文章目录
- 前言
- 爬虫总复习
- 工具
- 解析与提取(一)
- 解析与提取(二)
- 更厉害的请求
- 存储
- 更多的爬虫
- 更强大的爬虫——框架
- 给爬虫加上翅膀
- 爬虫进阶路线指引
- 解析与提取
- 存储
- 数据分析与可视化
- 更多的爬虫
- 更强大的爬虫——框架
- 项目训练
- 反爬虫应对策略汇总
- 写在最后的话
前言
很开心能和你在第16关相逢。至此,你已经完成所有关卡的知识学习,恭喜!
但这并不意味着这一关就可以敷衍相待,因为我们依然有非常重要的事情尚待完成。
我们会对过往的爬虫知识进行一个总复习,搭建起知识框架。当你在后面拿到任何一个爬虫需求,都能做到心中有数不慌张。
和许多学科一样,爬虫也是学个入门够用,但较起真来它也学无止境。所以,我会为你提供进阶学习的路线指引——如果想要继续在爬虫上有所精进,还可以学哪些内容。
而有爬虫,自然会有反爬虫。我们集中来讲讲,有哪些反爬虫的手段,又有哪些应对反爬虫的策略。
我又始终相信,每一门学科都会有一个超越它本身的精神内核,如果只是掌握技能而不能发现学科之美,实在太可惜。所以,在本关卡的最后,我留了一封短短的信给你,讲讲这门课背后的事。
我们现在就开始。
爬虫总复习
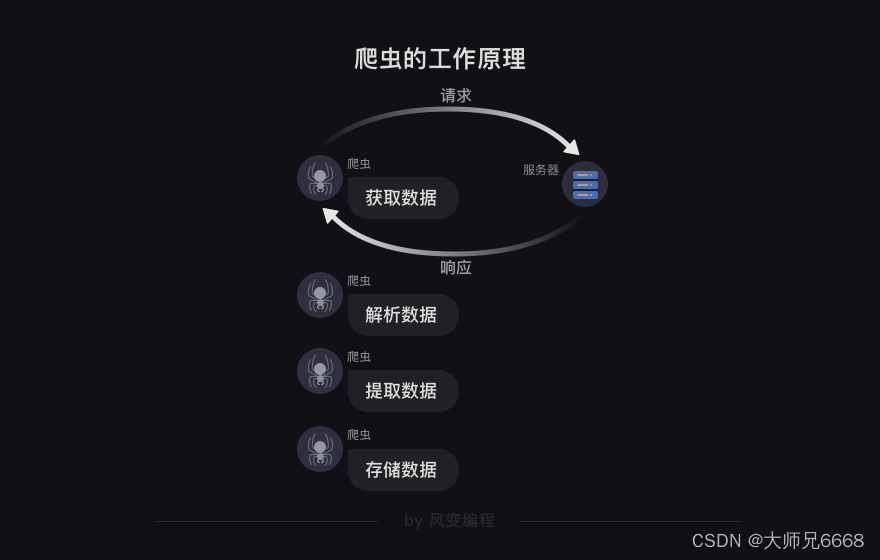
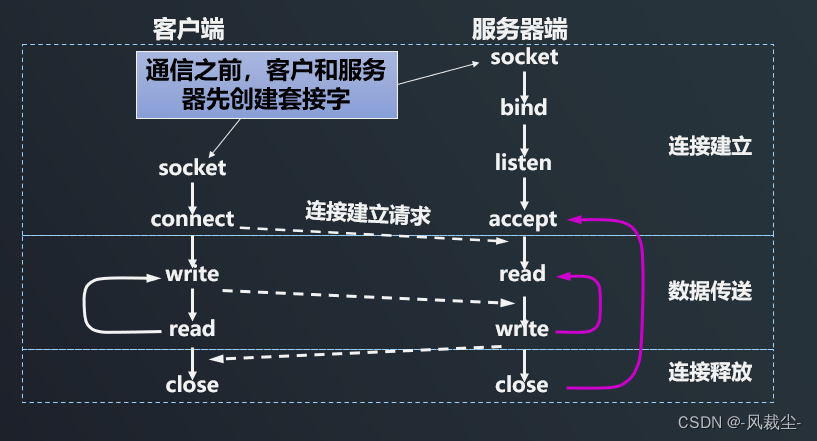
我还记得事情是从这张图开始的,它被用来描述浏览器的工作原理:

请求和响应。这两件事几乎构成了我们后面的所有学习内容。
在第0关,我们说爬虫,就是利用程序在网上拿到对我们有用的数据。程序所做的,最关键步骤正是“请求”和“响应”。
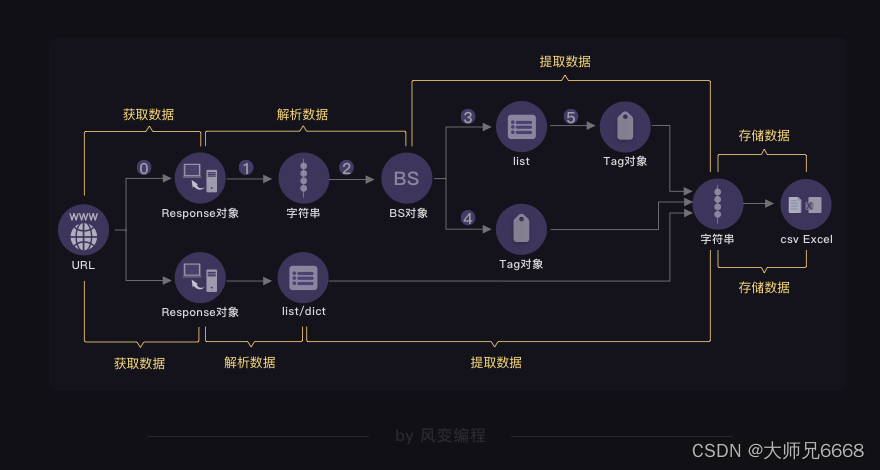
据此,我们定义了“爬虫四步”:获取数据(包含请求和响应两个动作)、解析数据、提取数据、存储数据。
同时,我们还学了最简单的请求方式:requests.get()
import requests
url = ''
response = requests.get(url)

工具
工欲善其事必先利其器,我们需要一个工具,在它的帮助下,我们能看到所有的请求,这样我们才能完成爬虫四步。这个工具,叫做Network。
Network能够记录浏览器的所有请求。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门这个,你不需要了解。
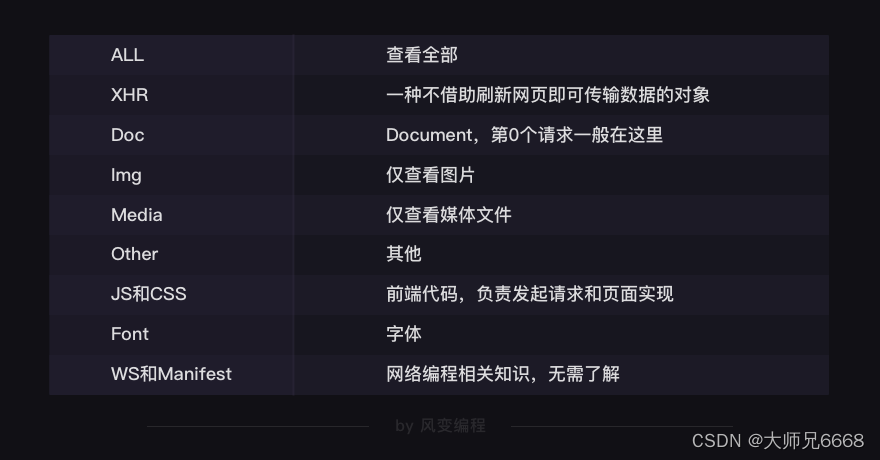
它们组成Elements中的所有内容,也就是你平时所见的网页万紫千红。
在爬虫里,我们最常用的是XHR和Doc。我们能在Doc里找到一个网页的源代码,而在网页源代码里找不到的信息,通常你都能在XHR里找到。有它的存在,人们不必刷新/跳转网页,即可加载新的内容。在今天,已经学过“同步/异步”概念的你,也可以说XHR帮我们实现了异步请求。
而数据究竟是藏身何处,在第6关,我们提供了一个方案:
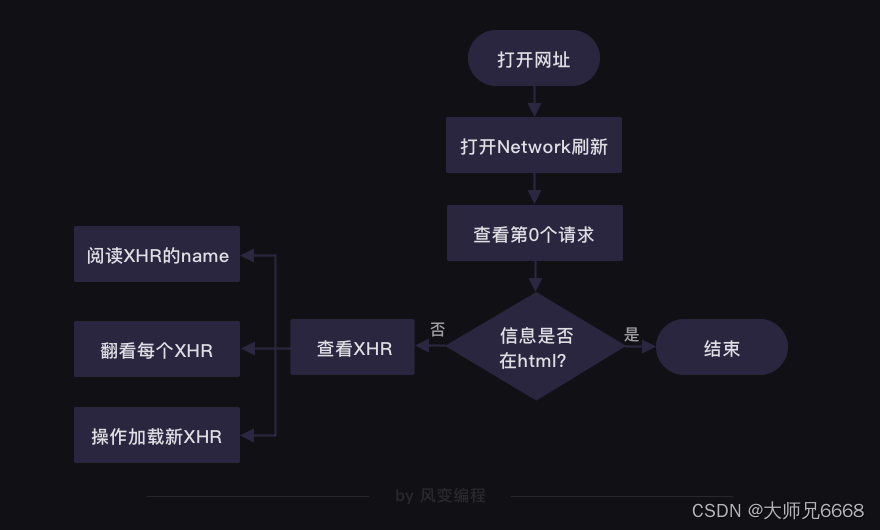
花开两朵,各表一枝。
解析与提取(一)
当数据藏匿于网页源代码,我们自有一条完整的“爬虫四步”链,在这里,最重要的库叫BeautifulSoup,它能提供一套完整的数据解析、数据提取解决方案。用法如下:
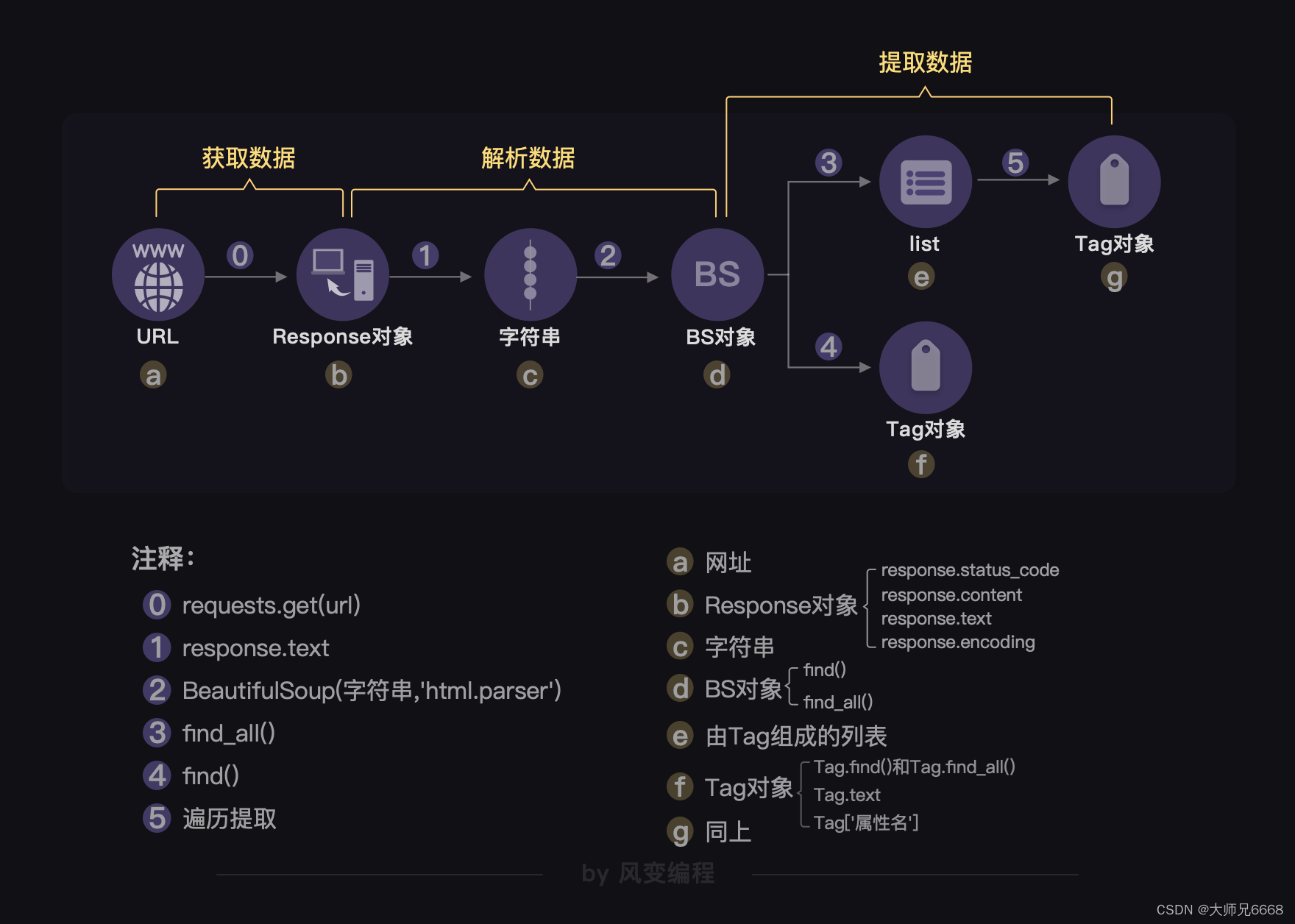
我们能写出类似这样的代码:
import requests
# 引用requests库
from bs4 import BeautifulSoup
