什么是ConcurrentHashMap?
ConcurrentHashMap 和HashMap一样,是一个存放键值对的容器。使用Hash算法来获取值的地址,因此时间复杂度是O(1)。查询非常快。ConcurrentHashMap 同时也是线程安全版的HashMap,可以实现线程安全的集合的并发操作,它在不同的JDK 版本中有不同的数据结构。
JDK7
ConcurrentHashMap 采用的是分段锁(Segment) 机制,底层采用 数组 + 链表的存储结构,即 Segment 数组 + HashEntry 数组。结构图如下:

Segment 数组一共由 16 个 Segment 组成,每个Segment 是由若干个 HashEntry 对象链接起来的链表,HashEntry 是用来封装映射表的键值对。每个 Segment 是一个可重入锁,并发操作时,只锁住对应的 Segment,而不是整个 Segment 数组,从而提升了并发性能。
JDK8
然后在JDK 8 中,ConcurrentHashMap 又进行了优化,取消了 Segment 分段锁机制,和HashMap 一样,两者均为 数组 +链表+红黑树的数据结构,运用 CAS + synchronized 机制来保证线程安全,结构图如下:

put()方法:
public V put(K key, V value) {
return putVal(key, value, false);
} /** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
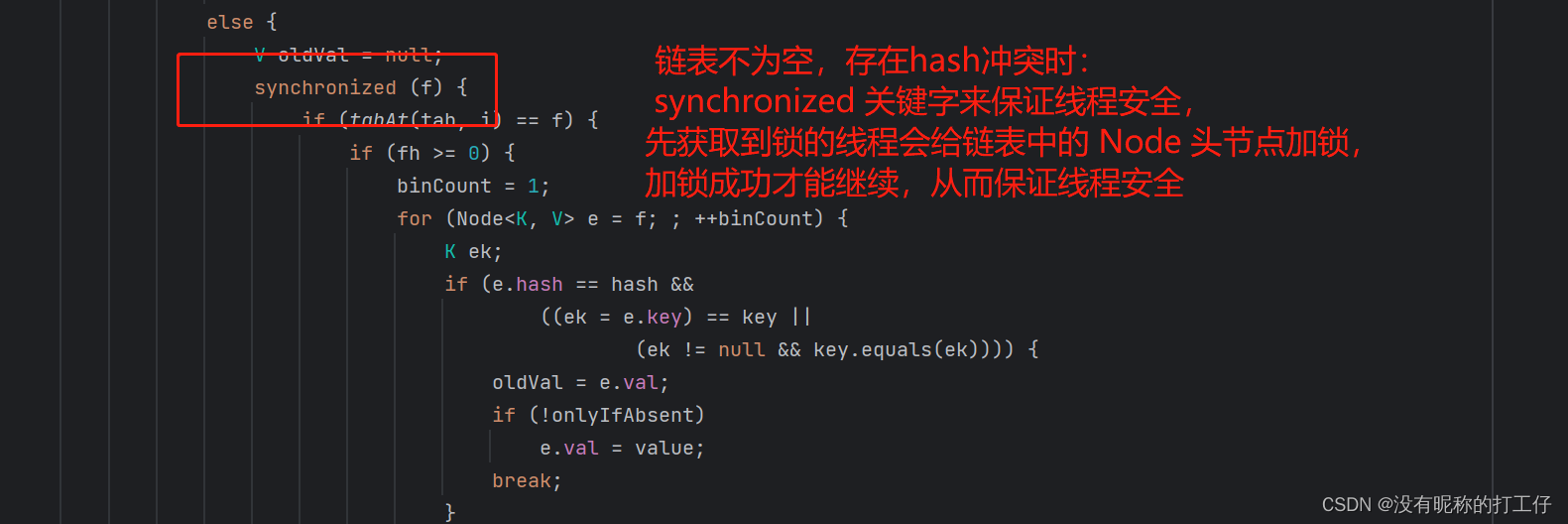
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}步骤详解: