参考:
https://github.com/vllm-project/vllm
https://zhuanlan.zhihu.com/p/645732302
https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html ##文档
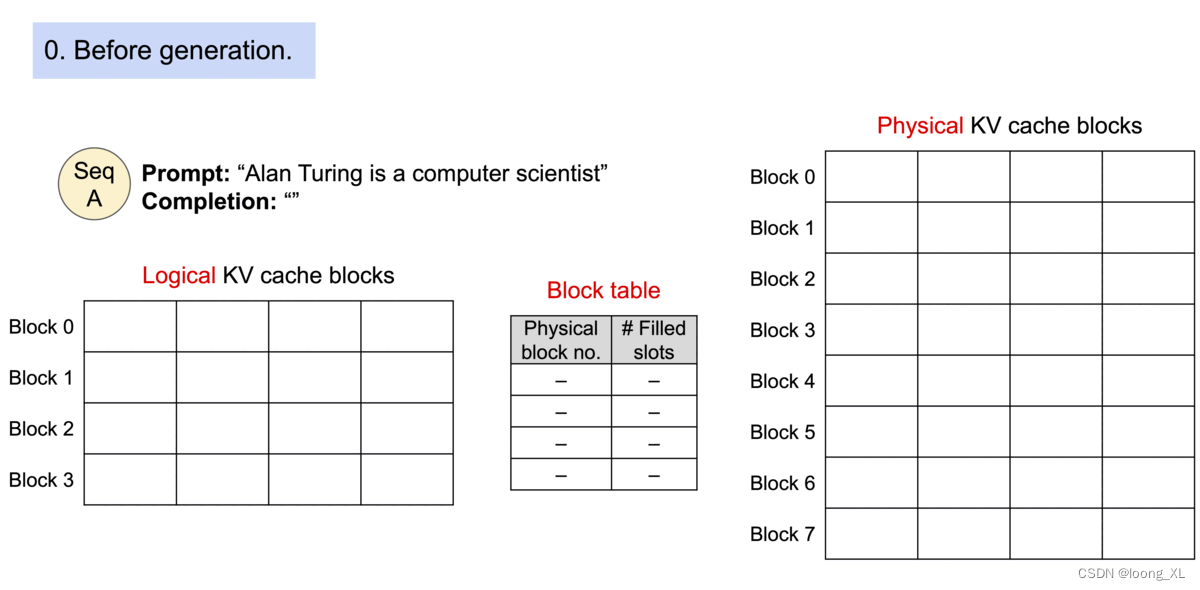
加速原理:
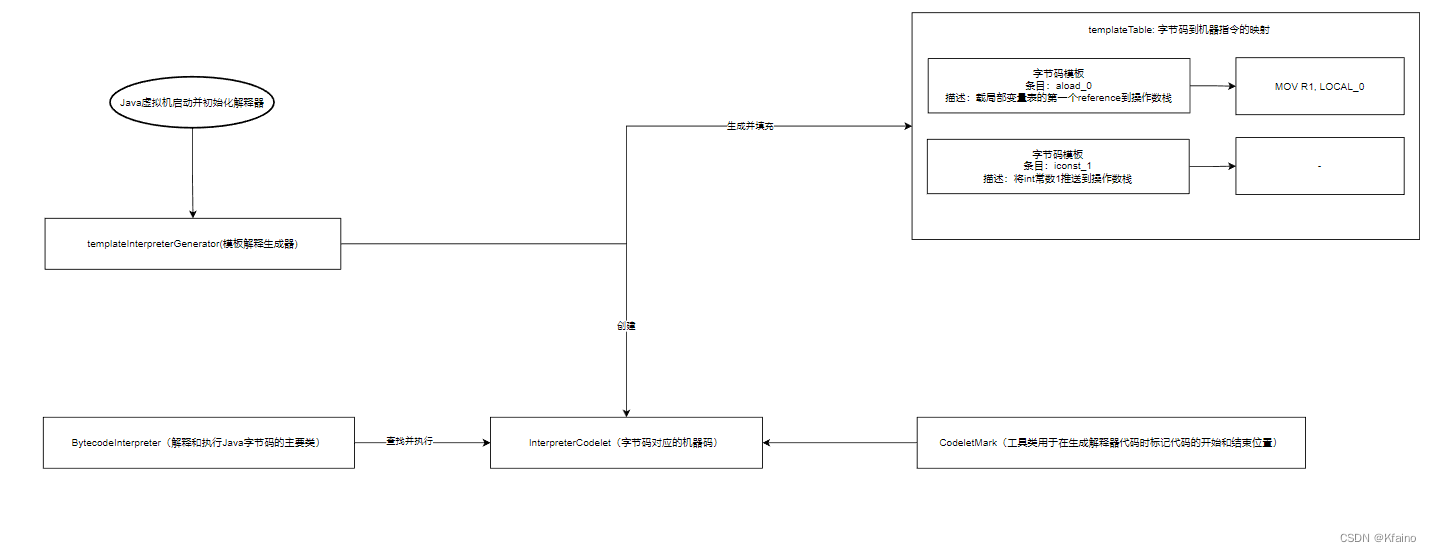
PagedAttention,主要是利用kv缓存
使用:
##启动正常api服务
python -m vllm.entrypoints.api_server --model ./qwen-6b-model --swap-space 16 --disable-log-requests --host 192.168.19.14 --port 10860 --max-num-seqs
256 --trust-remote-code --tensor-parallel-size 2
##启动openai形式 api服务
python -m vllm.entrypoints.openai.api_server --model ./qwen-6b-model --swap-space 16 --disable-log-requests --host 192.168.19.14 --port 10860 --max-nu
m-seqs 256 --trust-remote-code --tensor-parallel-size 2

api访问:
import requests
import json
headers = {"User-Agent": "Test Client"}
pload = {
"prompt": "你能做什么",
"n": 2,
"use_beam_search": True,
"temperature": 0.0,
"max_tokens": 16,
"stream": False,
}
response = requests.post("http://192.168.19.14:10860/generate", headers=headers, json=pload, stream=True)
print(response)
print(json.loads(response.content)["text"])
问题
现在中文qwen模型运行返回的基本都是乱码,不知道是不是vLLM支持的问题?