# 引用BeautifulSoup库
res_foods = requests.get('http://www.xiachufang.com/explore/')
# 获取数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 解析数据
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含菜名和URL的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 查找包含食材的<p>标签
list_all = []
# 创建一个空列表,用于存储信息
for x in range(len(tag_name)):
# 启动一个循环,次数等于菜名的数量
list_food = [tag_name[x].text[18:-15],tag_name[x].find('a')['href'],tag_ingredients[x].text[1:-1]]
# 提取信息,封装为列表
list_all.append(list_food)
# 将信息添加进list_all
print(list_all)
# 打印
# 以下是另外一种解法
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 查找最小父级标签
list_all = []
# 创建一个空列表,用于存储信息
for food in list_foods:
tag_a = food.find('a')
# 提取第0个父级标签中的<a>标签
name = tag_a.text[18:-15]
# 菜名,使用[18:-15]切掉了多余的信息
URL = 'http://www.xiachufang.com'+tag_a['href']
# 获取URL
tag_p = food.find('p',class_='ing ellipsis')
# 提取第0个父级标签中的<p>标签
ingredients = tag_p.text[1:-1]
# 食材,使用[1:-1]切掉了多余的信息
list_all.append([name,URL,ingredients])
# 将菜名、URL、食材,封装为列表,添加进list_all
print(list_all)
# 打印
在此,我想额外强调的是编码问题,即便是许多爬虫老手也常常会在编码上重重地栽跟头,所以你不要也犯错。当response.text自动解码出问题,不要犹豫,自己动手使用response.encoding=''来对编码进行修改。
解析与提取(二)
我们来看事情的另一端——当数据在XHR中现身。
XHR所传输的数据,最重要的一种是用json格式写成的,和html一样,这种数据能够有组织地存储大量内容。json的数据类型是“文本”,在Python语言当中,我们把它称为字符串。我们能够非常轻易地将json格式的数据转化为列表/字典,也能将字典/列表转为json格式的数据。
如何解析json数据?答案如下:
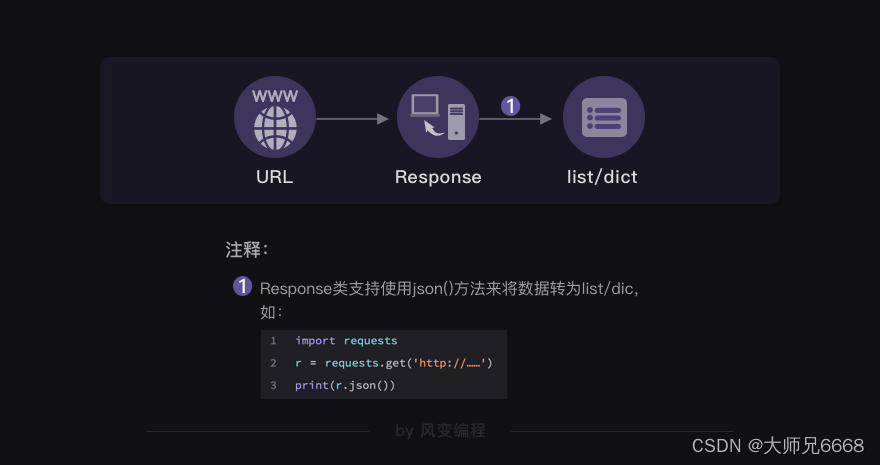
提取自然是不难的,毕竟都已经变成列表/字典。你对列表/字典,驾轻就熟。最后,你的脑海中多了这样一张图:
更厉害的请求
有趣的是请求本身。在过往的学习里,你的requests.get()里面其实只有一个参数,即url。
但其实,这个请求可以有多个参数。
params,可以让我们带着参数来请求数据:我想要第几页?我想要搜索的关键词?我想要多少个数据?
headers,请求头。它告诉服务器,我的设备/浏览器是什么?我从哪个页面而来?
