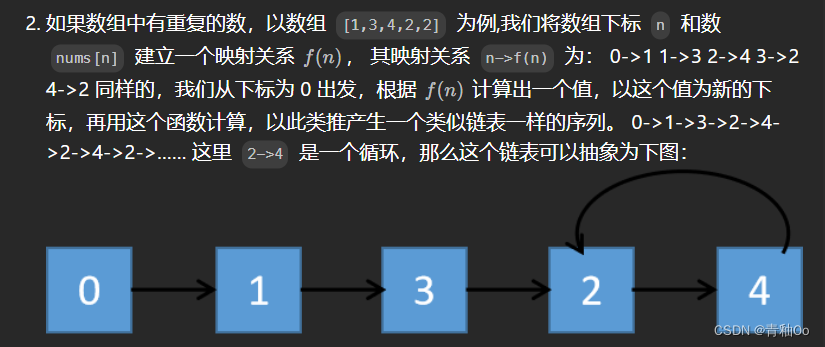
需求说明:
从如下的日志文件里解析出如下字段:
参数名:教育程度
左值:60
右值:90
表达式:等于
结果:不满足
解决方法:
Step1: 因为原始日志来源于网页,这里真正的日志实际是html文件,需要通过BeautifulSoup对文件进行解析。
Step2:解析时遍历每行数据,对含有“[条件日志]”的处理见下:
按照“【”、“】”、“左值”、“右值”提取关键信息,其中对特殊符号可采取正则表达式统一替换。
Step3:对含有“变量赋值日志”'的仅提前出 左值、右值。
import re
r = "[,。,【】]"
#sentence = re.sub(r, ' ', sentence)
def cleanData(str):
#str="[条件日志]:^^^条件:[变量]参数.非广西手机号码归属地_调用状态【小于等于】[字符]300 =>满足, 左值:【200】, 右值:【300】。"
if ('[条件日志]' in str):
#print("表达式:\t",str.split('左值:')[0])
expStr=str.split('左值:')[0].replace('[条件日志]:^^^条件:[变量]参数.','')
para=expStr.split('【')[0]
exp= expStr.split('【')[-1].split('】')[0]
leftVal=str.split('左值:')[-1].split('右值:')[0]
leftVal =re.sub(r, '', leftVal)
rightVal = str.split('右值:')[-1].split('右值:')[0]
rightVal = re.sub(r,'',rightVal)
result = expStr.split("=>")[-1].replace(',','')
print(para,leftVal,exp,rightVal,result)
elif('变量赋值日志' in str):
expStr = str.replace('[变量赋值日志]:###变量赋值:参数.', '')
leftVal = expStr.split('=')[0]
rightVal = expStr.split('=')[-1]
print("\t",leftVal, rightVal)
elif('进入决策节点' in str):
print(str.replace('[RuleFlow]:>>>进入决策节点, ',''))
from bs4 import BeautifulSoup
#1将字符串中,字母i单独出现的地方将i变为I
s='i am is wang i love I love you i!'
patter=re.compile(r'^.*日志:') #[RuleFlow.*$]
with open("D:/log.html", "r", encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'html.parser')
table = soup.find('table')
rows = table.find_all('tr')
for row in rows:
cells = row.find_all('td')
for cell in cells:
cleanData(re.sub(patter, '', cell.text))![]()