引言
Java虚拟机(JVM)和其复杂性
在我们先前探讨的文章中,我们已经深入到了Java虚拟机(JVM)的内部,透视了其如何通过元空间存储类的元数据和字节码。JVM的设计初衷是为了实现跨平台兼容性,但随着时间的推移,为了去满足性能和优化的需求,它的结构变得越来越复杂。
执行引擎的角色:为什么保留字节码
JVM中的元空间确实包含了大量的元数据,这些元数据为运行时提供了关于类、方法和字段的重要信息。但为什么在有了这么丰富的元数据之后,JVM还需要保留字节码呢?
答案就在执行引擎。执行引擎是JVM的核心部分,它负责将字节码翻译为可以在特定硬件上运行的机器代码。但是,这并不是一次性的过程。为了提高性能,JVM会使用Just-In-Time (JIT) 编译技术,将“热点”代码段编译成机器代码,从而大大加速程序的执行速度。
因此,尽管元数据为JVM提供了关于类和方法的大量信息,但字节码的存在是为了允许执行引擎进行即时编译优化。这个细节不仅揭示了JVM的优雅设计,也为我们展现了Java为什么能在保持跨平台特性的同时,还能提供出色的性能。
在本篇文章中,我们将更深入地探讨执行引擎,了解其如何与其他JVM组件协同工作,以及如何利用现代硬件的特性来提高Java应用的性能。
基本结构与组件
在深入探索Java虚拟机(JVM)的执行引擎之前,我们首先需要了解其主要组成部分和功能。执行引擎是JVM中的一个核心组件,负责管理和执行Java字节码。它主要由以下部分组成:
1. 字节码解释器
在Java程序初次运行时,大多数的字节码是由解释器执行的。解释器逐行读取字节码并翻译成本地机器指令执行。这种方法虽然跨平台,但效率相对较低,因为每次执行相同的字节码都需要重新解释。
字节码解释器的核心是一个巨大的switch-case结构,用于处理每一个Java字节码指令。源码位于:bytecodeInterpreter.cpp。部分源码如下,是不是很熟悉?
//...
CASE(_bipush):
SET_STACK_INT((jbyte)(pc[1]), 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(2, 1);
/* Push a 2-byte signed integer constant onto the stack. */
CASE(_sipush):
SET_STACK_INT((int16_t)Bytes::get_Java_u2(pc + 1), 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
/* load from local variable */
CASE(_aload):
VERIFY_OOP(LOCALS_OBJECT(pc[1]));
SET_STACK_OBJECT(LOCALS_OBJECT(pc[1]), 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(2, 1);
//...
上述代码展示了解释器如何处理不同的字节码。对于每一种字节码,解释器都有相应的操作来翻译并执行。
逐行解析字节码也太慢了,有办法优化吗?
2. JIT编译器(Just-In-Time Compiler)
为了提高执行效率,JVM引入了JIT编译器。当某部分代码被频繁执行(称为“热点”代码)时,JIT编译器会将这部分字节码编译成本地机器代码。这样,下次执行时,JVM可以直接运行这段已编译的机器代码,从而大大提高执行速度。
JIT编译器的工作是将热点代码编译为本地机器代码。这就是为什么我上篇的元空间中既有类元信息又要有字节码。