再往后,你发现除了get请求之外,还存在着另一种请求方式——post。post区别于get的是:get是明文显示参数,post是非明文显示参数。学会post,你又有两个参数可用:
在post请求里,我们使用data来传递参数,其用法和params非常相像。
cookies,中文名很好听是“小饼干”。但它却和“小饼干”并无关联。它的作用是让服务器“记住你”,比如一般当你登录一个网站,你都会在登录页面看到一个可勾选的选项“记住我”。如果你点了勾选,服务器就会生成一个cookies和你的账号绑定。接着,它把这个cookies告诉你的浏览器,让浏览器把cookies存储到你的本地电脑。当下一次,浏览器带着cookies访问博客,服务器会知道你是何人,你不需要再重复输入账号密码,就能直接访问。
到这,考虑极端情况。你的代码可能会写成这个模样:
import requests
# 定义url_1,headers和data
url_1 = 'https://…'
headers = {'user-agent':''}
data = {}
login_in = requests.post(url,headers=headers,data=data)
cookies = login_in.cookies
# 完成登录,获取cookies
url_2 = 'https://…'
params = {}
# 定义url和params
response = requests.get(url,headers=headers,params=params,cookies=cookies)
# 带着cookies重新发起请求
存储
变着花地获取数据,变着花地解析数据,提取数据。都会让你来到最后一站:存储数据。
存储数据的方法有许多,其中最常见的是:csv和excel。


#csv写入的代码:
import csv
csv_file=open('demo.csv','w',newline='')
writer = csv.writer(csv_file)
writer.writerow(['电影','豆瓣评分'])
csv_file.close()

#csv读取的代码:
import csv
csv_file=open('demo.csv','r',newline='')
reader=csv.reader(csv_file)
for row in reader:
