排序
- 一、提出任务
- 二、完成任务
- (一)准备数据
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、创建学生实体类
- 2、创建学生映射器类
- 3、创建学生归并器类
- 4、创建学生驱动器类
- 5、启动学生驱动器类,查看结果
一、提出任务
学生表,包含五个字段(姓名、性别、年龄、手机、专业),有8条记录

- 使用MR,学生信息按年龄降序排列结果

二、完成任务
(一)准备数据
- 启动hadoop服务
1、在虚拟机上创建文本文件
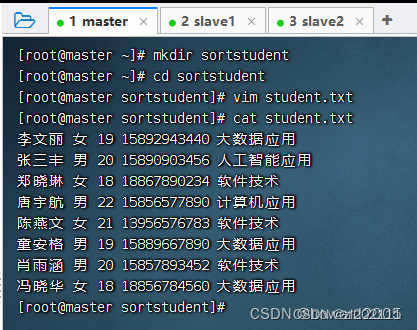
- 创建
sortstudent目录,在里面创建student.txt文件
2、上传文件到HDFS指定目录
-
创建
/sortstudent/input目录,执行命令:hdfs dfs -mkdir -p /sortstudent/input

-
将文本文件
student.txt,上传到HDFS的/sortstudent/input目录

(二)实现步骤
1、创建学生实体类
-
在
net.hw.mr包里创建Student类 -
让学生按照年龄排序,需要让学生实体类实现一个序列化可比较接口 - WritableComparable,这个接口有三个抽象方法要我们去实现。
package net.hw.mr;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 功能:学生实体类
* 实现序列化可比较接口
*/
public class Student implements WritableComparable<Student> {
private String name;
private String gender;
private int age;
private String phone;
private String major;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getMajor() {
return major;
}
public void setMajor(String major) {
this.major = major;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", gender='" + gender + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", major='" + major + '\'' +
'}';
}
public int compareTo(Student o) {
return o.getAge() - this.getAge(); // 降序
}
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeUTF(gender);
out.writeInt(age);
out.writeUTF(phone);
out.writeUTF(major);
}
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
gender = in.readUTF();
age = in.readInt();
phone = in.readUTF();
major = in.readUTF();
}
}
2、创建学生映射器类
- 在
net.hw.mr里创建StudentMapper类
package net.hw.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 功能:学生映射器类
*/
public class StudentMapper extends Mapper<LongWritable, Text, Student, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到字段数组
String[] fields = line.split(" ");
// 获取学生信息
String name = fields[0];
String gender = fields[1];
int age = Integer.parseInt(fields[2]);
String phone = fields[3];
String major = fields[4];
// 创建学生对象
Student student = new Student();
// 设置学生对象属性
student.setName(name);
student.setGender(gender);
student.setAge(age);
student.setPhone(phone);
student.setMajor(major);
// 写入键值对<student,null>
context.write(student, NullWritable.get());
}
}
3、创建学生归并器类
- 在
net.hw.mr包里创建StudentReducer类
package net.hw.mr;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 功能:学生归并器类
*/
public class StudentReducer extends Reducer<Student, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Student key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
// 获取学生对象
Student student = key;
// 拼接学生信息
String studentInfo = student.getName() + "\t"
+ student.getGender() + "\t"
+ student.getAge() + "\t"
+ student.getPhone() + "\t"
+ student.getMajor();
// 写入键值对<studentInfo,null>
context.write(new Text(studentInfo), NullWritable.get());
}
}
4、创建学生驱动器类
- 在
net.hw.mr包里创建StudentDriver类
package net.hw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 功能:学生驱动器类
*/
public class StudentDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(StudentDriver.class);
// 设置Mapper类
job.setMapperClass(StudentMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Student.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(NullWritable.class);
// 设置Reducer类
job.setReducerClass(StudentReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Student.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(NullWritable.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/sortstudent/input");
// 创建输出目录
Path outputPath = new Path(uri + "/sortstudent/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待作业完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
5、启动学生驱动器类,查看结果
-
运行StudentDriver 类

-
学生信息按照年龄降序排列,去重,少了3条记录
-
需要修改学生归并器类,遍历值迭代器,这样就不会去重了

-
再次运行
StudentDriver类