文章目录
- golang的特点
- golang数据类型
- 基本数据类型(值类型)
- 引用数据类型
- make和new
- make
- new
- 浅拷贝,深拷贝
- 深拷贝:
- 实现深拷贝的方式:
- 浅拷贝:
- 实现浅拷贝的方式
- 接口
- 接口是什么
- 某种类型可以比较吗
- channel
- 数据结构
- 环形队列:
- 等待队列
- channel读写过程
- 创建channel
- 向一个channel中写数据过程如下:
- 从一个channel读数据过程如下:
- 关闭channel会发生什么
- channel缓冲区的特点
- 同步与非同步:
- nil:
- panic:
- 切片
- 数据结构
- Slice的扩容
- append操作实现扩容的过程
- map
- 数据类型是否线程安全
- GMP调度
- 垃圾回收机制
golang的特点
Golang 针对并发进行了优化,并且在规模上运行良好
自动垃圾收集明显比 Java 或 Python 更有效,因为它与程序同时执行
golang数据类型
基本数据类型(值类型)
-
布尔类型
-
数字类型
-
整型
根据有符号分为:有符号、无符号类型;
根据占据的空间分为:8,16,32,64;
-
浮点型
float32:32位浮点型数;float64:64位浮点型数;
complex64:32位实数和虚数;complex128:64位实数和虚数;
-
其他
byte:类似于uint8,代表了 ASCII 码的一个字符
rune:类似于int32,表示的是一个 Unicode字符
uint:与uint大小一样
uintptr:无符号整型,用于存放一个指针
-
-
字符串类型
-
数组类型
-
结构体类型
引用数据类型
-
指针类型
-
Channel类型
-
切片类型
-
Map类型
-
函数类型
-
接口类型
make和new
他们都是分配内存空间的内置函数
make
-
make用于创建切片、映射和通道(slice、map、channel)等引用类型的数据结构。 -
它返回一个已初始化并且可以使用的引用类型变量,通常用于创建动态大小的数据结构。
new
-
new主要用于创建值类型的变量,如结构体、整数、浮点数等,而不是引用类型。 -
new用于创建并返回一个指向新分配的零值的指针。
浅拷贝,深拷贝
深拷贝:
拷贝的是数据本身,创造一个新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值
实现深拷贝的方式:
-
值类型:对于 Go 中的基本数据类型(如整数、浮点数、字符串、结构体,数组等),赋值或传递参数时会进行深拷贝。这意味着创建一个新的值,而不是共享数据。
a := 10 b := a // 深拷贝 arr1 := [3]int{1, 2, 3} arr2 := arr1 // 深拷贝 -
使用
copy赋值的数据是深拷贝slice1 := []int{1, 2, 3} slice2 := []int{0, 0, 0} copy(slice2, slice1) slice2[0] = 10 fmt.Printf("slice1:%v\n", slice1) //slice1:[1 2 3] fmt.Printf("slice2:%v\n", slice2) //slice2:[10 2 3]
浅拷贝:
拷贝的是数据地址,只复制指向的对 象的指针,此时新对象和老对象指向的内存地址是一样的,新对象值修改时老对象也会变化
实现浅拷贝的方式
-
引用数据类型默认赋值操作就是浅拷贝:slice2 := slice1