print(row)

#Excel写入的代码:
import openpyxl
wb=openpyxl.Workbook()
sheet=wb.active
sheet.title='new title'
sheet['A1'] = '漫威宇宙'
rows= [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:
sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')

#Excel读取的代码:
import openpyxl
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet=wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_value=sheet['A1'].value
print(A1_value)
更多的爬虫
从爬虫四步的角度来看,世上已经少有你搞不定的爬虫。因为所有的请求,你都能用Python代码模拟;所有的响应,你都懂得如何解析。当你在后面拿到任何一个爬虫需求,都能做到心中有数不慌张。
但是,如果要爬取的数据特别特别多,以至于程序会被拖得很慢怎么办?用协程。
同步与异步——
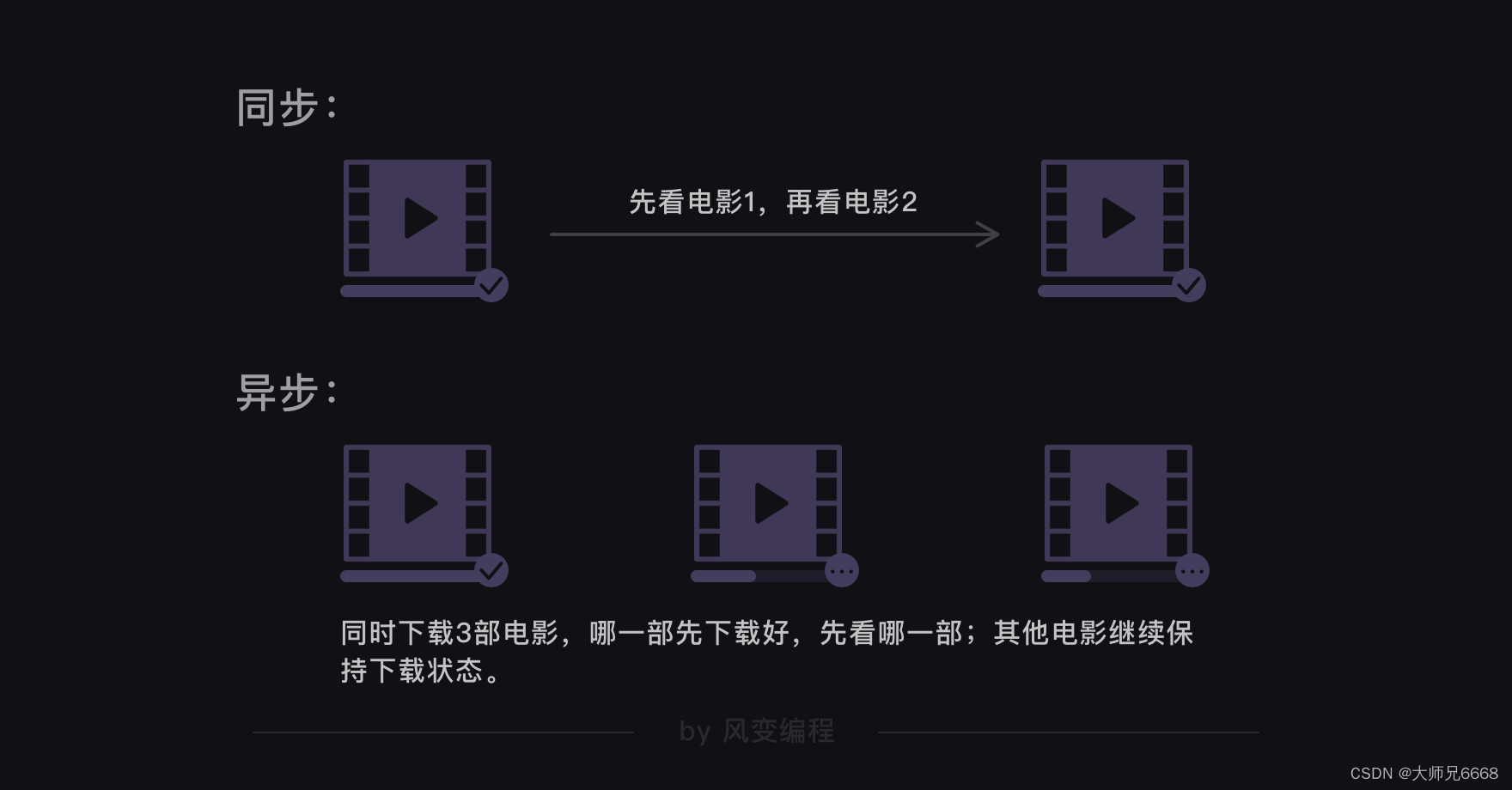
多协程,是一种非抢占式的异步方式。使用多协程的话,就能让多个爬取任务用异步的方式交替执行。


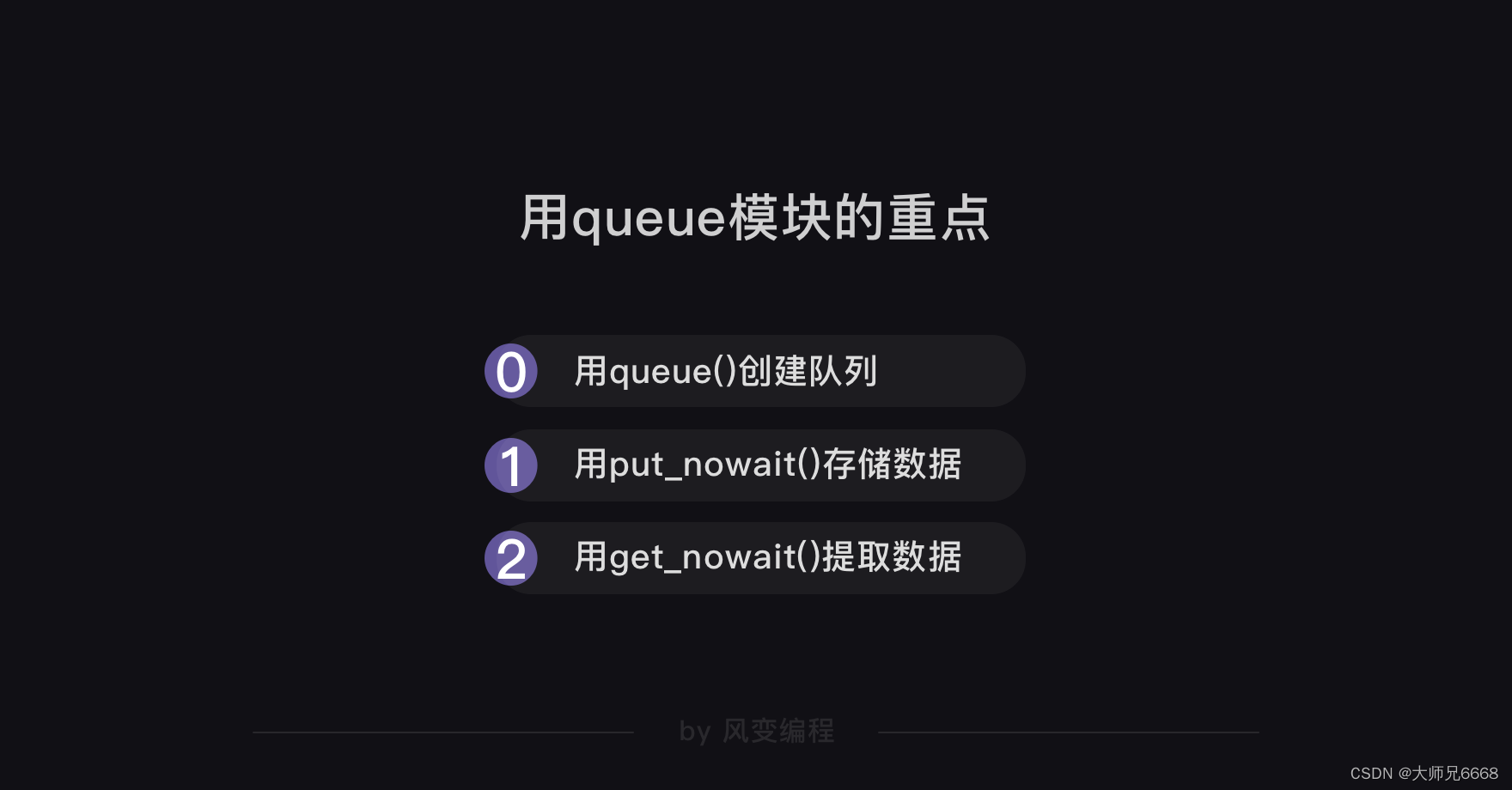
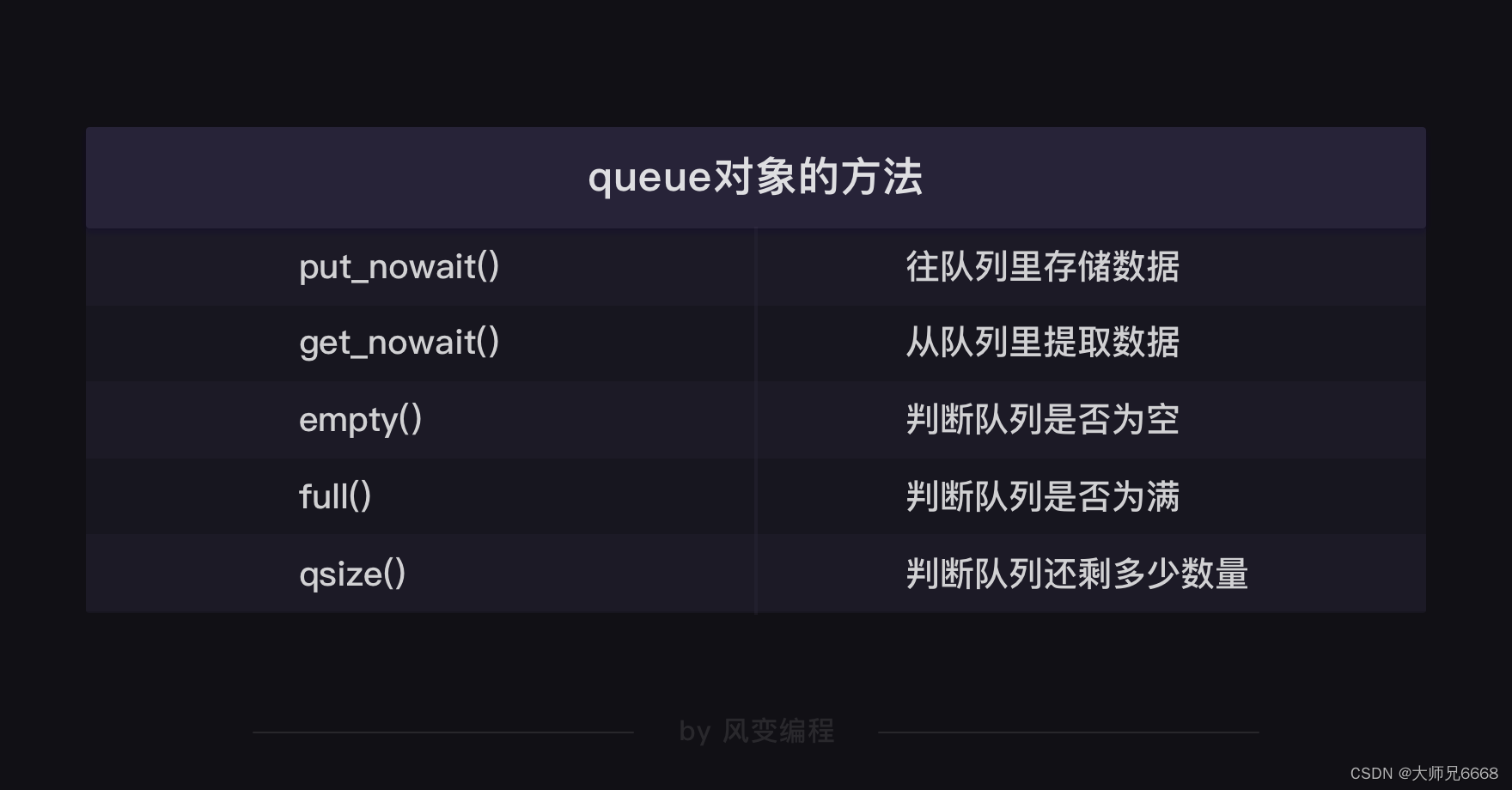
下为,示例代码:
import gevent,time,requests
from gevent.queue import Queue
from gevent import monkey
monkey.patch_all()
start = time.time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.sohu.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
work = Queue()
for url in url_list:
work.put_nowait(url)
def crawler():
while not work.empty():
url = work.get_nowait()
r = requests.get(url)
print(url,work.qsize(),r.status_code)
tasks_list = [ ]
for x in range(2):
task = gevent.spawn(crawler)
tasks_list.append(task)
gevent.joinall(tasks_list)
end = time.time()
print(end-start)
更强大的爬虫——框架
当你爬虫代码越写越多,一个一站式解决所有爬虫问题的框架,就对你越来越有吸引力。
Scrapy出现在你眼前。Scrapy的结构——
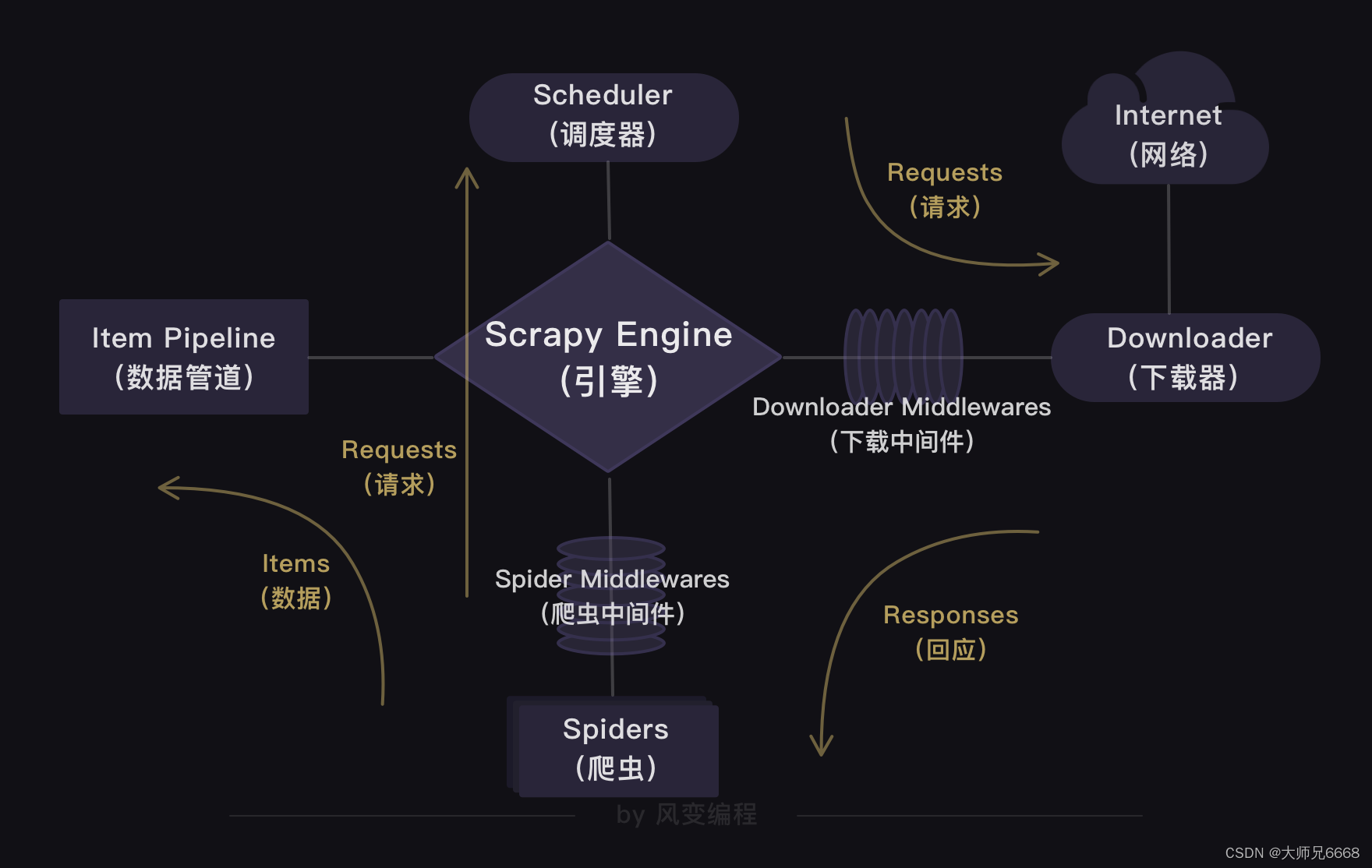
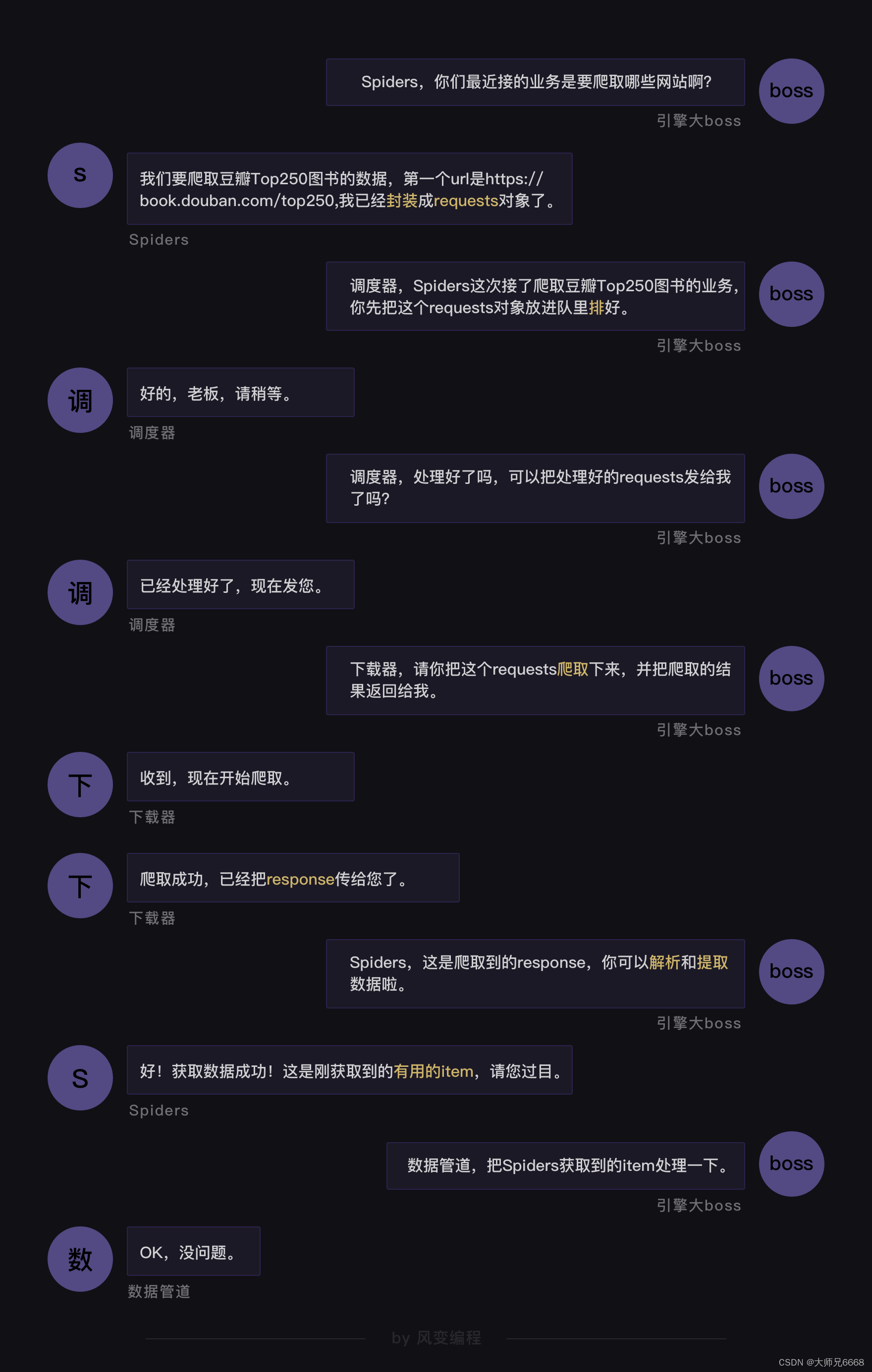
Scrapy的工作原理——
Scrapy的用法——

给爬虫加上翅膀
除了这条爬虫从无到有,从有到多,从多到强的主线路径之外。我们还穿插学习了三个有力工具:selenium,邮件通知和定时。
它们给爬虫增添上翅膀,能更方便地做更有趣的事。
先说selenium,我们学习了可视模式与静默模式这两种浏览器的设置方法,二者各有优势。
然后学习了使用.get(‘URL’)获取数据,以及解析与提取数据的方法。
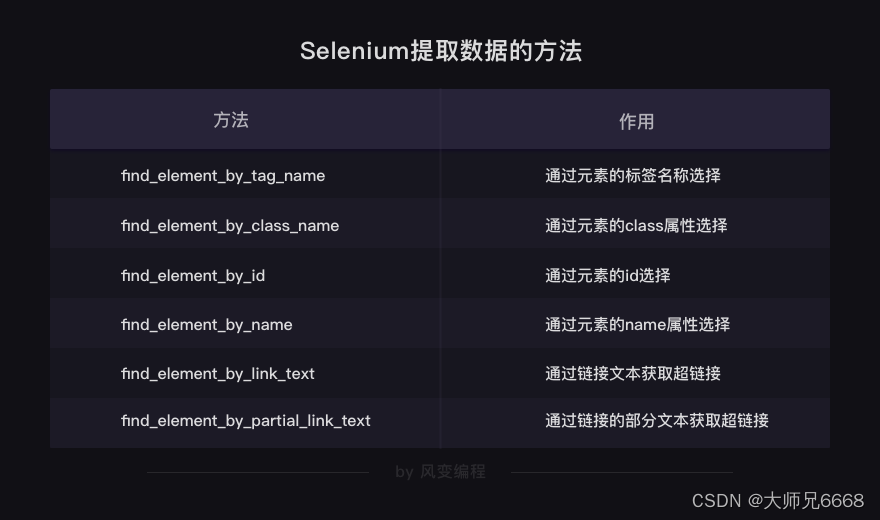
在这个过程中,对象的转换过程:

除了上面的方法,还可以搭配BeautifulSoup解析提取数据,前提是先获取字符串格式的网页源代码。
HTML源代码字符串 = driver.page_source
以及自动操作浏览器的一些方法。
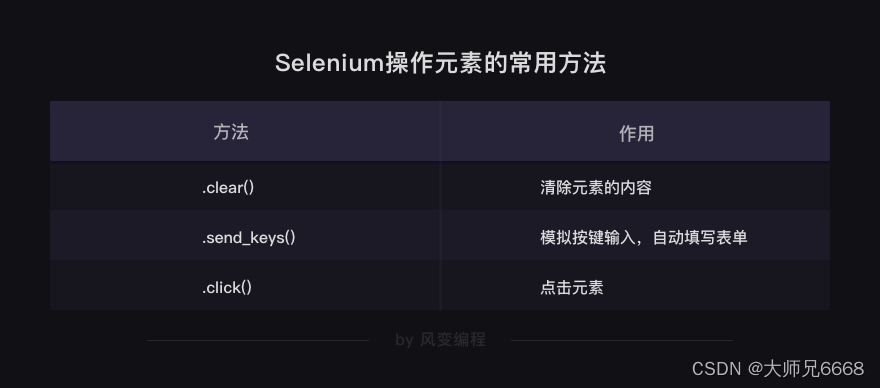
而关于邮件,它是这样一种流程:

我们要用到的模块是smtplib和email,前者负责连接服务器、登录、发送和退出的流程。后者负责填输邮件的标题与正文。
最后一个示例代码,是这个模样:
import smtplib
from email.mime.text import MIMEText
from email.header import Header
#引入smtplib、MIMEText和Header