对于一个经常被调用的方法,JIT可能会这样处理,我写了一个伪代码,你可以看下:
if (method->is_hot()) {
// 通过C2编译成机器码
compile_method_with_c2_compiler(method);
} else {
// 解释
interpret_method(method);
}
C2是啥?我们接着往下看
JVM采用分层编译策略,其中C1和C2是两个主要的编译器。C1,也称为客户端编译器,提供快速编译,但优化程度较低。而C2,也称为服务器编译器,提供高级优化,但编译速度较慢。
在OpenJDK中,有两个主要的JIT编译器:C1和C2。C1编译器快速,但优化较少,而C2编译器则进行深度优化。
if (UseC1Compiler) {
// 使用C1编译器
} else if (UseC2Compiler) {
// 使用C2编译器
}
3. 垃圾收集器
尽管垃圾收集主要与内存管理相关,但它与执行引擎紧密相连。执行引擎需要与垃圾收集器协同工作,以确保在执行Java代码时,不会因为内存问题而中断或崩溃。
字节码解释器
和解释器相关的其它类
当Java源代码被编译后,它转化为一个或多个字节码文件(.class文件)。这些文件包含了JVM可解释和执行的指令集。Java字节码是源代码和机器代码之间的中间表示形式。
前面我简单介绍了一下字节码执行核心BytecodeInterpreter,我们来介绍一下其它角色:
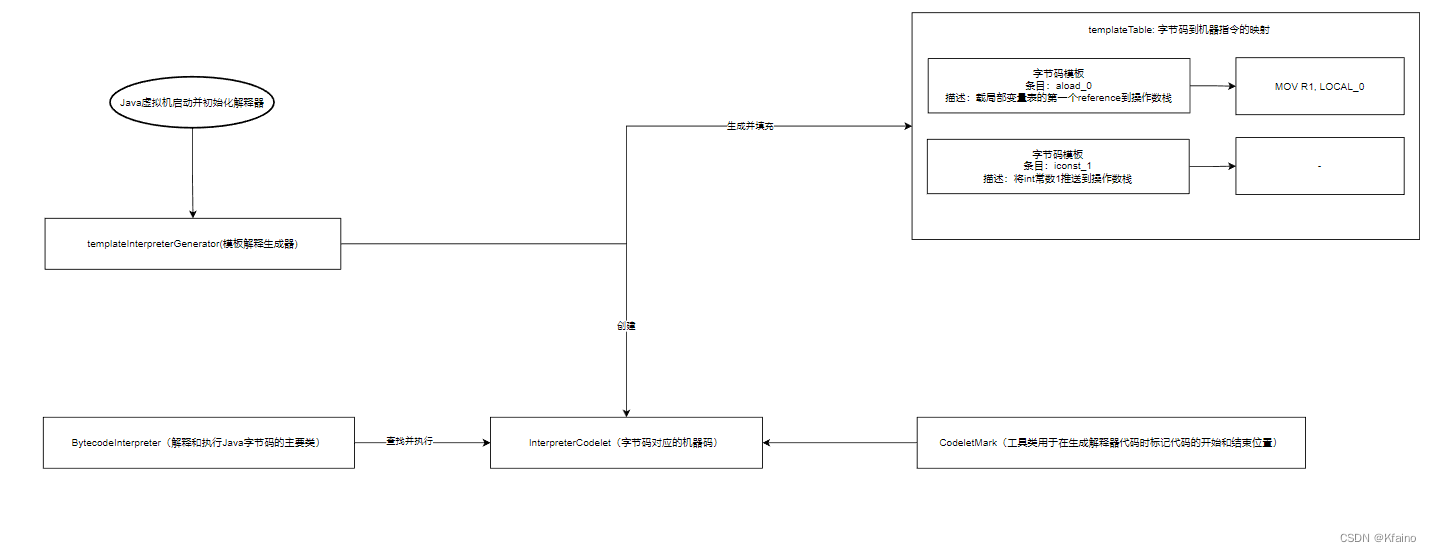
templateInterpreterGenerator
templateInterpreterGenerator是templateTable的生成器,它为每种字节码指令生成对应的机器代码模板。这些模板在JVM启动时只生成一次,并存储在templateTable中,以供BytecodeInterpreter在后续执行时使用。
templateTable
templateTable为字节码指令提供了相应的机器代码模板。这意味着,对于每种字节码,templateTable都有一个预定义的、优化过的机器代码序列,该序列可以直接在物理硬件上执行。非常重要!
总而言之,BytecodeInterpreter 是处理 JVM 字节码逻辑的核心,而 templateTable 提供了对应的机器代码模板,这些模板是由 templateInterpreterGenerator 生成的。
解释器的工作原理
初始化过程:
- 启动阶段:当JVM启动并初始化其核心组件时,
templateInterpreterGenerator也被触发。 - 模板生成:
templateInterpreterGenerator的主要任务是为每个Java字节码生成一个对应的机器代码模板。这些模板定义了如何在特定的硬件和操作系统上执行这些字节码。 - 存储模板:生成的模板随后被存储在
templateTable中,为解释器在运行时使用。
运行时:
- 读取字节码:当Java应用程序运行时,
BytecodeInterpreter开始逐条读取并解释字节码。 - 查找模板:对于每条字节码,
BytecodeInterpreter会查询templateTable以找到对应的机器代码模板。 - 执行机器代码:使用找到的机器代码模板,
BytecodeInterpreter将执行对应的操作,从而实现字节码的功能。
这样,通过在启动阶段预先生成模板,JVM避免了在运行时为每个字节码重新生成机器代码,从而提高了效率。
我画了一张图,你可以看下:
字节码解释器会在哪些情况下会解释字节码?
字节码解释器在Java虚拟机(JVM)中主要是用来执行Java字节码的。当JVM启动时,它默认使用解释器来逐条解释并执行字节码。但在实际的JVM实现中,尤其是像HotSpot这样的高性能JVM,除了解释执行,还会使用JIT编译器来将某些字节码编译成本地机器代码以提高性能。因此,字节码解释器主要在以下几种情况下解释执行字节码:
- 启动初期:当Java程序刚启动时,大多数字节码都会被解释器解释执行。运行一段时间之后,JVM尚未收集到足够的运行时信息来决定哪些代码应当被JIT编译。
- 启动之后还是没成为"热点"的代码:JVM使用分析器来监控程序的执行并识别所谓的“热点”代码,即经常被执行的代码片段。那些不被视为“热点”的代码通常会继续由解释器解释执行。
- "热点"代码的回退:在某些情况下,已经被JIT编译过的代码可能需要回退到解释执行。我给你举一个例子:有一个方法m在类A中,当前它在JIT编译后被直接内联到其他方法中。随后,一个新的类B被加载,它继承自A并覆盖了方法m。现在,每次调用A的子类的m方法可能需要调用B中的版本,而不是A中的版本。由于之前的内联优化是基于错误的假设,JVM需要撤销这一优化,使得方法调用可以正确地进行。
如何将字节码转换为本地机器代码
解释器并不会将字节码持久性地转换为机器代码。相反,它在运行时逐条读取字节码,并根据每条指令执行相应的操作。因此,每次程序运行时,字节码都需要被重新解释。
这与JIT编译器形成了对比,JIT编译器会在运行时将热点代码编译为机器代码,从而提高性能。
解释器知道如何将其转换为一系列的机器指令,我们在上文介绍的 templateTable 里面记录了机器代码模板,这非常重要。
换而言之,执行引擎只有解释器它也可以工作,只是编译器提供了一种优化手段,仅此而已。我们来看下这两种编译上的区别吧~
解释执行与编译执行的区别
-
解释执行:字节码在每次执行时都被解释器逐条解释并执行。这种方式的主要优点是移植性,但代价是性能较低。
-
编译执行:JIT编译器将频繁执行的字节码片段(热点代码)编译为机器代码,并存储起来。当这些代码片段再次被调用时,JVM可以直接执行已编译的机器代码,而无需再次解释字节码,从而大大提高了执行效率。
总结来说,虽然字节码解释器为Java提供了出色的移植性,但从性能的角度看,JIT编译器是更优的选择。然而,在这种情况下:JVM首次启动或当应用只运行一小段时间时,解释执行就派上用场了。
JIT编译器
JIT编译的基本概念
JIT,即“Just-In-Time”编译器,是Java虚拟机的一部分,其主要任务是将热点代码(即频繁执行的代码)从字节码转化为本地机器代码。这种转化过程称为“即时编译”。与传统的“Ahead-Of-Time”编译相反,JIT编译只在运行时进行。
为何需要JIT?
-
性能提升:机器代码通常执行速度比字节码快。当JVM检测到某段字节码被频繁执行(例如,循环中的代码或被频繁调用的方法),JIT编译器将这些字节码编译为机器代码,从而提高执行速度。
-
平台独立性:Java字节码是跨平台的,可以在任何支持Java的平台上执行。JIT编译器允许这些字节码在特定的硬件和操作系统上转化为高效的机器代码。
-
动态优化:由于JIT编译在运行时发生,编译器可以利用运行时的信息进行更有效的优化,如内联缓存、逃逸分析等。
如何确定代码的“热点”
OpenJDK中的JIT编译器使用内部的分析器(Profiler)来跟踪代码的执行频率。“热点”代码的晋升主要通过两个指标:方法调用次数和循环的回边次数。接下来,我们通过源码角度来分析以下。
源码分析
要找到方法调用次数和循环的回边次数,我们定位到methodData.hpp头文件,代码如下:
// How many invocations has this MDO seen?
// These counters are used to determine the exact age of MDO.
// We need those because in tiered a method can be concurrently executed at different levels.
// MDO就是MethodDataObject
InvocationCounter _invocation_counter;
// Same for backedges.
InvocationCounter _backedge_counter;
在templateInterpreterGenerator.hpp可以看到计数器增加的方法:
void generate_counter_incr(Label* overflow);
在这两个值溢出的情况下,设置状态位:
// 处理回边计数器的溢出情况
void CompilationPolicy::handle_counter_overflow(const methodHandle& method) {
MethodCounters *mcs = method->method_counters();
if (mcs != nullptr) {
mcs->invocation_counter()->set_carry_on_overflow();
mcs->backedge_counter()->set_carry_on_overflow();
}
MethodData* mdo = method->method_data();
if (mdo != nullptr) {
mdo->invocation_counter()->set_carry_on_overflow();
mdo->backedge_counter()->set_carry_on_overflow();
}
}
根据状态位决定是否使用JIT编译器。
基于性能的优化策略
JIT编译器使用多种优化策略来提高生成的机器代码的性能:
- 方法内联:这是将一个方法的内容直接插入到另一个方法中,从而避免方法调用的开销。例如,小方法和getter/setter通常会被内联。
- 循环展开:为了减少循环控制的开销,编译器可能会选择展开循环。
- 死代码消除:删除不会被执行的代码,从而减少代码量和提高执行效率。
- 常量传播:编译器试图将程序中的常量值传播到尽可能多的位置,从而使其它优化如死代码消除成为可能。
实战:识别与优化热点代码
实例背景:我们将实现一个简单的数字排序程序,使用插入排序算法。首先,我们将提供一个未优化的版本,然后观察其性能。接着,我们会对其进行优化,以体现如何使代码变成热点并提高效率。
1. 初始版本:
public class InsertionSort {
public static void sort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
public static void main(String[] args) {
int[] data = new int[10000];
for (int i = 0; i < data.length; i++) {
data[i] = (int)(Math.random() * 10000);
}
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
sort(data.clone());
}
long endTime = System.currentTimeMillis();
System.out.println("Duration: " + (endTime - startTime) + "ms");
}
}
当我们多次运行上述代码,sort方法会被频繁调用,并且内部的while循环也会被大量执行,这使得它们很可能被JIT识别为热点代码。
2. 优化:
为了提高效率,我们可以考虑以下几点:
- 使用JVM参数查看JIT编译的方法:
-XX:+PrintCompilation。这样,我们可以知道哪些方法被JIT编译。 - 使用其他排序算法,如快速排序或归并排序,来优化我们的排序方法。
- 预热JVM:在实际排序前,我们可以先进行几次预排序来使JIT编译器尽快识别并优化热点代码。
结论:
JVM会根据代码的运行情况动态地决定何时进行JIT编译。频繁执行的代码块更有可能被识别为热点代码,并被JIT编译成本地机器代码,从而提高程序的运行速度。通过观察和调整代码的执行方式,我们可以有效地促使JVM进行更多的即时编译,进一步提高代码的执行效率。
实战:对比被JIT编译的热点代码与非热点代码的性能
实例背景:我们将实现一个简单的程序,该程序计算从1到一个大数字(如10,000,000)的累加和。首先,我们将编写两个版本的累加函数:一个是循环版本,另一个是递归版本。循环版本很可能被JIT识别为热点代码并进行优化,而递归版本则可能不会。
1. 循环版本:
public static long sumUsingLoop(long n) {
long sum = 0;
for (long i = 1; i <= n; i++) {
sum += i;
}
return sum;
}
2. 递归版本:
public static long sumUsingRecursion(long n) {
if (n <= 1) {
return n;
}
return n + sumUsingRecursion(n - 1);
}
测试性能:
public static void main(String[] args) {
long n = 10000; // 小点的数字用于递归,以免栈溢出
long startTime = System.currentTimeMillis();
sumUsingLoop(10000000); // 更大的数字用于循环版本
long endTime = System.currentTimeMillis();
System.out.println("Loop Duration: " + (endTime - startTime) + "ms");
startTime = System.currentTimeMillis();
sumUsingRecursion(n); // 小数字用于递归
endTime = System.currentTimeMillis();
System.out.println("Recursion Duration: " + (endTime - startTime) + "ms");
}
结论:
循环版本由于被频繁执行,JIT编译器将其识别为热点代码并进行即时编译。因此,即使处理的数字比递归版本大得多,它仍然运行得更快。而递归版本由于函数调用栈的开销,以及它不太可能被JIT编译优化(尤其是深度很大的递归),其性能会较差。
分层编译
当我们谈论JVM的JIT编译时,经常听到"C1"和"C2"这两个术语。这两者实际上是Java HotSpot VM的两种不同的JIT编译器。在JVM启动时,它们两者都会被启动。那么,为什么需要两种JIT编译器呢?
为何需要分层编译
-
快速启动与最大化性能:
- C1(客户端编译器):这是一个更快的编译器,它可以很快地为应用生成最初的代码,帮助应用更快地启动。但是,它执行的优化是有限的。
- C2(服务端编译器):它执行更深入的优化,生成的代码执行速度更快,但编译时间较长。
-
渐进式的优化:
当一个方法首次被执行时,它被C1编译器编译,并进行一些基本的优化。如果这个方法被频繁执行(即成为热点),C2编译器会重新编译它,执行更深入的优化。
不同的编译层次
- 层次0:解释执行。这是当方法首次被调用时的默认层次。在这个阶段,没有任何JIT编译发生,只是简单的解释执行字节码。
- 层次1:简单的C1 JIT编译。当方法被执行了足够多的次数后,它会被C1编译器编译,带有轻量级的优化。
- 层次2和3:这两个层次都是C1编译,但是采用了更多的优化技术。
- 层次4:这是C2编译器的层次,带有所有的高级优化。
如何选择编译级别
JVM会根据方法的执行频率和方法的热度来决定何时以及如何进行编译。例如,当方法被执行了一定次数后,它可能首先被C1编译器编译(层次1)。随着它的执行次数继续增加,它可能会被升级到层次2或3。最后,如果它是一个真正的热点方法,它会被C2编译器编译(层次4)。
总结
分层编译是Java HotSpot VM为了在启动性能和长时间运行性能之间取得平衡而采用的策略。通过使用两个不同的JIT编译器,它确保了应用程序在启动时能够快速响应,并且在长时间运行时能够获得最大的性能。
垃圾收集与执行引擎
Java的自动内存管理,也就是垃圾收集(Garbage Collection, GC),是Java编程语言的核心特性之一。垃圾收集器负责自动检测并回收那些不再被程序引用的对象,从而防止内存泄漏。尽管垃圾收集与执行引擎在Java虚拟机内部的组织结构中属于不同的部分,但它们之间存在紧密的关联。
垃圾收集的基本原理
- 引用计数:这是最简单的垃圾收集方法。每当一个对象的引用数增加或减少时,计数器都会相应地增加或减少。当引用数达到零时,对象被认为是垃圾,并被立即回收。但是,此方法存在循环引用的问题。
- 可达性分析:这是Java使用的主要方法。它从一组基础对象(如栈中的对象)开始,跟踪它们的引用链。未被跟踪到的对象被认为是垃圾。
如何与执行引擎交互
- 安全点:为了进行垃圾收集,JVM需要确保没有线程正在修改堆中的内容。为此,它会使所有的线程在所谓的"安全点"上暂停。安全点通常位于字节码指令的边界。
- 卡表与写屏障:为了跟踪哪些对象已被修改,JVM使用了写屏障和卡表。当一个应用线程修改一个对象引用时,写屏障会被触发,并将相关的信息记录在卡表中。这些信息后来被用于增量垃圾收集。
垃圾收集器的选择对性能的影响
Java提供了多种垃圾收集器,每个都有其特定的用途和优点:
- 串行收集器:简单、高效,但会暂停所有的应用线程。
- 并行收集器:使用多线程来加速垃圾收集,适用于多核处理器。
- CMS(并发标记-清除)收集器:减少暂停时间,但可能导致更多的CPU使用。
- G1收集器:面向延迟,旨在提供高性能和可预测的暂停时间。
选择合适的垃圾收集器对于性能至关重要。例如,低延迟应用可能更喜欢使用G1或CMS,而需要最大吞吐量的应用可能选择并行收集器。
总结
垃圾收集是Java虚拟机的核心组成部分,它确保了内存的有效利用并防止了内存泄漏。尽管它与执行引擎是独立的,但两者之间的交互确保了Java程序的平稳运行。正确地理解和配置垃圾收集器可以大大提高应用的性能和响应时间。
执行引擎的优化技术
在了解了执行引擎的基本组成和工作方式后,本章将深入探讨执行引擎的一些关键优化技术。这些优化技术旨在确保Java代码运行得更快、更稳定。我们将探索以下几个主题:
