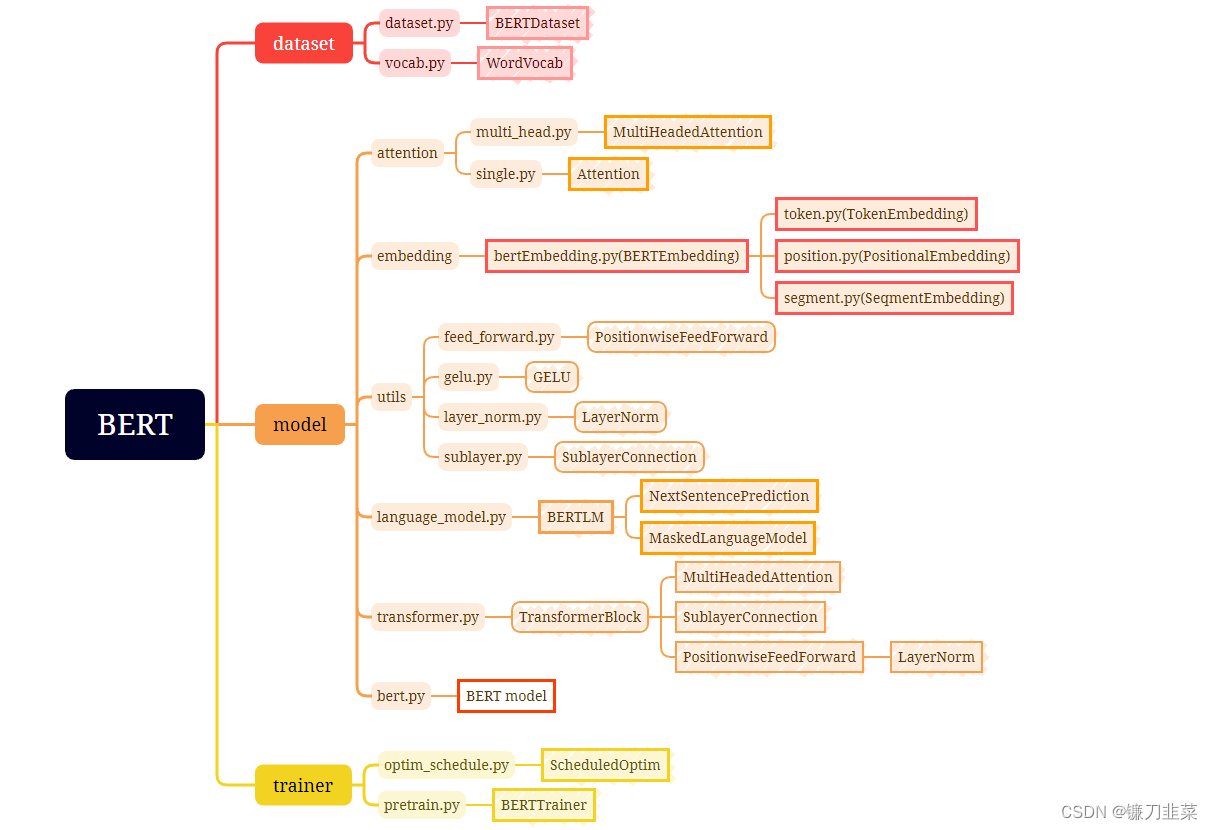
这里使用的PyTorch版本代码来自https://github.com/codertimo/BERT-pytorch。使用PyTorch实现BERT的核心模块主要有2个,其中一个是生成BERT输入的BERT Embedding类,另一个是TransformerBlock类,将这两个模块组合,即BERT模型的模块bert.py。这些模块之间的关系如下图:
首先解读BERT-pytorch的主文件(main):__main__.py

其中train_dataset和test_dataset是指你选的任务的训练数据和测试数据,我们一般称之为corpus(语料库)这里我们选取了GLUE数据集中的MRPC任务的训练集和测试集。vocab_path指的是vocabulary库(词汇表库),它相当于一个大字典,记录了所有可能出现的单词,后边我们将语料库中的单词转为id时候需要在这个大字典里查找。
接下来加载的是vocab的代码:

这块代码将单词表从txt格式转换为一个它对应的python对象,以便后续处理,具体过程是:

然后,加载数据对象,这里仅查看训练数据集:

然后,跳转进入BERTDataset (这种loader都是调用__getitem__方法实现的)

这部分数据处理的代码默认了我们的语料库中每一行是有两个句子并且以 ‘\t’ 分隔开。

所以它的处理步骤:
(1)把一行中两个句子拿出来,然后以50%概率正常返回两个句子,并且label返回为1(代表这两个句子是连接在一起的,否则就随机选一个别的句子拼上去并label为0代表不是一起的,这一步可以为NSP任务处理)

(2)把这两个句子中的一个个词扣出来,按照论文中所讲的概率将单词变成[MASK] 其他词 原来的词的id(id就是指这个词在大字典中的序号,因为计算机读入时候想读入数字)。

(3)给两个句子的token加上头CLS和尾巴SEP,同时两者对应的label也是0
(4)分段id,以及补全的padding id
上面是对数据的预处理部分,包括了对NSP和MLM任务分别的数据处理,以及加上CLS和SEP,还有对应的segment id等一些操作,下面正式开始构建BERT的整体框架。

构建BERT的核心代码如下:
import torch.nn as nn
from .transformer import TransformerBlock
from .embedding import BERTEmbedding
class BERT(nn.Module):
"""
BERT model : Bidirectional Encoder Representations from Transformers.
"""
def __init__(self, vocab_size, hidden=768, n_layers=12, attn_heads=12, dropout=0.1):
super().__init__()
self.hidden = hidden # 最后一层的维度 hidden size
self.n_layers = n_layers # Transformer的block数目,即层数
self.attn_heads = attn_heads # 多头注意力机制的注意力头数目 = hidden size / 每个头的维度