mailhost='smtp.qq.com'
#把qq邮箱的服务器地址赋值到变量mailhost上,地址应为字符串格式
qqmail = smtplib.SMTP()
#实例化一个smtplib模块里的SMTP类的对象,这样就可以调用SMTP对象的方法和属性了
qqmail.connect(mailhost,25)
#连接服务器,第一个参数是服务器地址,第二个参数是SMTP端口号。
#以上,皆为连接服务器。
account = input('请输入你的邮箱:')
#获取邮箱账号,为字符串格式
password = input('请输入你的密码:')
#获取邮箱密码,为字符串格式
qqmail.login(account,password)
#登录邮箱,第一个参数为邮箱账号,第二个参数为邮箱密码
#以上,皆为登录邮箱。
receiver=input('请输入收件人的邮箱:')
#获取收件人的邮箱。
content=input('请输入邮件正文:')
#输入你的邮件正文,为字符串格式
message = MIMEText(content, 'plain', 'utf-8')
#实例化一个MIMEText邮件对象,该对象需要写进三个参数,分别是邮件正文,文本格式和编码
subject = input('请输入你的邮件主题:')
#输入你的邮件主题,为字符串格式
message['Subject'] = Header(subject, 'utf-8')
#在等号的右边是实例化了一个Header邮件头对象,该对象需要写入两个参数,分别是邮件主题和编码,然后赋值给等号左边的变量message['Subject']。
#以上,为填写主题和正文。
try:
qqmail.sendmail(account, receiver, message.as_string())
print ('邮件发送成功')
except:
print ('邮件发送失败')
qqmail.quit()
#以上为发送邮件和退出邮箱。
再说定时,我们选取了schedule模块,它的用法非常简洁,官方文档里是这样讲述:
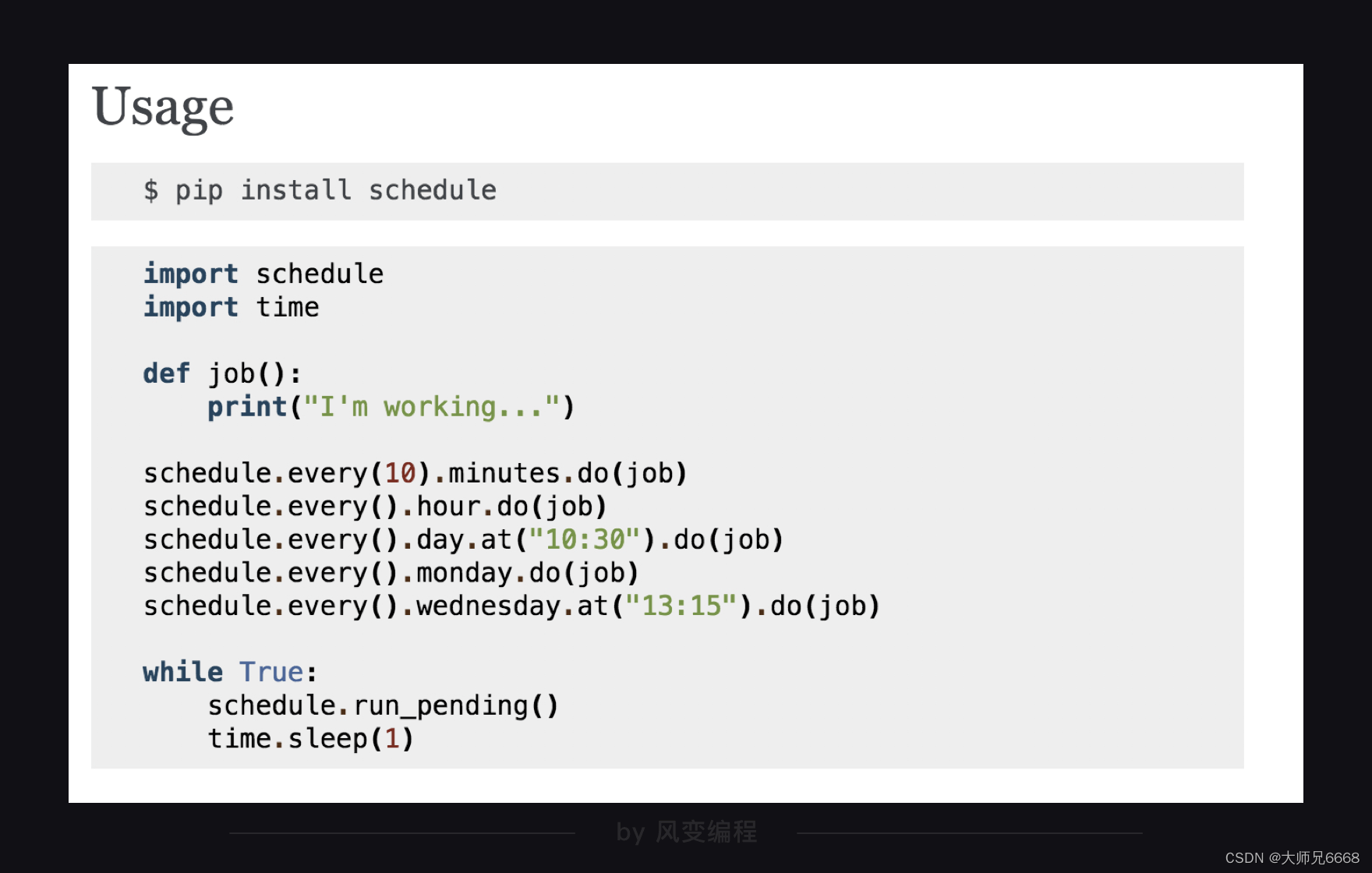
下面的代码是示例:
import schedule
import time
#引入schedule和time
def job():
print("I'm working...")
