文章目录
- 前言
- 文献阅读一
- 摘要
- 挑战
- 基于时间序列的 GAN 分类
- 文献阅读二
- 摘要
- 介绍
- 提出的模型:时间序列GAN (TimeGAN)
- 代码学习
- 总结
前言
本周阅读两篇文献,文献一是一篇时序生成方面的综述,主要了解基于时间序列 的GAN主要分类以及时间序列GAN方面面临的一些问题。文献二是Time-series Generative Adversarial Networks(TimeGAN),了解TimeGAN的原理以及网络的四个组成部分。最后,GAN基础代码的学习。
文献阅读一
题目:Generative Adversarial Networks in Time Series: A Systematic Literature Review
期刊名:ACM Computing Surveys
摘要
生成对抗网络(GAN)研究在过去几年中呈指数级增长。它们的影响主要体现在计算机视觉领域,具有逼真的图像和视频处理,尤其是生成,取得了重大进展。尽管这些计算机视觉的进步引起了很多关注,但GAN应用已经跨越了时间序列和序列生成等学科。作为 GAN 的一个相对较新的利基市场,实地工作正在进行中,以开发高质量、多样化和私有的时间序列数据。在本文中,我们将回顾为时间序列相关应用设计的GAN变体。我们提出了离散变体GAN和连续变体GAN的分类,其中GAN处理离散时间序列和连续时间序列数据。在这里,我们展示了该领域最新和最流行的文献——它们的架构、结果和应用。我们还提供了最流行的评估指标列表及其在应用程序中的适用性。还讨论了这些 GAN 的隐私措施以及处理敏感数据的进一步保护和方向。我们的目标是清晰简洁地构建该领域的最新和最先进的研究及其在现实世界技术中的应用。
挑战
时间序列 GAN 领域存在三个主要挑战:与 GAN 创建的合成数据相关的训练稳定性、评估和隐私风险。
1.训练稳定性。最初的GAN工作已经证明了GAN在训练过程中的全局最优性和收敛性[38]。但是,它仍然突出了训练GAN时可能出现的不稳定性问题。文献中对两个问题进行了很好的研究:梯度消失和模态坍缩。
2.评价。已经提出了广泛的评估指标来评估GAN的性能[9,10,98,99]。 目前对计算机视觉中GAN的评估通常旨在考虑两个角度:生成数据的质量和数量。最具代表性的定性指标是使用人工注释来确定生成图像的视觉质量。定量指标比较生成图像和真实图像之间的统计属性:双样本测试,例如最大平均差异(MMD)[93],初始分数(IS)[88]和Fréchet初始距离(FID)[51]。与评估基于图像的GAN相反,很难从人类心理知觉中定性评估时间序列数据。在定性评估基于时间序列的GAN方面,它通常进行t-SNE [95]和PCA [13]分析,以可视化生成的分布与原始分布的相似程度[107]。基于时间序列的 GAN 的定量评估可以通过部署类似于基于图像的 GAN 的双样本测试来完成。
GAN的缺点:
具有不稳定性,GAN模型存在非收敛性,梯度减小/消失和模式崩溃等问题。非收敛模型不会稳定并持续振荡,从而导致其发散。梯度递减会阻止生成器学习任何东西,因为鉴别器变得太成功了。模式崩溃是指发生器坍缩,仅产生均匀的样本,几乎没有变化。
GAN的第二个挑战在于其评估过程。对于时间序列GANs,由于发表的论文数量相对较少,尚未就生成的数据的评估指标达成一致。已经提出了不同的方法,但到目前为止还没有一种方法成为指标领域的领跑者。
基于时间序列的 GAN 分类
分为离散变体和连续变体,这里主要摘录连续变体。
1.连续RNN-GAN(C-RNN-GAN)(2016年)
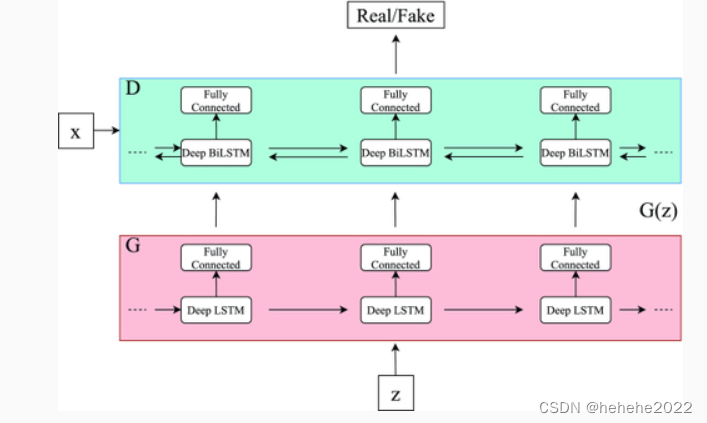
在以前的工作中,RNN已被应用于音乐建模,但通常使用符号表示来建模这种类型的顺序数据。Mogren提出了C-RNN-GAN,这是使用GAN生成连续顺序数据的首批示例之一。生成器是RNN,鉴别器是双向RNN,它允许鉴别器在两个方向上获取序列上下文。