# 在bert中,hidden size = 768 时,头数为12,每个头维度是64
# paper noted they used 4*hidden_size for ff_network_hidden_size
self.feed_forward_hidden = hidden * 4
# transformer的每个block为多头-残差块-feedforward-残差块 这里是feedforward的维度
# embedding for BERT, sum of positional, segment, token embeddings
self.embedding = BERTEmbedding(vocab_size=vocab_size, embed_size=hidden)
# multi-layers transformer blocks, deep network
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden, attn_heads, hidden * 4, dropout) for _ in range(n_layers)])
def forward(self, x, segment_info):
# attention masking for padded token
# torch.ByteTensor([batch_size, 1, seq_len, seq_len)
mask = (x > 0).unsqueeze(1).repeat(1, x.size(1), 1).unsqueeze(1)
# embedding the indexed sequence to sequence of vectors
x = self.embedding(x, segment_info)
# running over multiple transformer blocks
for transformer in self.transformer_blocks:
x = transformer.forward(x, mask)
return x
首先是BERT模型的初始化,我们知道BERT是Transformer的encoder部分,所以初始化这部分主要是对Transformer的结构的搭建(包括Transformer的block和多头的头数,hiddensize的大小,layer的层数,上述注释有提到)。
然后从forward函数可知,首先构建mask,找到数据中不为padding的地方给赋值为1并扩展成对应的维度,然后使用BERTEmbedding将单词编码,经过一个个Transformer块最后输出。下面是BERTEmbeding类和TransformerBlock类的代码:
import torch.nn as nn
from .token import TokenEmbedding
from .position import PositionalEmbedding
from .segment import SegmentEmbedding
class BERTEmbedding(nn.Module):
"""
BERT Embedding which is consisted with under features
1. TokenEmbedding : normal embedding matrix 正则嵌入矩阵