逃逸分析
- 定义: 逃逸分析是一种确定对象是否可以被线程之外的代码访问的技术。
- 优化的机会:
- 栈上分配: 如果对象在方法内部创建并且不逃逸到方法之外,那么这个对象可能会被分配在栈上而不是堆上。
- 锁消除: 如果JVM确定某个对象只能被单个线程访问,那么关于这个对象的同步操作可以被消除。
内联缓存
- 定义: 内联缓存是一种优化动态分派调用的技术。
- 如何工作: 当方法被调用时,JVM会记住最后一次调用该方法的对象的类型。如果下一次调用该方法的对象是相同的类型,那么JVM可以直接使用缓存的信息,从而避免查找方法的开销。
- 单态内联缓存 vs. 多态内联缓存: 当缓存只存储一个类型时,称为单态内联缓存;当缓存支持多个类型时,称为多态内联缓存。
想象你有一个习惯,那就是每天上班前去同一家咖啡店买咖啡。店员很快就认识了你,也知道你每天都点同样的咖啡。所以,当你走进咖啡店时,店员已经开始为你准备你喜欢的咖啡。这样,你几乎不用等待,就能迅速拿到咖啡并离开。
这就是一个现实生活中的**“内联缓存”。店员(JVM)“缓存”**了你的选择(对象的类型和它的方法),以便在下次你访问时更快地为你服务。但是,如果某一天你改变了主意,想要点别的咖啡,店员就需要重新调整,准备新的咖啡给你。同样的,如果JVM遇到一个新的对象类型调用同一个方法,它也需要“清除”缓存并重新“学习”这个新的类型。
如果你继续改变你的咖啡选择,店员可能会决定不再提前为你准备咖啡,而是等你告诉他们你的选择后再开始。这类似于JVM的“多态内联缓存”,当多个对象类型都调用同一个方法时,JVM会跟踪这些类型,并在运行时决定应该调用哪个版本的方法。
动态链接与优化
- 动态链接: 是指在运行时解析方法、字段和类引用的过程。
- 动态优化: JVM可以根据程序的实际运行情况进行优化,例如,对于经常执行的代码路径,JVM可以应用更高级的优化。
实际应用
在理解了执行引擎的内部工作原理和结构之后,我们可以更好地知道如何在实际应用中利用这些知识。这一章节将探讨如何监控、诊断和优化JVM的执行性能。
如何监控和诊断JVM的执行性能
- 使用JVM内置工具:
jstat: 用于监视JVM的统计信息。jmap: 提供堆转储、类统计信息等。jstack: 用于打印线程堆栈跟踪。jconsole: 图形化的监控工具,提供了关于内存使用、线程活动和JIT编译的信息。
- 开启JIT诊断:可以使用
-XX:+PrintCompilation标志开启JIT编译日志,这会显示哪些方法被JIT编译。 - 使用专业的监控工具:如VisualVM、Arthas等,这些工具提供了更高级的监控、分析和故障排查功能。
JIT编译器的优势及其使用建议
- 热点代码优化:JIT专门优化执行频率高的“热点”代码。了解其工作机制可以指导我们更有针对性地编写高效代码。
- 控制方法大小:过大的方法可能不会被JIT优化。为了获得最佳性能,应该考虑将长方法拆分成更小的、功能明确的子方法。
- JIT编译开关:在特定场景或系统中(如实时应用),可能需要关闭JIT优化。使用
-Djava.compiler=NONE参数可以禁止JIT编译。 - 深入了解内联:JIT通过方法内联来提高执行效率。理解这一机制能帮助我们更好地组织和编写代码,从而充分利用JIT的优势。
文中重要部分解析
安全点 (Safepoint)
在Java虚拟机执行过程中,为了某些操作(如垃圾收集)能够安全地进行,有时需要确保不会发生某些系统级的更改。例如,为了进行垃圾收集,需要确保没有线程正在或可能访问或修改堆内存中的对象。为了实现这个目的,JVM定义了所谓的“安全点”概念。
什么是安全点?