arr1 := []int{1, 2, 3} arr2 := arr1 // 浅拷贝 arr2[0] = 100 fmt.Printf("slice1:%v\n", arr1) //slice1:[100 2 3] fmt.Printf("slice2:%v\n", arr2) //slice2:[100 2 3]
接口
接口是什么
-
interface 是方法声明的集合
-
任何类型的对象实现了在interface 中声明的全部方法,则表明该类型实现了该接口
-
interface可以作为一种数据类型,实现了该接口的任何对象都可以给对应的接口类型变量赋值
举实例,
某种类型可以比较吗
可以比较的数据结构:
- 基本数据类型:整数(int、int8、int16、int32、int64)、浮点数(float32、float64)、复数(complex64、complex128)、布尔值(bool)、字符串(string)等基本类型都可以进行比较。
- 数组:数组是值类型,如果数组的元素类型是可比较的,则整个数组可以进行比较。例如,[3]int 和 [3]int 可以进行比较。
- 结构体:结构体是用户自定义的复合数据类型,如果结构体的字段都是可比较的,则结构体可以进行比较。
- 指针:指针类型可以进行比较,但比较的是指针的地址值。
- 接口:接口类型可以进行比较,但比较的是接口的动态类型和动态值。
不可以比较的数据结构:
- 切片:切片是引用类型,不能直接进行比较。你可以比较切片是否为nil,但不能比较两个切片的内容是否相同。
- 映射:映射也是引用类型,不能直接进行比较。你可以比较映射是否为nil,但不能比较两个映射的内容是否相同。
- 函数:函数类型不能进行比较。
- 通道:通道类型不能进行比较。
channel
channel主要用于进程内各goroutine间的通信
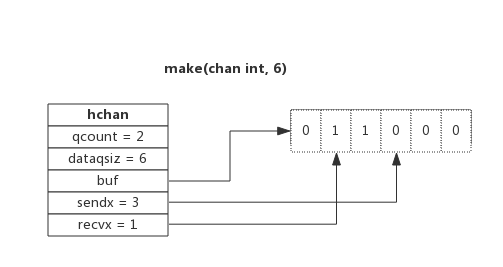
数据结构
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写
}
环形队列:
环形队列作为其缓冲区,队列长度是创建channel时候指定的
等待队列
从channel读数据,如果channel缓冲区为空或者没有缓冲区,当前goroutine会被阻塞。
向channel写数据,如果channel缓冲区已满或者没有缓冲区,当前goroutine会被阻塞。
被阻塞的goroutine将会挂在channel的等待队列中:
- 因读阻塞的goroutine会被向channel写入数据的goroutine唤醒;
- 因写阻塞的goroutine会被从channel读数据的goroutine唤醒;
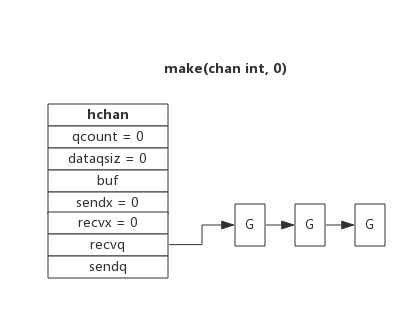
channel读写过程
创建channel
创建channel的过程实际上是初始化hchan结构。其中类型信息和缓冲区长度由make语句传入,buf的大小则与元素大小和缓冲区长度共同决定。
向一个channel中写数据过程如下:
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒;
从一个channel读数据过程如下:
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
- 如果等待发送队列sendq为空,但缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
- 如果等待发送队列sendq为空,并且缓冲区中没有数据,将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
关闭channel会发生什么