2. PositionalEmbedding : adding positional information using sin, cos
2. SegmentEmbedding : adding sentence segment info, (sent_A:1, sent_B:2)
sum of all these features are output of BERTEmbedding
"""
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: total vocab size 总词汇量的大小
:param embed_size: embedding size of token embedding 标记嵌入的嵌入大小
:param dropout: dropout rate
"""
super().__init__()
self.token = TokenEmbedding(vocab_size=vocab_size, embed_size=embed_size)
self.position = PositionalEmbedding(d_model=self.token.embedding_dim)
self.segment = SegmentEmbedding(embed_size=self.token.embedding_dim)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, sequence, segment_label):
x = self.token(sequence) + self.position(sequence) + self.segment(segment_label)
return self.dropout(x)
import torch.nn as nn
from .attention import MultiHeadedAttention
from .utils import SublayerConnection, PositionwiseFeedForward
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
# attention会返回QKV计算后的结果,QKV都是可学习的Linear层
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
# Position这个好像就是两个Linear中间加一个激活层
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
# Multi-head+残差块,配上FeedForward+残差块,共同组成了一个Transformer
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
最后就是常规的PyTorch训练网络的过程,输入数据和相应的Label,计算Loss并反向传播:
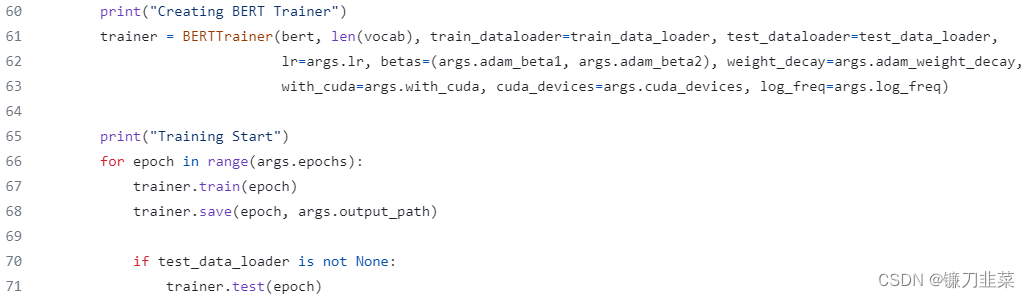
GPT模型
2018 年 6 月,OpenAI 发表论文介绍了自己的语言模型 GPT,GPT 是“Generative Pre-Training”的简称,它基于 Transformer 架构,GPT模型先在大规模语料上进行无监督预训练、再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式。先训练一个通用模型,然后再在各个任务上调节,这种不依赖针对单独任务的模型设计技巧能够一次性在多个任务中取得很好的表现。
与BERT预训练模型采用了Transformer的Encoder部分不同的是,GPT系列使用了Transformer的Decoder部分。由于GPT模型采用了传统的语言模型进行训练,即使用单词的上文预测单词,因此,GPT更擅长处理自然语言生成任务(NLG),而BERT更擅长处理自然语言理解任务(NLU)。
GPT模型的整体架构
GPT框架是用一种半监督学习的方法来完成语言理解任务,其训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。整体架构如下图所示:
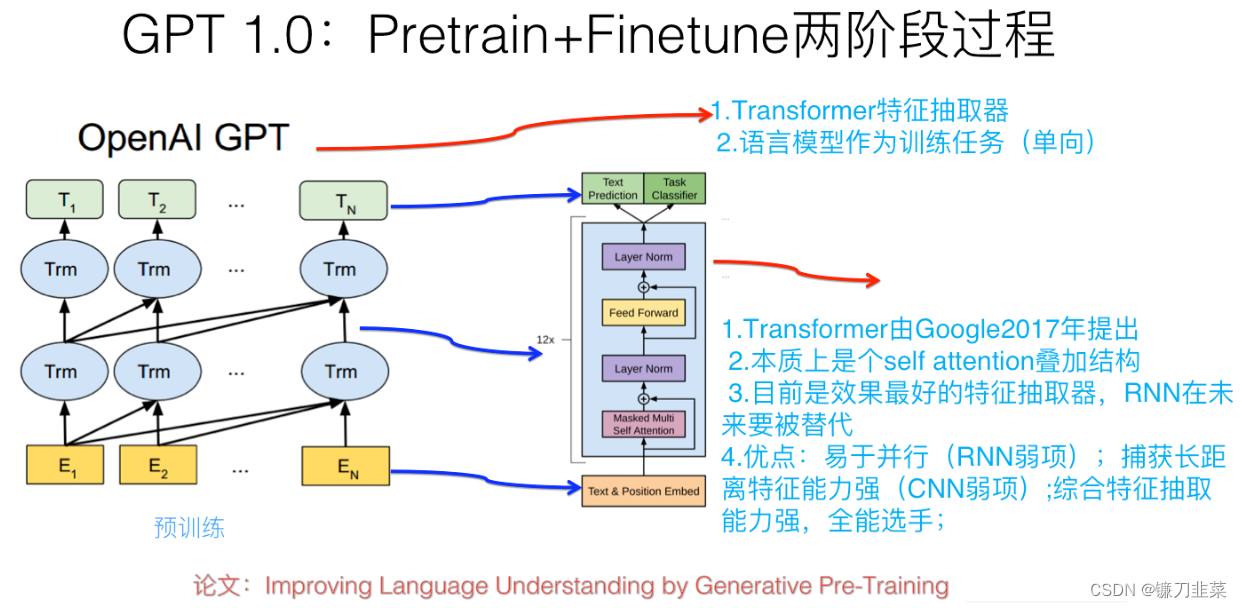
其中Trm表示Decoder模块,在同一水平线上的Trm表示在同一个单元,
E
i
E_i
Ei表示词嵌入,那些复杂的连线表示词与词之间的依赖关系,显然GPT要预测的词只依赖上文。
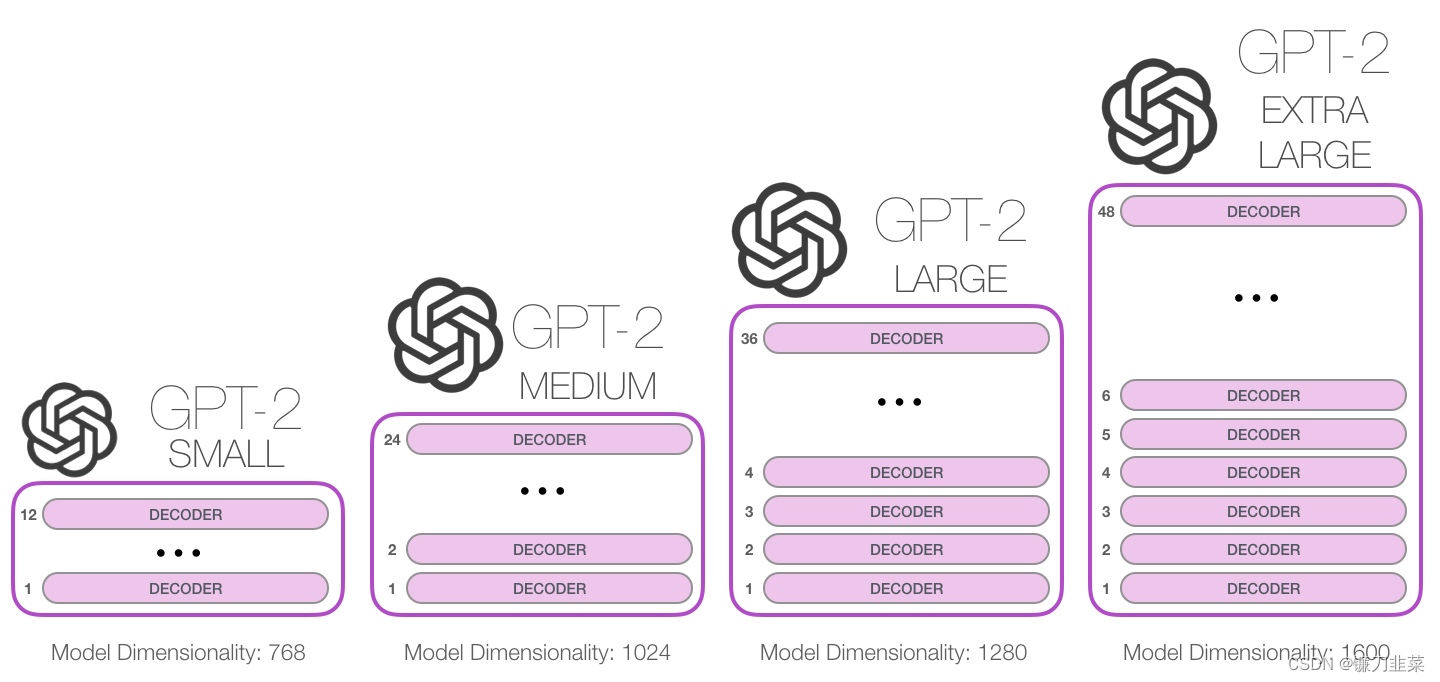
GPT-2根据其规模大小的不同,大致有4个版本,如图所示:
GPT的模型结构
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。如下图所示:
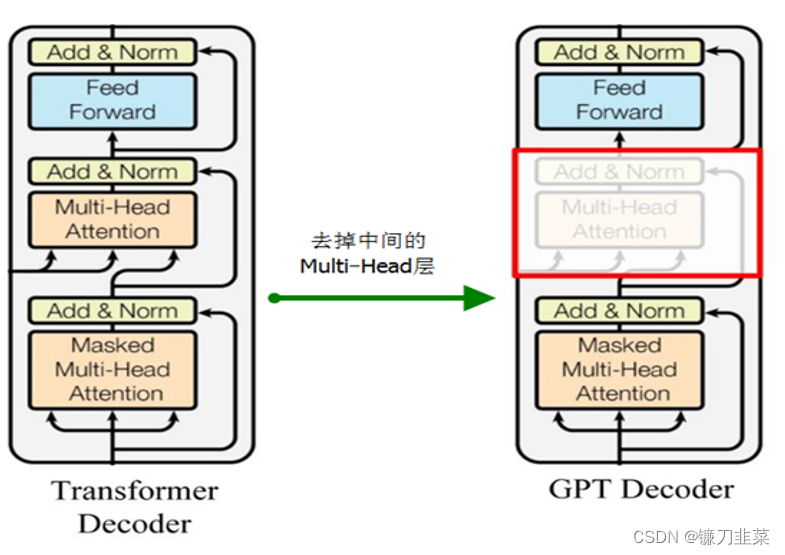
GPT-2的Multi-Head与BERT的Multi-Head之间的区别
重要的是,self-attention(BERT 使用的)和masked self-attention(GPT-2使用的)之间的区别是明确的。一个正常的 Self Attention 模块允许一个位置关注到它右边的部分,Masked self-attention阻止了这种情况的发生。也就是说BERT可以同时从某个词的左右两边进行关注,而GPT-2只能关注词的右边。
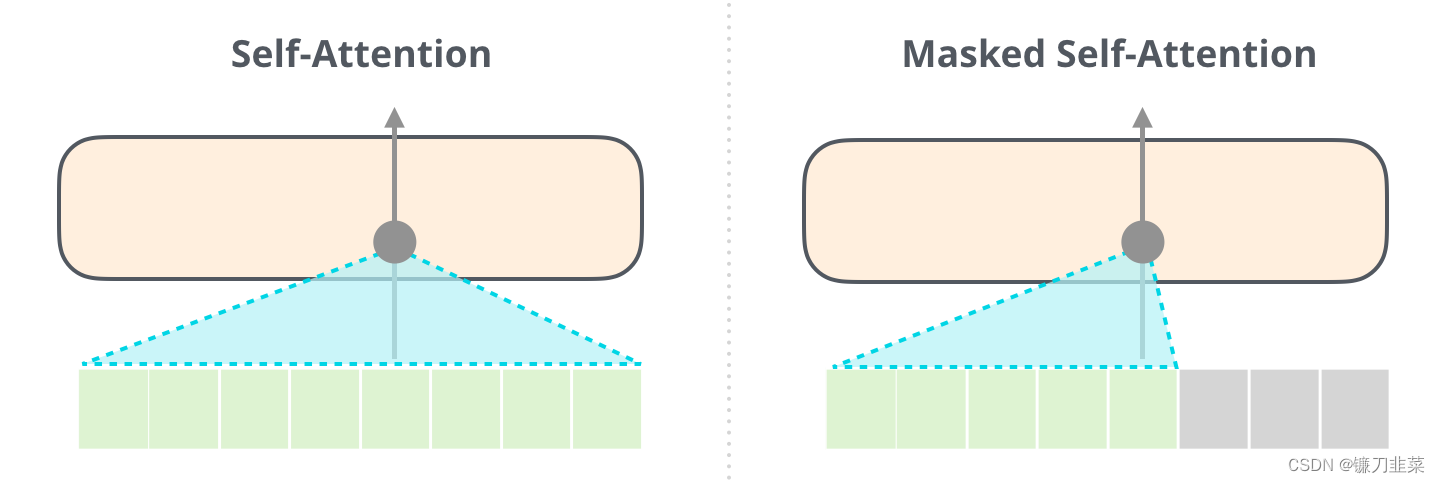
只有Decoder的模块
在 Transformer 原始论文发布之后,Generating Wikipedia by Summarizing Long Sequences 提出了另一种能够进行语言建模的 Transformer 模块的布局。这个模型丢弃了 Transformer 的 Encoder。因此,我们可以把这个模型称为 Transformer-Decoder。这种早期的基于 Transformer 的语言模型由 6 个 Decoder 模块组成。
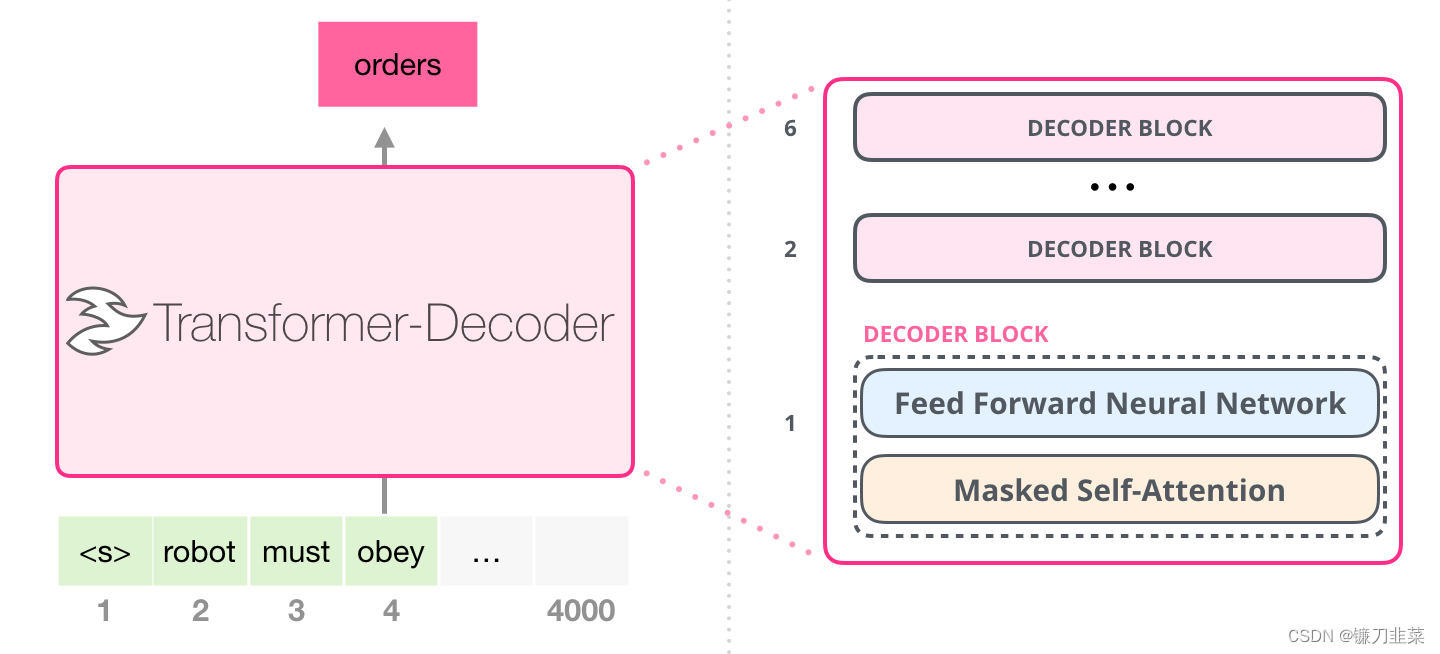
这些 Decoder 模块都是相同的。上图已经展开了第一个 Decoder,因此可以看到它的 Self-Attention 层是 masked 的。注意,现在这个模型可以处理多达 4000 个 token–是对原始论文中 512 个 token 的一个大升级。
这些模块和原始的 Decoder 模块非常类似,只是它们去掉了第二个 Self Attention 层。在Character-Level Language Modeling with Deeper Self-Attention 中使用了类似的结构,来创建一次一个字母/字符的语言模型。