#定义一个叫job的函数,函数的功能是打印'I'm working...'
schedule.every(10).minutes.do(job) #部署每10分钟执行一次job()函数的任务
schedule.every().hour.do(job) #部署每×小时执行一次job()函数的任务
schedule.every().day.at("10:30").do(job) #部署在每天的10:30执行job()函数的任务
schedule.every().monday.do(job) #部署每个星期一执行job()函数的任务
schedule.every().wednesday.at("13:15").do(job)#部署每周三的13:15执行函数的任务
while True:
schedule.run_pending()
time.sleep(1)
#15-17都是检查部署的情况,如果任务准备就绪,就开始执行任务。
以上,就是我们在爬虫系列关卡当中所学到的全部内容。
爬虫进阶路线指引
正如我们前文所说,爬虫学个入门够用,但较起真来它也学无止境。下面,我们会讲讲,如果想继续深入地学习爬虫,还可以学哪些内容。
对照着我们的爬虫学习路径,进阶指引也分这几个板块:解析与提取、存储、数据分析与可视化(新增)、更多的爬虫、框架,以及其他。
对于这些知识,许多简单的你已经可以通过自学官方文档,掌握它们的使用方法。而对于一些复杂的,尤其是需要项目训练的知识,你可能觉得学习它们有些困难。这部分,未来我自己研究的时候也会再整理出来和大家分享。
解析与提取
当我们说要学习解析和提取,是指学习解析库。除了我们关卡里所用的BeautifulSoup解析、Selenium的自带解析库之外,还会有:xpath/lxml等。它们可能语法有所不同,但底层原理都一致,你能很轻松上手,然后在一些合适的场景,去用它们。
如果说上述解析库,学或不学都影响不大,那么我要隆重地推荐你去学习正则表达式(re模块)。正则表达式功能强大,它能让你自己设定一套复杂的规则,然后把目标文本里符合条件的相关内容给找出来。举个例子,我们在第6关时,会爬取一首歌的歌词,拿到的文本里面会充斥着各种符号。

根据我们之前学到的知识,只能一遍又一遍,不厌其烦地切片。但用正则,就能很轻易地解决这个问题。
存储
说到存储,我们目前已经掌握的知识是csv和excel。它们并不是非常高难度的模块,我会推荐你翻阅它们的官方文档,了解更多的用法。这样,对于平时的自动化办公也会有所帮助。
但是当数据量变得十分巨大(这在爬虫界并不是什么新鲜事),同时数据与数据之间的关系,应难以用一张简单的二维平面表格来承载。那么,你需要数据库的帮助。
我推荐你从MySQL和MongoDB这两个库开始学起,它们一个是关系型数据库的典型代表,一个是非关系型数据库的典型代表。
当然,或许你会好奇什么是关系型数据库,什么是非关系型数据库。简单来说,我去设计两份表格,一张存储风变编程用户们的账户信息(昵称,头像等),一张则存储用户们的学习记录。两个表格之间,通过唯一的用户id来进行关联。这样的就是关系型数据库。没有这种特征的,自然就是非关系型数据库。
学习数据库,需要你接触另一种语言:SQL。不过它也并不难学,加油!
数据分析与可视化
徒有海量的数据的意义非常有限。数据,要被分析过才能创造出更深远的价值。举个例子:拿到全中国麦当劳门店的地址和营收数据意义并不大,但如果能从中总结出快餐店的最优策略,这就能指导商业决策。
拿到携程网上,用户对深圳欢乐谷的所有评论,意义并不大。但从中分析总结出用户游玩时真正在意的点,那就很有趣。
这里边的技能,叫做数据分析。将数据分析的结论,直观、有力地传递出来,是可视化。
认真来讲,这可并不是很简单的技能。学习数据分析,要比爬虫还要花费更多的时间。所以未来,我一定也会去做这方面的关卡,帮助大家掌握它。
如果你希望自己学习它,这是我推荐的模块与库:Pandas/Matplotlib/Numpy/Scikit-Learn/Scipy。
更多的爬虫
当你有太多的数据要爬取,你就要开始关心爬虫的速度。在此,我们介绍了一个可以让多个爬虫一起工作的工具——协程。
严格来说这并不是同时工作,而是电脑在多个任务之间快速地来回切换,看上去就仿佛是爬虫们同时工作。
所以这种工作方式对速度的优化有瓶颈。那么,如果还想有所突破还可以怎么做?
我们已经知道,协程在本质上只用到CPU的一个核。而多进程(multiprocessing库)爬虫允许你使用CPU的多个核,所以你可以使用多进程,或者是多进程与多协程结合的方式进一步优化爬虫。
理论上来说,只要CPU允许,开多少个进程,就能让你的爬虫速度提高多少倍。
那要是CPU不允许呢?比如我的电脑,也就8核。而我想突破8个进程,应该怎么办?
答,分布式爬虫。什么意思呢?分布式爬虫,就是让多个设备,去跑同一个项目。
我们去创建一个共享的队列,队列里塞满了待执行的爬虫任务。让多个设备从这个共享队列当中,去获取任务,并完成执行。这就是分布式爬虫。
如此,就不再有限制你爬虫的瓶颈——多加设备就行。在企业内,面对大量爬虫任务,他们也是使用分布式的方式来进行爬虫作业。
实现分布式爬虫,需要下一个组块的内容——框架。
更强大的爬虫——框架
目前,我们已经简单地学过Scrapy框架的基本原理和用法。而一些更深入的用法:使用Scrapy模拟登录、存储数据库、使用HTTP代理、分布式爬虫……这些就还不曾涉及。
不过好消息是,这些知识对于今天的你来说,大数都能轻松上手。因为它们的底层逻辑,你都已掌握,剩下的,不过是一些语法问题罢了。
我会推荐你先去更深入地学习、了解Scrapy框架。然后再了解一些其他的优秀框架,如:PySpider。
项目训练
现在,当你再去一些招聘网站上去浏览“爬虫工程师”的字样时,它的工作描述,已经不再有会让你陌生的字眼。
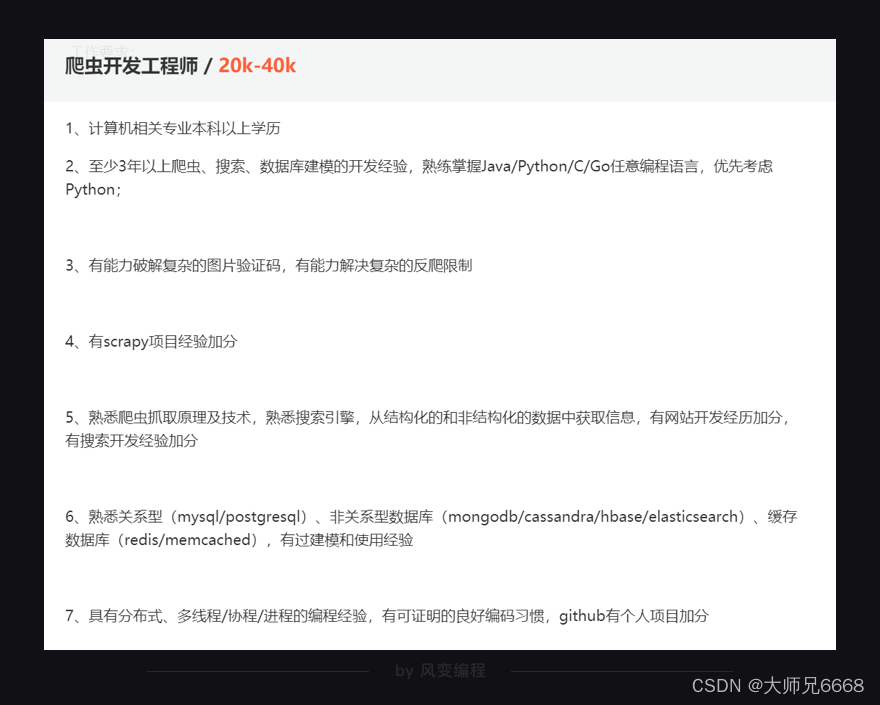
你开始觉得,或许自己再补充一些知识学习,也能够胜任。那么中间缺的是什么?