简而言之,安全点是那些线程暂停执行原有字节码的地方,转而执行一些特殊操作,例如垃圾收集,然后再恢复到原来的执行点。
为什么选择字节码指令的边界作为安全点?
字节码指令的边界是JVM中预定义的点,JVM知道在这些点上,线程不会执行任何会更改堆内存内容的操作。因此,这些点被视为“安全的”,可以进行垃圾收集或其他需要整个JVM暂停的操作。
不是每一条字节码指令后面都是一个安全点。事实上,安全点的位置是由JVM的实现和其设置决定的。但为什么大部分安全点位于字节码指令的边界,而不是在指令的中间或其他地方?
答案在于效率和简单性。如果JVM试图在字节码指令的中间插入一个安全点,这将使得JVM的实现更为复杂,并可能导致性能问题。相反,在指令的边界上设置安全点更为简单,易于管理,且效率更高。
实际影响
当JVM达到一个安全点时,所有正在执行的线程都会暂停。这种暂停可能会导致微小的性能开销,但它对于系统的整体健康和稳定性是必要的。
在实际应用中,开发者通常不需要关心安全点的位置或其存在。然而,对于那些关心JVM性能和内部工作机制的开发者来说,了解这些机制可以帮助他们更好地理解JVM的行为,以及为什么某些操作(如垃圾收集)需要所有线程暂停。
源码分析
-
Safepoint类: 这是OpenJDK中与安全点相关的核心类。你可以在src/hotspot/share/runtime/safepoint.hpp和.cpp中找到它。该类包含了许多与安全点同步相关的函数。 -
SafepointMechanism类: 在src/hotspot/share/runtime/safepointMechanism.hpp和.cpp中,这个类处理安全点的具体机制,例如检查线程是否应该在安全点上暂停。 -
安全点检查:在OpenJDK中,为了执行某些系统范围的操作(例如全局的垃圾收集),可能需要暂停所有Java线程。这些暂停发生在称为"safepoints"的特定代码位置。在
CompileBroker.cpp中,有一个set_should_block()方法:
void CompileBroker::set_should_block() {
assert(Threads_lock->owner() == Thread::current(), "must have threads lock");
assert(SafepointSynchronize::is_at_safepoint(), "must be at a safepoint already");
#ifndef PRODUCT
if (PrintCompilation && (Verbose || WizardMode))
tty->print_cr("notifying compiler thread pool to block");
#endif
_should_block = true;
}
此方法会设置一个标志_should_block = true;,指示编译线程池或者线程应当被阻塞,不允许继续它的活动。一般是因为系统已经处于或正要进入一个安全点,并且希望确保在此期间不会有新的编译活动。
- 编译代码: 当使用JIT编译时,生成的机器代码也会在某些位置插入检查点,以便在必要时暂停执行并达到安全点。
- 线程状态: 在OpenJDK中,每个线程都有一个状态,该状态决定了线程是否可以立即到达安全点。例如,处于
BLOCKED或WAITING状态的线程已经被视为在安全点上,而正在执行Java代码的线程需要到达下一个字节码边界才能达到安全点。
总结
经过前面的深入探讨,我们已经对Java执行引擎有了全面的了解。从其基本结构到其工作原理,再到其在实际应用中的表现,Java执行引擎是Java虚拟机中的核心组件之一。
回到我们一开始的讨论,Java虚拟机的元空间确实既存放了元数据也保存了字节码,这些都是为了更好地服务于执行引擎和JIT编译优化。知道这一点,我们更能理解JVM设计背后的深层次原因。
参考文献
- 《深入解析java虚拟机hotspot》
- 《揭秘Java虚拟机-JVM设计原理与实现》
- 《深入理解Java虚拟机:JVM高级特性与最佳实践》