OpenAI 的 GPT-2 使用了这些 Decoder 模块。
了解GPT-2模型
首先来看一个经过训练的GPT-2是如何工作的。
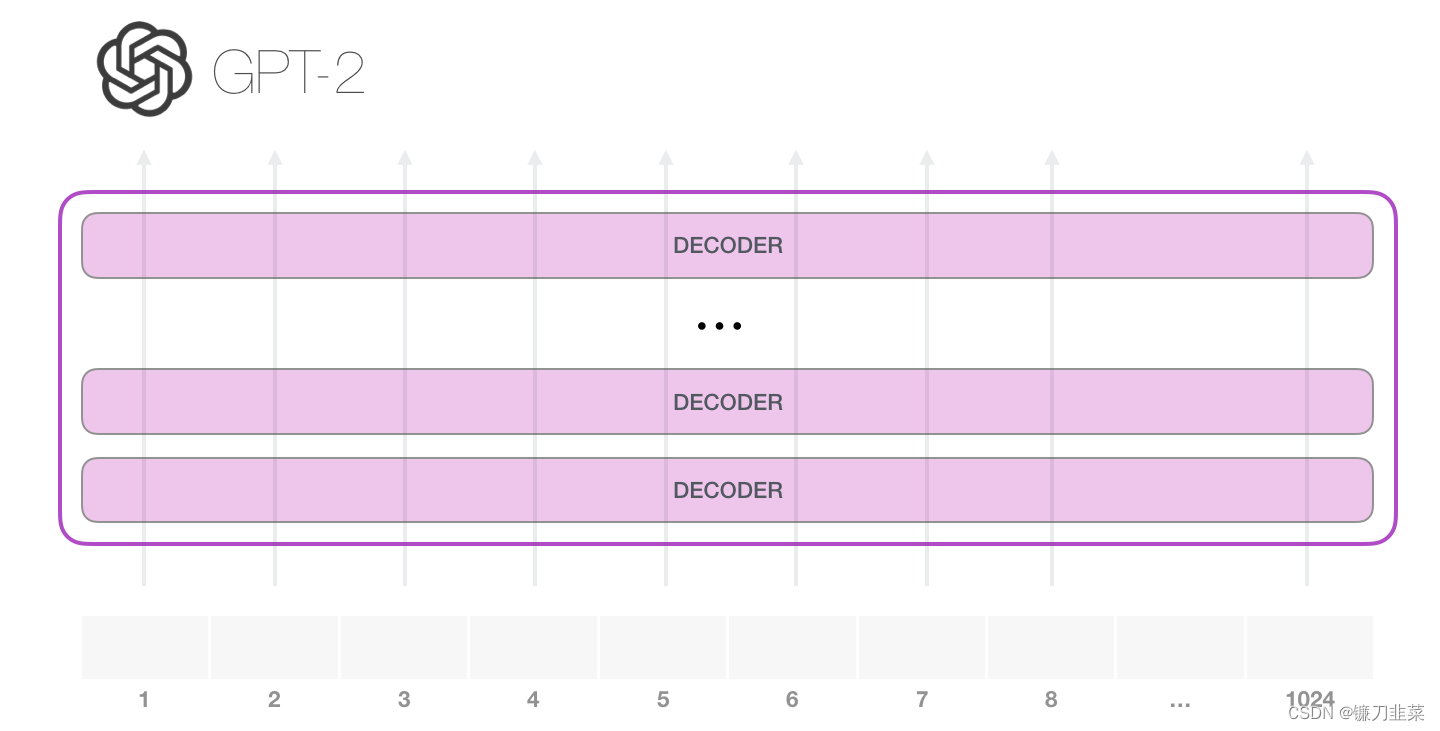
GPT-2 能够处理 1024 个 token。每个 token 沿着自己的路径经过所有的 Decoder 模块
运行一个训练好的 GPT-2 模型的最简单的方法是让它自己生成文本(这在技术上称为 生成无条件样本(generating unconditional samples))。或者,可以给它一个提示prompt ,让它谈论某个主题(即生成交互式条件样本(interactive conditional samples))。在漫无目的情况下,可以简单地给它输入初始 token,并让它开始生成单词(训练好的模型使用 <|endoftext|> 作为初始的 token。我们称之为 <s>)。
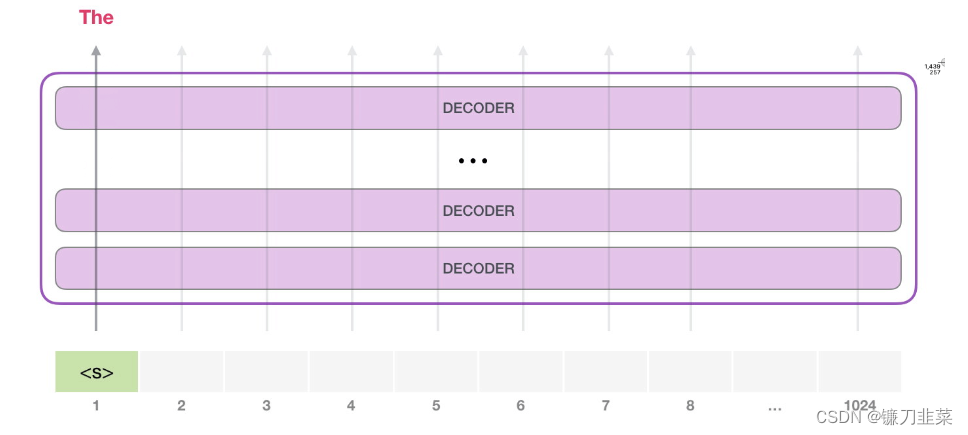
模型只有一个输入的 token,因此只有一条活跃路径。token 在所有层中依次被处理,然后沿着该路径生成一个向量。这个向量可以根据模型的词汇表计算出一个分数(模型知道所有的 单词,在 GPT-2 中是 5000 个词)。在这个例子中,我们选择了概率最高的 the。但我们可以把事情搞混——如果一直在键盘 app 中选择建议的单词,它有时候会陷入重复的循环中,唯一的出路就是点击第二个或者第三个建议的单词。同样的事情也会发生在这里,GPT-2 有一个top-k 参数,我们可以使用这个参数,让模型考虑第一个词(top-k =1)之外的其他词。
下一步,把第一步的输出添加到输入序列,然后让模型做下一个预测。
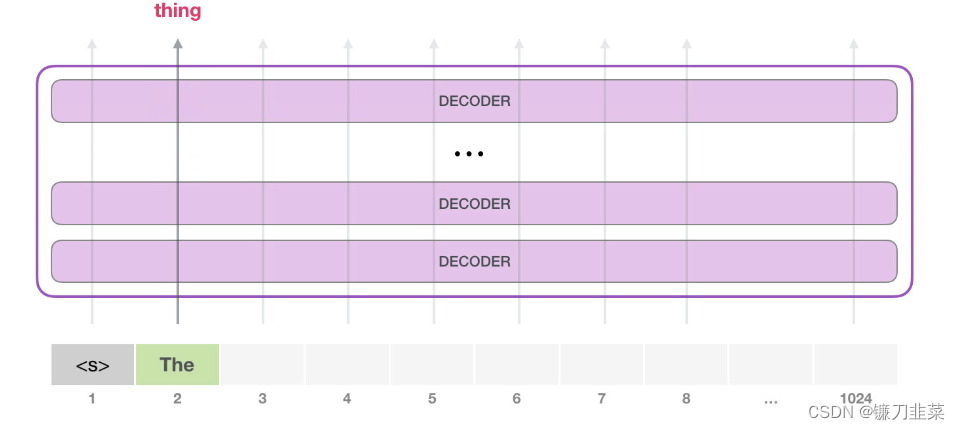
请注意,第二条路径是此计算中唯一活动的路径。GPT-2 的每一层都保留了它自己对第一个 token 的解释,而且会在处理第二个 token 时使用它。GPT-2 不会根据第二个 token 重新计算第一个 token。
深度理解GPT-2的细节
GPT-2的输入
正如我们之前讨论过的其他 NLP 模型一样,GPT-2在其嵌入矩阵中查找输入单词的嵌入——这是我们从训练好的模型中得到的组件之一。
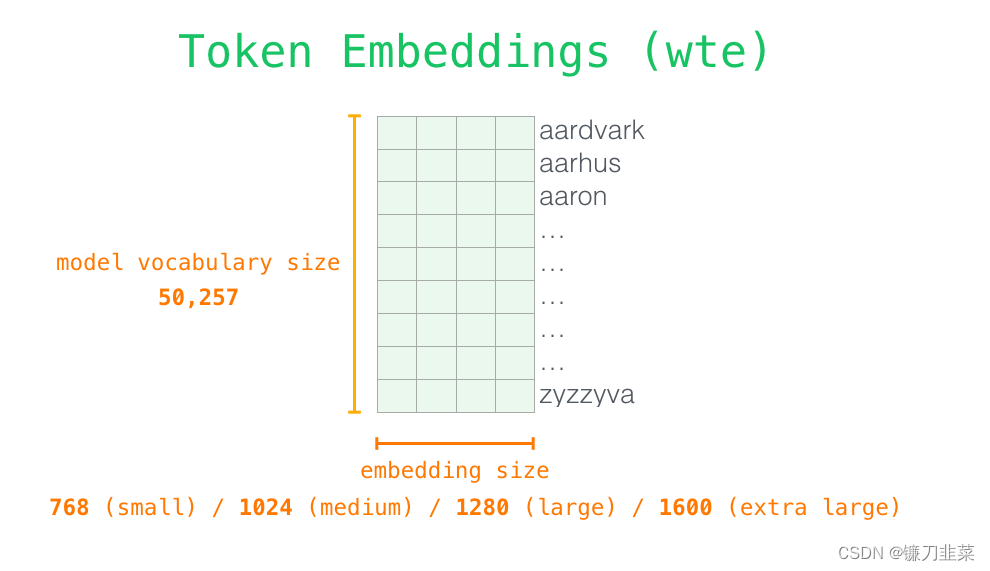
每一行都是词的 embedding:这是一个数字列表,可以表示一个词并捕获一些含义。这个列表的大小在不同的 GPT-2 模型中是不同的。最小的模型使用的 embedding 大小是 768
因此,在开始时,我们会在嵌入矩阵查找第一个 token<s> 的 embedding。在把这个 embedding 传给模型的第一个模块之前,需要融入位置编码,这个位置编码能够指示单词在序列中的顺序。训练好的模型中,有一部分是一个矩阵,这个矩阵包括了 1024 个位置中每个位置的位置编码向量。
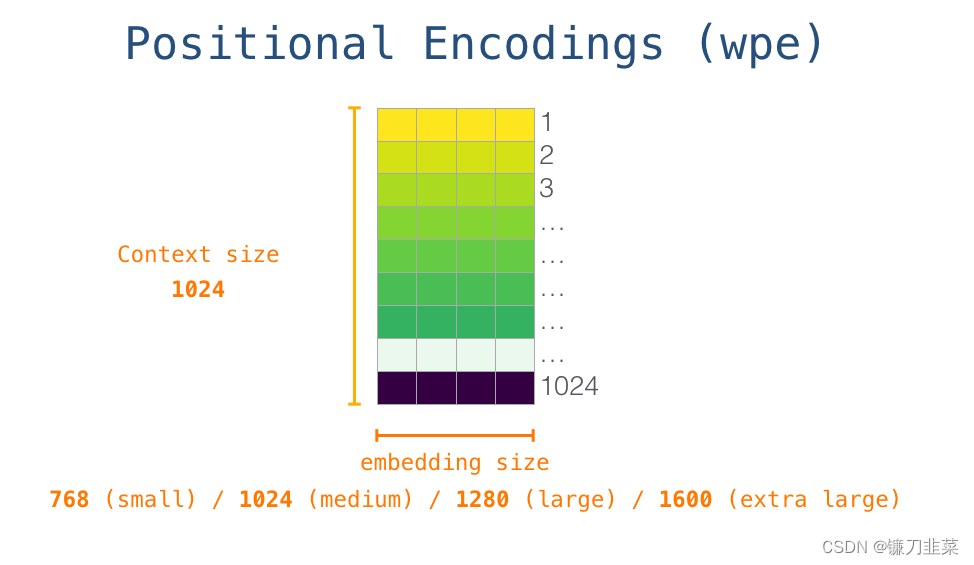 在这里,我们讨论了输入单词在传递到第一个 Transformer 模块之前,是如何被处理的。我们还知道,训练好的 GPT-2 包括两个权重矩阵:一个是记录所有单词或标识符的嵌入矩阵(Token Embedding),该矩阵形状为model_vocabulary_size × Embedding_size;另一个是表示单词在上下文的位置编码矩阵(Positional Encoding),该矩阵形状为context_size × Embedding_size,其中Embedding_size由GPT-2模型大小而定,Small模型是768,Medium模型是1024,以此类推。