- 把recvq中的G全部唤醒,本该写入G的数据位置为nil。
- 把sendq中的G全部唤醒,但这些G会panic。
特点:
- 关闭通道后,已经在通道中的数据仍然可以被读取,直到通道中的数据全部被读取完毕。之后再次去读取,读取操作将不会阻塞,而是立即返回其元素类型的零值
- 关闭通道后,向管道中写数据会发生panic
channel缓冲区的特点
同步与非同步:
无缓冲的 channel 是同步的,有缓冲的 channel 是非同步的,缓冲满时发送阻塞
channel无缓冲时,发送阻塞直到数据被接收,接收阻塞直到读到数据;
channel有缓冲时,当缓冲满时发送阻塞,当缓冲空时接收阻塞。
nil:
如果给一个nil的 channel 发送数据,会造成永远阻塞。
如果从一个nil的 channel 中接收数据,会造成永久阻塞。
panic:
关闭值为nil的channel
关闭已经被关闭的channel
向已经关闭的channel写数据
切片
数据结构
Slice依托数组实现,底层数组对用户屏蔽,在底层数组容量不足时可以实现自动重分配并生成新的Slice。
type slice struct {
array unsafe.Pointer //array指向底层数组
len int //len代表切片长度
cap int //cap是底层数据的长度
}
Slice的扩容
- 使用append向Slice追加元素时,如果Slice空间不足,将会触发Slice扩容,扩容实际上是重新分配一块更大的内存,将原Slice数据拷贝进新Slice,然后返回新Slice,扩容后再将数据追加进去。
- 扩容操作只关心容量,会把原Slice数据拷贝到新Slice,追加数据由append在扩容结束后完成
append操作实现扩容的过程
- 假如Slice容量够用,则将新元素追加进去,Slice.len++,返回原Slice
- 原Slice容量不够,则将Slice先扩容,扩容后得到新Slice
- 将新元素追加进新Slice,Slice.len++,返回新的Slice。
如果是一次追加一个元素,在容量小于1024之前是每次扩容一倍,如果是一次追加多个元素,在容量小于1024之前是一次扩容到大于切片长度的最小的偶数
a := make([]int, 0, 0)
a = append(a, 1, 1, 1, 1, 1)
fmt.Println(cap(a))
加一个元素之后之后的切片跟原来的一样吗
是否线程安全(否,关于底层结构)
map
的底层,冲突和扩容,为啥无序,线程不安全
数据类型是否线程安全
GMP调度
数量,调度过程:P维护调度(注意专业词汇)(了解G的生命周期)
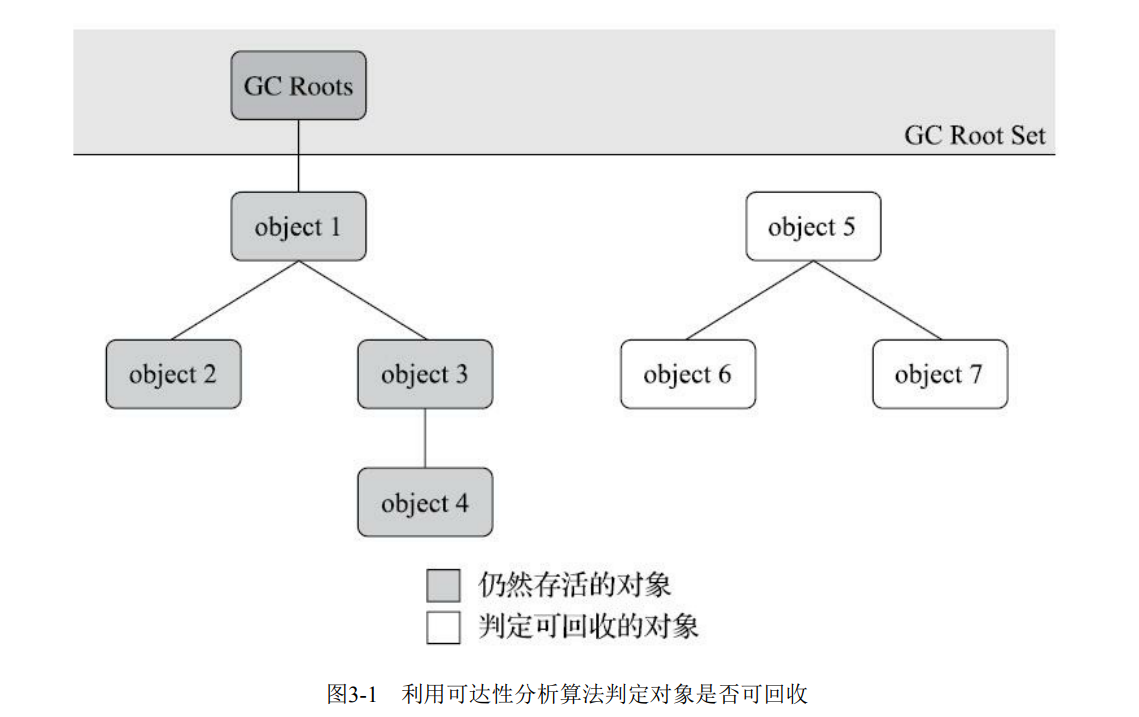
垃圾回收机制
特点:与别的语言的不同之处
流程:整理好语言
垃圾回收:根据板门的发展过程(标记清除法,三色标记法,混合写屏障
)
defer先关闭
defer receiver painc执行顺序
错误处理:
可预测,不可预测,panic(执行过程,里面涉及到receive)
a))
加一个元素之后之后的切片跟原来的一样吗
是否线程安全(否,关于底层结构)
### map
的底层,冲突和扩容,为啥无序,线程不安全
### 数据类型是否线程安全
### GMP调度
数量,调度过程:P维护调度(注意专业词汇)(了解G的生命周期)
### 垃圾回收机制
特点:与别的语言的不同之处
流程:整理好语言
垃圾回收:根据板门的发展过程(标记清除法,三色标记法,混合写屏障
)
defer先关闭
defer receiver painc执行顺序
错误处理:
可预测,不可预测,panic(执行过程,里面涉及到receive)