上述的模块/库/框架并不是那样重要,因为它们都是易于掌握的工具。对于一个爬虫工程师来说最重要的,是达成目标的思维。
相信你已经能感受到,在我们所有的项目型关卡里,都遵循着这三个核心步骤:确认目标、分析过程和代码实现(对于复杂项目,也要去做代码封装)。
其中,难度最大的不是代码实现,也不是代码封装,而是:确认一个合理的目标,分析这个目标如何实现,设计这些工具模块如何组合应用。
我们所学习的爬虫四步:获取数据、解析数据、提取数据和存储数据,都服务于“分析过程”这一步。
我要的数据在哪?怎么拿到数据?怎么更快地拿到数据?怎么更好地存储数据……这个,都属于“达成目标的思维”。
获取这种思维,需要大量的项目实操练习。
所以我想推荐你:完成我所提供的所有项目练习;多读一读,编程前辈们的博客、github主页学习案例;同时,探索更多的项目实操,丰富自己的爬虫经验。
在未来,如果我再设计更进阶的爬虫课程,教授正则、进程、分布式……的知识,也一定会将大量项目实操作为主线。
反爬虫应对策略汇总
说完了进阶路线指引,我们来说反爬虫。几乎所有的技术人员对反爬虫都有一个共识:所谓的反爬虫,从不是将爬虫完全杜绝;而是想办法将爬虫的访问量限制在一个可接纳的范围,不要让它过于肆无忌惮。
原因很简单:爬虫代码写到最后,已经和真人访问网络毫无区别。服务器的那一端完全无法判断是人还是爬虫。如果想要完全禁止爬虫,正常用户也会无法访问。所以只能想办法进行限制,而非禁止。
所以,我们可以了解有哪些“反爬虫”技巧,再思考如何应对“反爬虫”。
有的网站会限制请求头,即Request Headers,那我们就去填写user-agent声明自己的身份,有时还要去填写origin和referer声明请求的来源。
有的网站会限制登录,不登录就不给你访问。那我们就用cookies和session的知识去模拟登录。
有的网站会做一些复杂的交互,比如设置“验证码”来阻拦登录。这就比较难做,解决方案一般有二:我们用Selenium去手动输入验证码;我们用一些图像处理的库自动识别验证码(tesserocr/pytesserart/pillow)。
有的网站会做IP限制,什么意思呢?我们平时上网,都会有携带一个IP地址。IP地址就好像电话号码(地址码):有了某人的电话号码,你就能与他通话了。同样,有了某个设备的IP地址,你就能与这个设备通信。
使用搜索引擎搜索“IP”,你也能看到自己的IP地址。
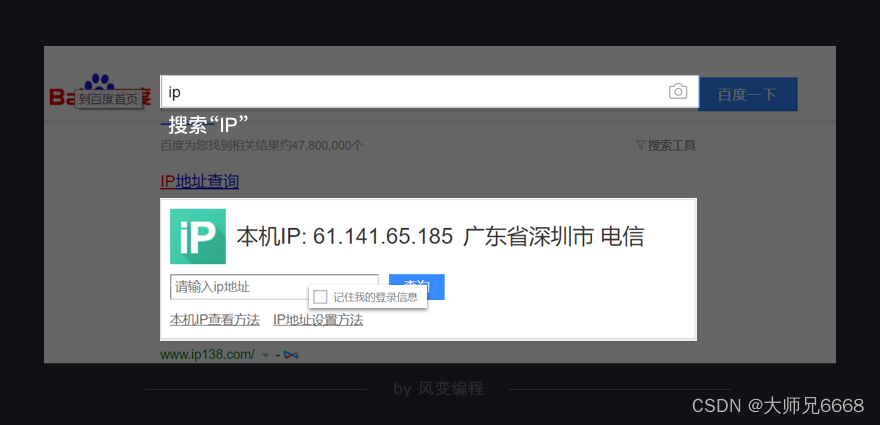
如上,它显示出了某个IP地址,所用的网络通信服务商是深圳电信。如果这个IP地址,爬取网站频次太高,那么服务器就会暂时封掉来自这个IP地址的请求。
解决方案有二:使用time.sleep()来对爬虫的速度进行限制;建立IP代理池(你可以在网络上搜索可用的IP代理),一个IP不能用了就换一个用。大致语法是这样:
import requests
url = 'https://…'
proxies = {'http':'http://…'}
# ip地址
response = requests.get(url,proxies=proxies)
以上,就是市面上最常见的反爬虫策略,以及对应的应对策略。你会发现没什么能真正阻拦你。这正印证了那句话:所谓的反爬虫,从不是将爬虫完全杜绝;而是想办法将爬虫的访问量限制在一个可接纳的范围,不要让它过于肆无忌惮。
写在最后的话
一直以来,我都相信:每一门学科,都有它的独特气质在里面,它对人影响深远。如果你要做教育,单纯地把知识讲透不够,需要把那种东西表达出来。
古人说“传道授业解惑”中的“传道”,讲的是这样一回事。
那么,在“爬虫”这里,有什么是与众不同的?
我咨询过很多身边写爬虫很厉害的前辈:你们平时怎么写爬虫?写爬虫时候,最重要的是什么?
他们给了许多种不同的说法,但这些说法都指向同一个答案:
确认目标-分析过程-先面向过程一行行实现代码-代码封装。
在这,最重要的是确认目标,最难的是分析过程。写代码,不过是水到渠成的事。
在这个过程里,你会遇到很多困难。但是没关系,遇到困难就去学习,就去查文档,总能够找到解决方案。
在编程的世界,几乎没什么是不可能。
正是听到了他们这样的答复,我把关卡设计成了现在的模样:处处都是确认目标-分析过程-代码实现(有时还有代码封装)。
这个过程中,我们会遇到困难。那么,我们去学习新的知识,去查文档。而每遇一新知识,我们必要弄个明白它是什么,它应如何使用,实操去使用。
为了大家更好地完成最难的“分析过程”,我们提出了爬虫四步:获取数据-解析数据-提取数据-存储数据。
我想,这正是爬虫的这16个关卡所期望表达的东西:没什么目标是你不可凭努力与智慧实现,没什么困难你不可凭努力与智慧逾越。
逢山开路,遇水架桥,不甘庸碌渡一生的人心怀梦想,梦想即目标。
目标即可被分析过程,分析清楚即可被实现。
在这个过程中,或许会遇到困难。没关系,困难都能找到解决方案。
逢山开路,遇水架桥。
或许你觉着我在讲一个鸡汤的事。不是,我在讲理论,我在讲已发生在你身上的经历。
说是理论,最近一些年,除了技术之外,我浸心于一门叫做“认知心理学”的学科。它所研究的,是人的认知过程。读起来,实在是有趣极了。
在这本书里,让我印象最深的一章节,叫做“问题解决”,讨论的是人是如何解决问题的。最后,得出的一个关键结论是,人类最有效地解决问题方式,是“目标-手段分析法”。
确认目标,一层一层地分解,大问题变一组小问题,每一个小问题都有实现的手段,然后去做就好。事情仿佛就是这样简单。
但事情不是这样简单。
我不知道你是否还记得第5关的样子。那时,你刚刚学会BeautifulSoup,你接到一个需求:爬取周杰伦的歌曲信息。
你确认目标-分析过程-然后代码实现。突然,事情的结果却在预期之外——没拿到想要的数据。
你并不会因此而感到慌张,为什么?
因为我们的每一步过程,都是非常清晰地推理得来。我们能很容易定位到问题——一步步反推回去就好。
是提取错了吗?检查,不是。是解析错了吗?检查,不是。那定是获取数据错了。我们去重新分析过程:去学习新的知识——XHR,去查文档——解析json数据。
同理,当我们所做的事情不及预期,我们可以检查是执行错了吗?不是,那是手段错了吗?如果还不是,那就需要思考,是不是目标制定有问题。
坚持这样思考,我相信在你的生活里,一切事物都可以是明确而可实现的。即便出了问题,也能清晰地溯源。
你逢山开路,你从不慌张。以上,就是我想要告诉你所有的事情。
加油!你终将成为梦想中的大神!


![[国产MCU]-W801开发实例-MQTT客户端通信](https://img-blog.csdnimg.cn/f6159728c6d74fc8bb888e440eddc698.png#pic_center)

![[github-100天机器学习]day4+5+6 Logistic regression](https://img-blog.csdnimg.cn/d4c502b7452343e9b4da0dfbd52be367.png)