在这里,我们讨论了输入单词在传递到第一个 Transformer 模块之前,是如何被处理的。我们还知道,训练好的 GPT-2 包括两个权重矩阵:一个是记录所有单词或标识符的嵌入矩阵(Token Embedding),该矩阵形状为model_vocabulary_size × Embedding_size;另一个是表示单词在上下文的位置编码矩阵(Positional Encoding),该矩阵形状为context_size × Embedding_size,其中Embedding_size由GPT-2模型大小而定,Small模型是768,Medium模型是1024,以此类推。
输入GPT-2模型前,需要在标识嵌入加上对应的位置编码,如下图所示:

把一个单词输入到 Transformer 的第一个模块,意味着寻找这个单词的 embedding,并且添加第一个位置的位置编码向量。其中每个标识的位置编码在各层的Decoder中是不变的,该位置编码不是一个学习向量。
沿着层向上流动
第一个模块现在可以处理 token,首先通过 Self-Attention 层,然后通过神经网络层。一旦 Transformer 的第一个模块处理了 token,会得到一个结果向量,这个结果向量会被发送到堆栈的下一个模块处理。每个模块的处理过程都是相同的,不过每个模块都有自己的 Self-Attention 和神经网络层。
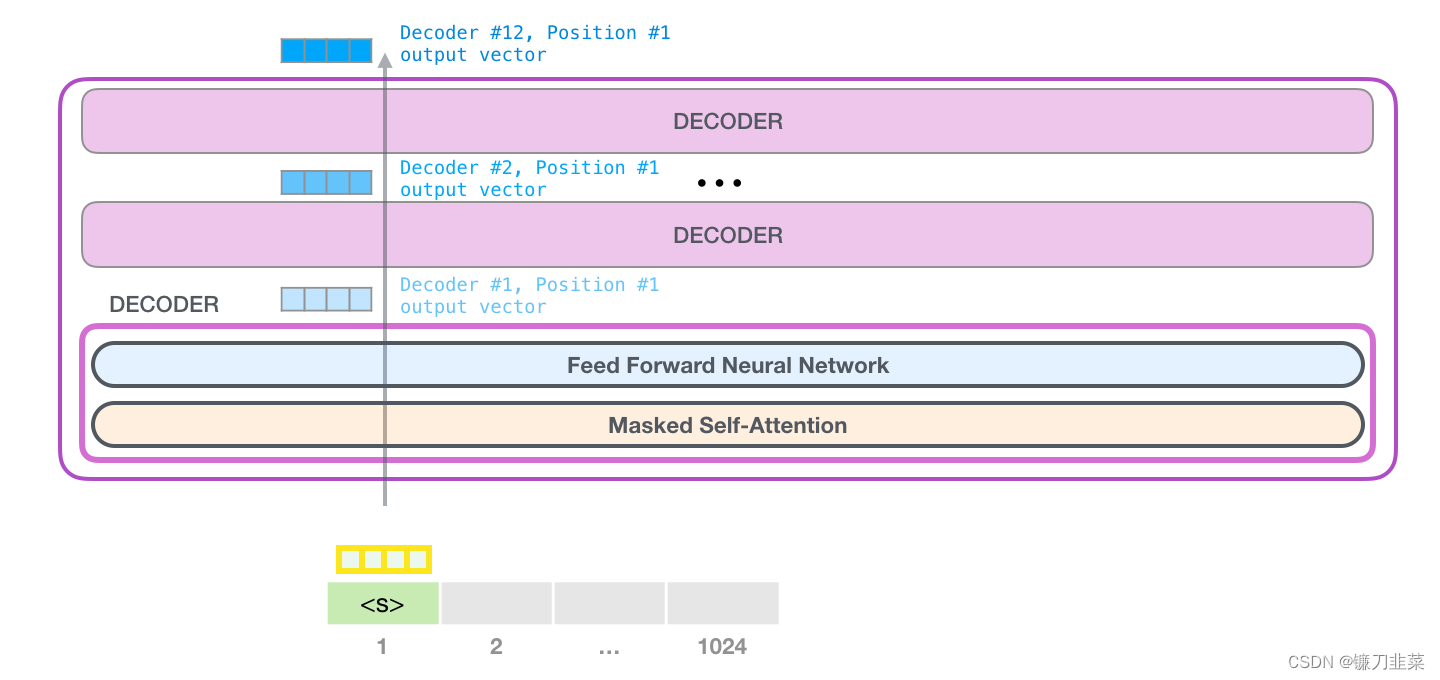
回顾Self-Attention
语言严重依赖于上下文。例如,看看下面的第二定律:
Second Law of Robotics
A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
在句子中高亮了 3 个部分,这些部分的词是用于指代其他的词。如果不结合它们所指的上下文,就无法理解或者处理这些词。当一个模型处理这个句子,它必须能够知道:
- 它 指的是机器人
- 该命令 指的是这个定律的前面部分,也就是 人给予 它 的命令
- 第一定律 指的是机器人第一定律
Self-Attention所做的事就是它在处理某个词之前,将模型对这个词的相关词和关联词的理解融合起来(并输入到一个神经网络)。它通过对句子片段中每个词的相关性打分,并将这些词的表示向量加权求和。举个例子,下图顶部模块中的Self-Attention层在处理单词 it 的时候关注到 a robot。它传递给神经网络的向量,是 3 个单词和它们各自分数相乘再相加的和。
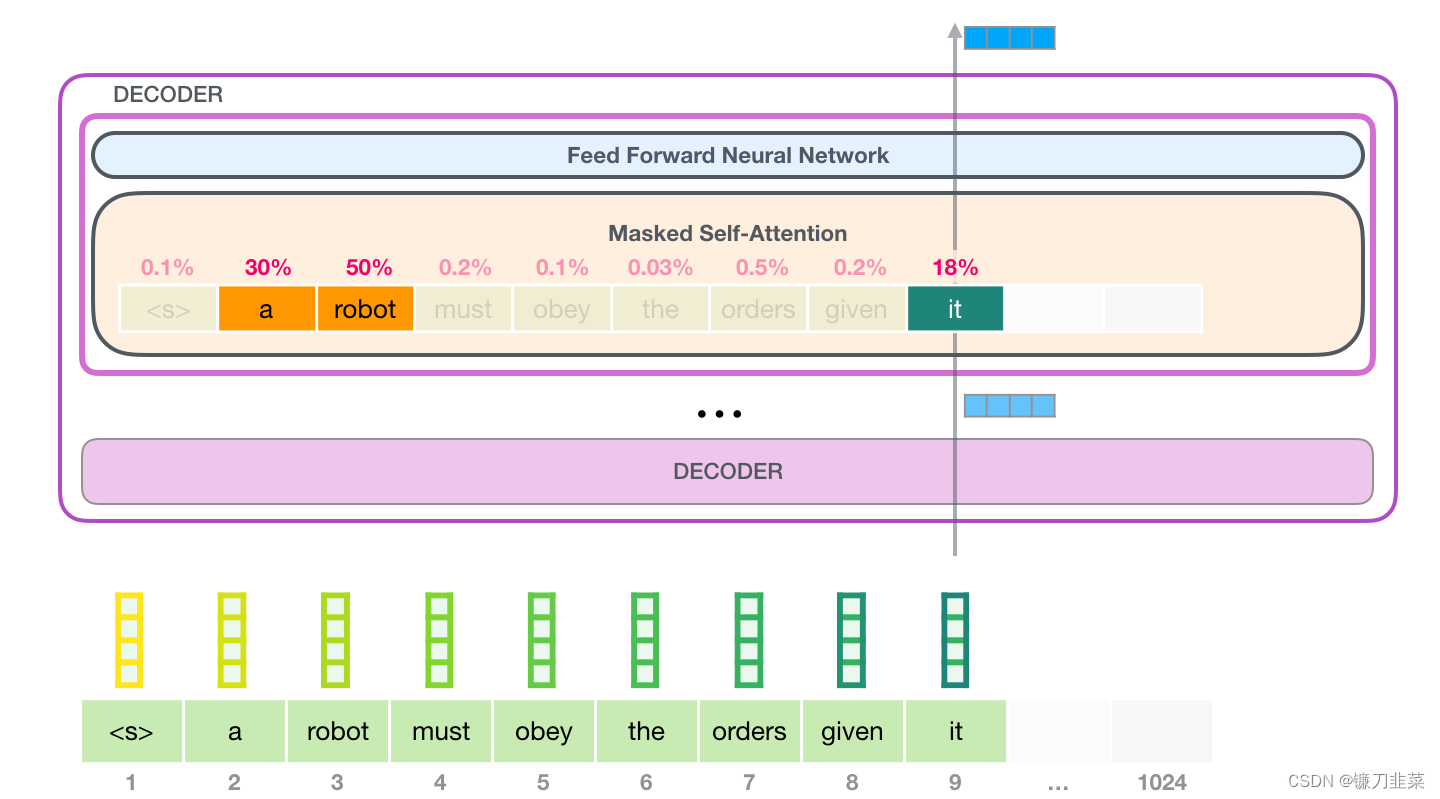
Self-Attention过程
Self-Attention 沿着句子中每个token的路径进行处理,主要组成部分包括 3 个向量。
- Query:Query 向量是当前单词的表示,用于对其他所有单词(使用这些单词的 key 向量)进行评分。我们只关注当前正在处理的 token 的 query 向量。
- Key:Key 向量就像句子中所有单词的标签。它们就是我们在搜索单词时所要匹配的。
- Value:Value 向量是实际的单词表示,一旦我们对每个词的相关性进行了评分,我们需要对这些向量进行加权求和,从而表示当前的词。
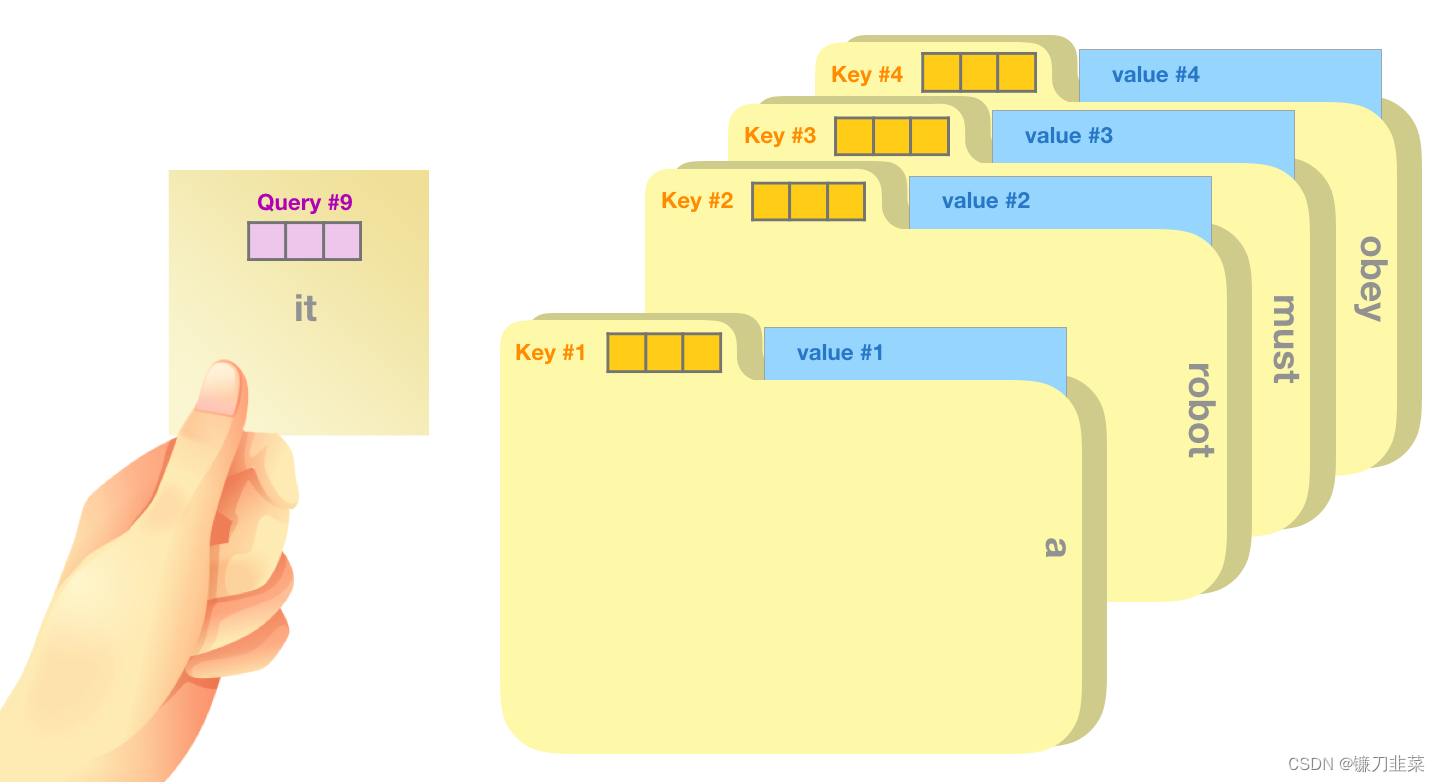
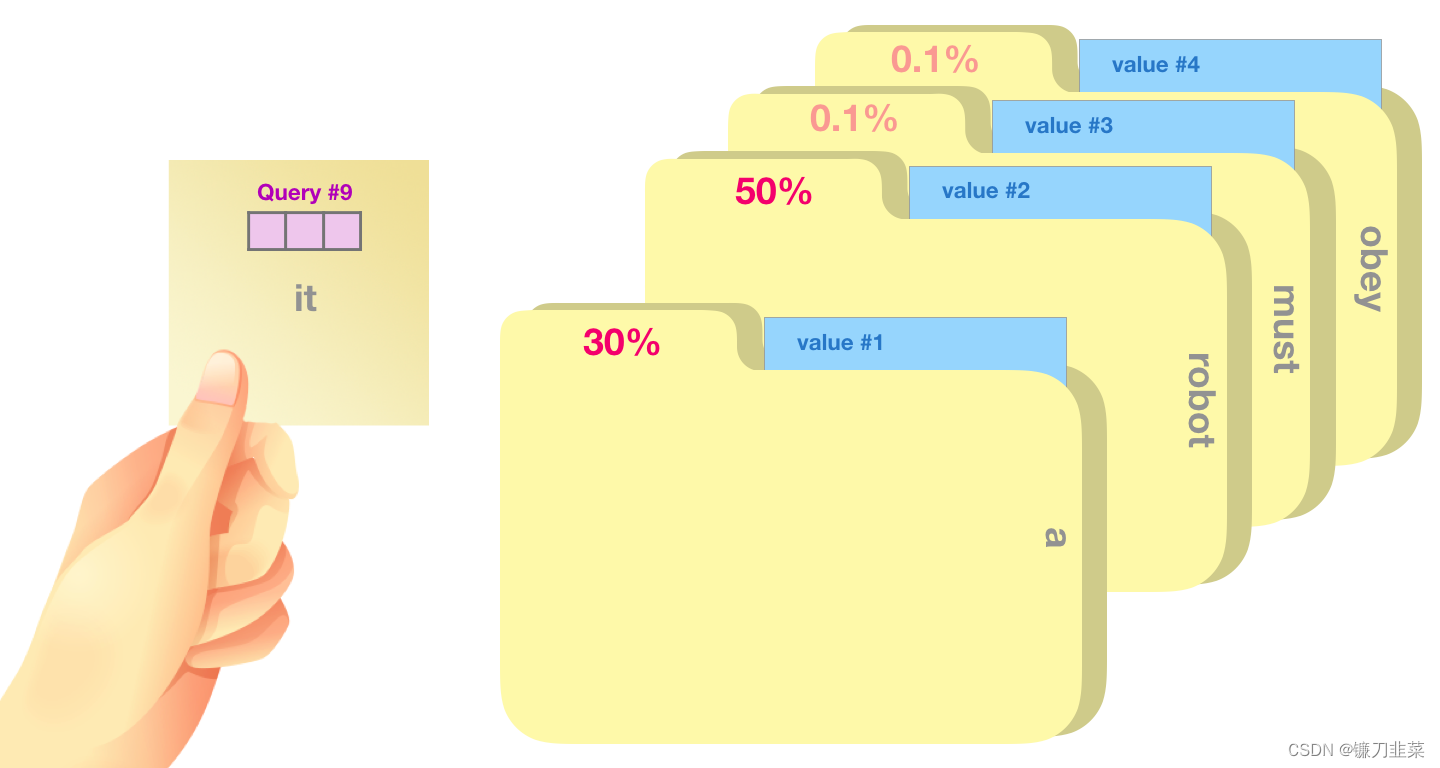
一个粗略的类比是把它看作是在一个文件柜里面搜索,Query 向量是一个便签,上面写着你正在研究的主题,而 Key 向量就像是柜子里的文件夹的标签。当你将便签与标签匹配时,我们取出匹配的那些文件夹的内容,这些内容就是 Value 向量。但是你不仅仅是寻找一个 Value 向量,而是在一系列文件夹里寻找一系列 Value 向量。
将 Value 向量与每个文件夹的 Key 向量相乘,会为每个文件夹产生一个分数(从技术上来讲:就是点积后面跟着 softmax)。
我们将每个 Value 向量乘以对应的分数,然后求和,得到 Self Attention 的输出。
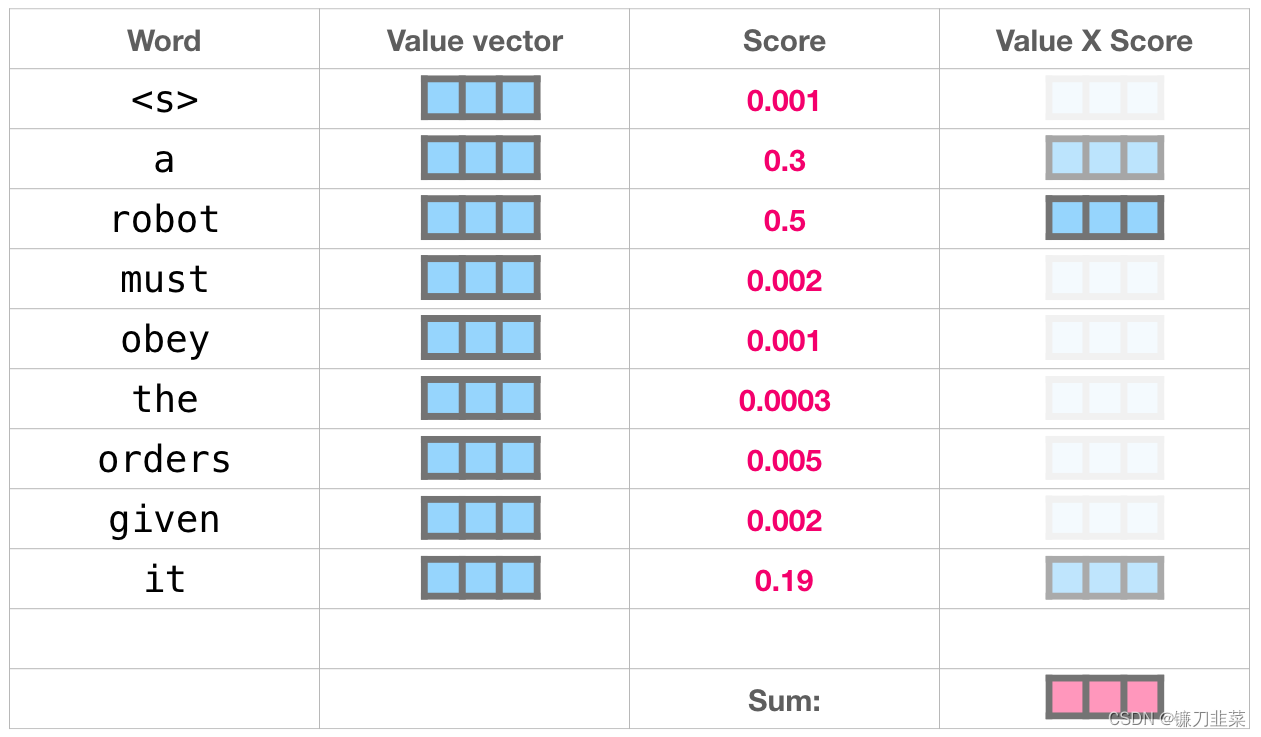
这些加权的 Value 向量会得到一个向量,它将 50% 的注意力放到单词 robot 上,将 30% 的注意力放到单词 a,将 19% 的注意力放到单词 it。在下文中,我们会更加深入 Self Attention,但现在,首先让我们继续在模型中往上走,直到模型的输出。
GPT-2的输出
当模型顶部的模块产生输出向量时(这个向量是经过 Self-Attention 层和神经网络层得到的),模型会将这个向量乘以embedding matrix。
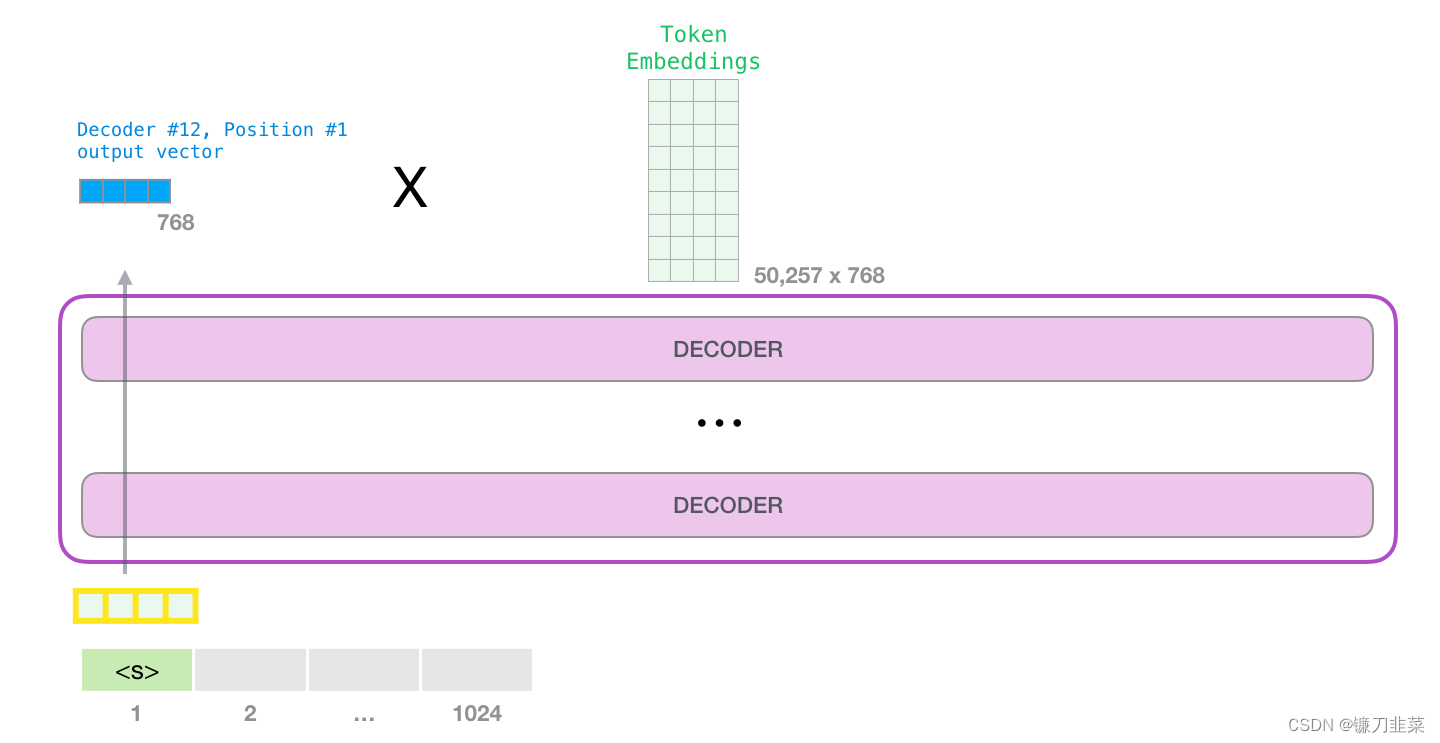
回忆一下,嵌入矩阵中的每一行都对应于模型词汇表中的一个词。这个相乘的结果,被解释为模型词汇表中每个词的分数。
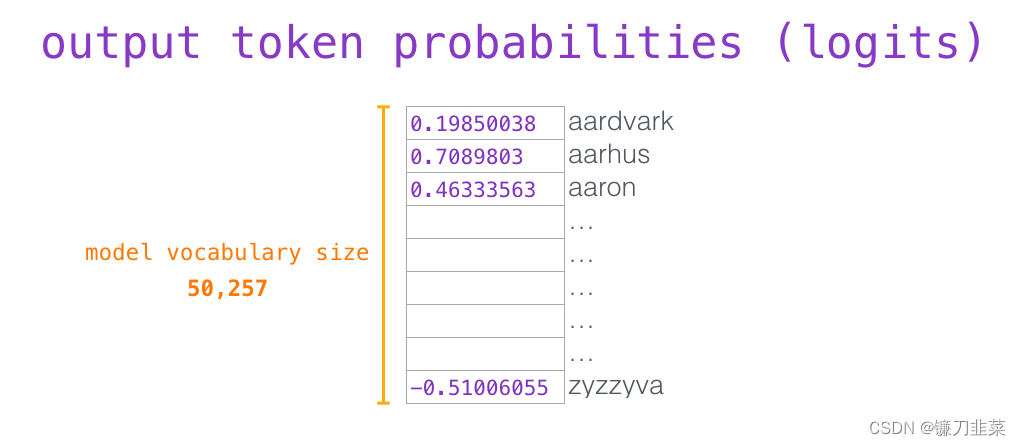
可以选择最高分数的 token(top_k=1)。但如果模型可以同时考虑其他词,那么可以得到更好的结果。所以一个更好的策略是把分数作为单词的概率,从整个列表中选择一个单词(这样分数越高的单词,被选中的几率就越高)。一个折中的选择是把 top_k 设置为 40,让模型考虑得分最高的 40 个词。
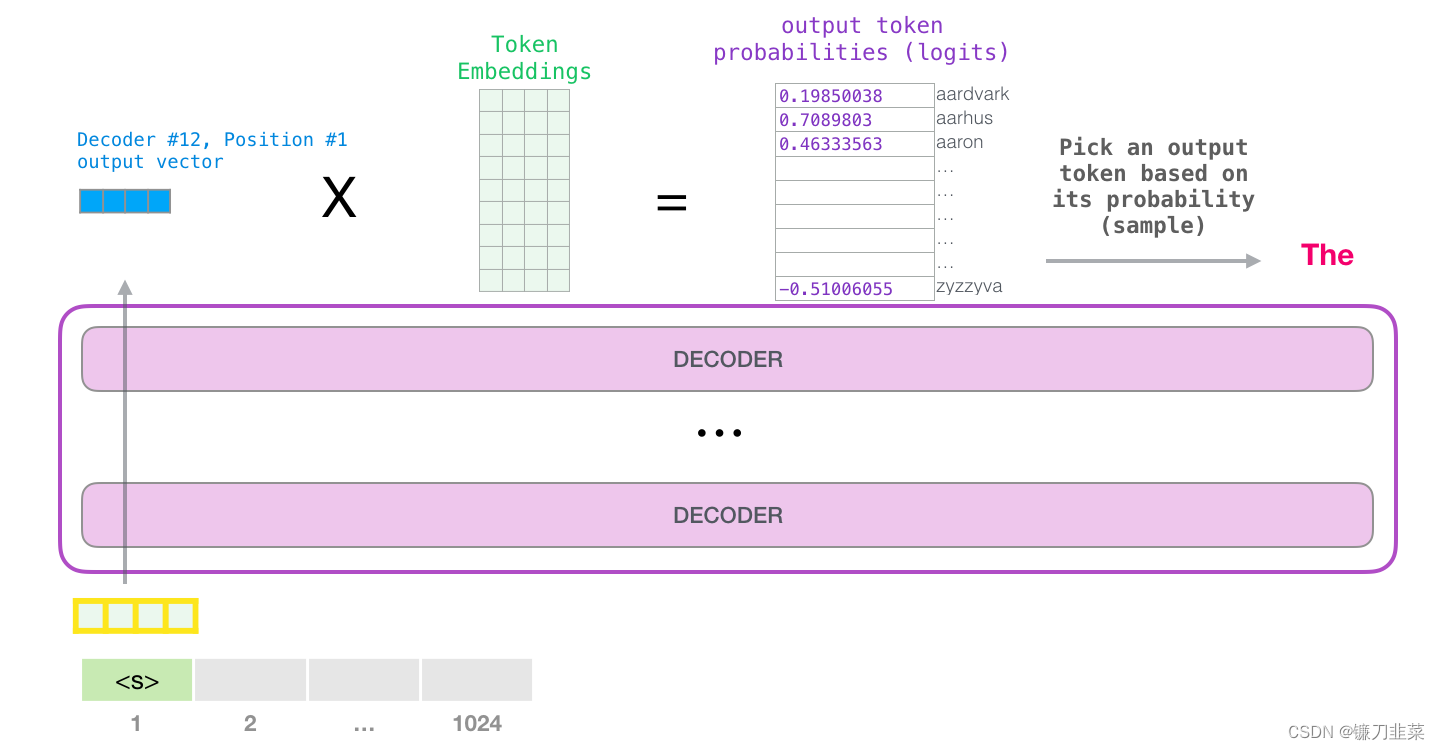
注意,图中Decoder #12,Position #1分别表示第12层Decoder,第1个标识符的位置。
这样,模型就完成了一次迭代,输出一个单词。模型会继续迭代,直到所有的上下文都已经生成(1024 个 token),或者直到输出了表示句子末尾的 token。
GPT与GPT-2的异同
GPT与GPT-2在架构上没有大的变化,只是在规模、数据量等略有不同,它们之间的异同具体体现在如下方面:
1)结构基本相同,都采用LM模型,使用Transformer的Decoder。
2)不同点如下:
- GPT-2的规模更大,层数更多
- GPT-2的数据量更大,数据类型更多,有利于增强模型的通用性,并对数据做了更多质量过滤和控制
- GPT对不同的下游任务采用有监督学习方式,修改输入格式,并添加一个全连接层。而GPT-2对下游任务采用无监督学习方式,不改变不同下游任务的参数及模型(即所谓的Zero-Shot Setting)。如下图所示:
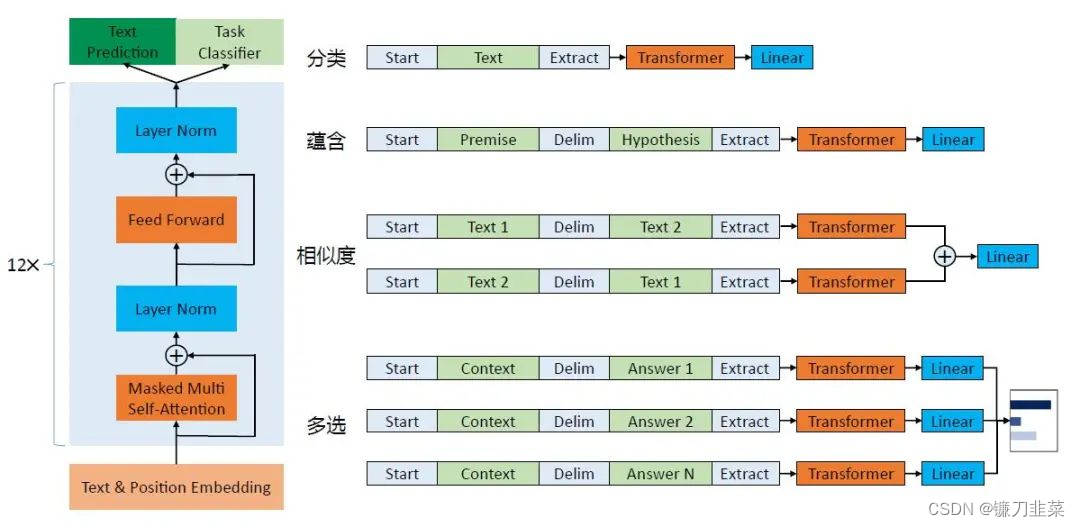
图(左)Transformer的架构和训练目标,图(右)对不同任务进行微调时输入的改造。
那么,GPT是如何改造下游任务的呢?在微调时,针对不同的下游任务,主要改动GPT的输入格式,先将不同任务通过数据组合,代入Transformer模型,然后在模型输出的数据后加全连接层(Linear)以适配标注数据的格式,具体说明如下:
1)分类问题,如果改动很少,只需要加上一个起始和终结符号即可;
2)句子关系判断问题,比如Entailment,两个句子中间再加上分隔符即可;
3)文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
4)多项选择问题,多路输入,每一路将文章和答案选项拼接起来作为一个输入即可。
GPT与ELMo的异同
- 模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder。
- 针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型。
GPT与BERT的异同
- 预训练:GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT 预训练的方式是使用 Mask LM,可以同时通过上文和下文预测单词。例如给定一个句子 u 1 , u 2 , . . . , u n u_1,u_2,...,u_n u1,u2,...,un,GPT在预测单词 u i u_i ui的时候只会利用 u 1 , u 2 , . . . , u i − 1 u_1,u_2,...,u_{i-1} u1,u2,...,ui−1的信息。而BERT会同时利用 u 1 , u 2 , . . . , u i − 1 , u i + 1 , . . . , u n u_1,u_2,...,u_{i-1},u_{i+1},...,u_n u1,u2,...,ui−1,ui+1,...,un的信息。
- 模型效果: GPT 因为采用了传统语言模型所以更加适合用于自然语言生成类的任务 (NLG),因为这些任务通常是根据当前信息生成下一刻的信息。而 BERT 更适合用于自然语言理解任务 (NLU)。
- 模型结构: 模型结构:GPT 采用了 Transformer 的 Decoder,而 BERT 采用了 Transformer 的 Encoder。GPT 使用 Decoder 中的 Mask Multi-Head Attention 结构,在使用 u 1 , u 2 , . . . , u i − 1 u_1,u_2,...,u_{i-1} u1,u2,...,ui−1预测单词 u i u_i ui 的时候,会将 u i u_i ui 之后的单词 Mask 掉。
参考资料
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Hugging face BERT
- 什么是BERT?
- https://ekbanaml.github.io/nlp/BERT/
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- Understanding BERT architecture
- 图解BERT模型:从零开始构建BERT
- BERT代码逐行逐句详解版
- The Illustrated GPT-2