2.降噪甘(NR-GAN)(2019年)
NR-GAN设计用于连续时间序列信号中的降噪,但更具体地说,已用于小鼠脑电图(EEG)信号中的降噪[90]。该数据集由国际综合睡眠医学研究所(IIIS)提供。脑电图是大脑电活动的量度,通常包含明显的噪声伪影。NR-GAN的核心思想是减少或消除EEG信号频域表示中存在的噪声。G 的架构是一个两层 1D CNN,输出端有一个全连接层。D 包含几乎相同的两层 1D CNN 结构,全连接层替换为 softmax 层,以计算输入属于训练集的概率。
3.时间甘(2019年)
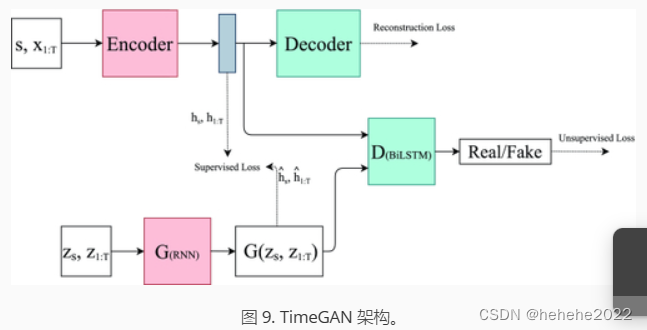
TimeGAN提供了一个框架,该框架利用了传统的无监督GAN训练方法和更可控的监督学习方法[107]。通过将无监督GAN网络与监督AR模型相结合,该网络旨在生成具有保留时间动态的时间序列。TimeGAN 框架的体系结构如图 9 所示。框架的输入被认为由两个元素组成:静态特征和时态特征。s 表示编码器输入处静态特征的向量和时态特征的 x 。生成器采用从已知分布中提取的静态和时间随机特征向量的元组。真实和合成的潜在代码h和h^用于计算该网络的监督损失元素。鉴别器接收实数和合成潜在码的元组,并将它们分类为实数 (y) 或合成 (y^)。
文献阅读二
题目:Time-series Generative Adversarial Networks
TimeGAN原论文
摘要
一个好的时间序列数据生成模型应该保持时间动态,在这个意义上,新的序列尊重变量之间的原始关系。将生成对抗网络(gan)引入序列设置的现有方法不能充分考虑时间序列数据特有的时间相关性。(也就是GAN没有很好的考虑时间序列数据的时间相关性,在时序数据的处理上不好)与此同时,用于序列预测的监督模型(允许对网络动态进行更精细的控制)本质上是确定性的。我们提出了一种新的框架来生成真实的时间序列数据,该框架结合了无监督范式的灵活性和监督训练提供的控制。通过一个由监督目标和对抗目标共同优化的学习嵌入空间,我们鼓励网络在采样过程中坚持训练数据的动态。在经验上,我们使用各种真实和合成的时间序列数据集来评估我们的方法生成真实样本的能力。在定性和定量方面,我们发现所提出的框架在相似性和预测能力方面始终显著优于最先进的基准。
介绍
在时间序列数据生成方面,一方面,大量的工作集中在改进序列预测的自回归模型的时间动态。这些主要解决了多步采样过程中的复合误差问题,引入了各种训练时间修改,以更准确地反映测试时间条件。然而,虽然在预测的背景下有用,但这种方法基本上是确定性的,并不是真正的生成,因为新序列可以在没有外部条件的情况下从中随机采样。另一方面,一个单独的工作重点是直接将生成对抗网络(GAN)框架应用于序列数据,主要是通过实例化循环网络作为生成器和鉴别器。虽然直接,但对抗性目标寻求直接对p(x1:T)建模,而不利用自回归先验。重要的是,简单地对向量序列的标准GAN损失求和可能不足以确保网络的动态有效地捕获训练数据中存在的逐步依赖关系。
在本文中,提出了一种新的机制,将这两个研究线索联系在一起,从而产生一个明确训练以保持时间动态的生成模型。我们提出了时间序列生成对抗网络(TimeGAN),这是一个在各个领域生成真实时间序列数据的自然框架。首先,除了真实序列和合成序列上的无监督对抗损失外,我们引入了一个使用原始数据作为监督的逐步监督损失,从而明确地鼓励模型捕捉数据中的逐步条件分布。这利用了这样一个事实,即训练数据中有更多的信息,而不仅仅是每个数据是真实的还是合成的;我们可以明确地从真实序列的过渡动态中学习。
其次,我们引入了一个嵌入网络来提供特征和潜在表征之间的可逆映射,从而降低了对抗学习空间的高维性。
我们的方法是第一个将无监督GAN框架的灵活性与自回归模型中监督训练提供的控制相结合的方法。我们在多个真实世界和合成数据集的一系列实验中展示了其优势。定性地,我们进行了t-SNE和PCA分析,以可视化生成的分布与原始分布的相似程度。
提出的模型:时间序列GAN (TimeGAN)
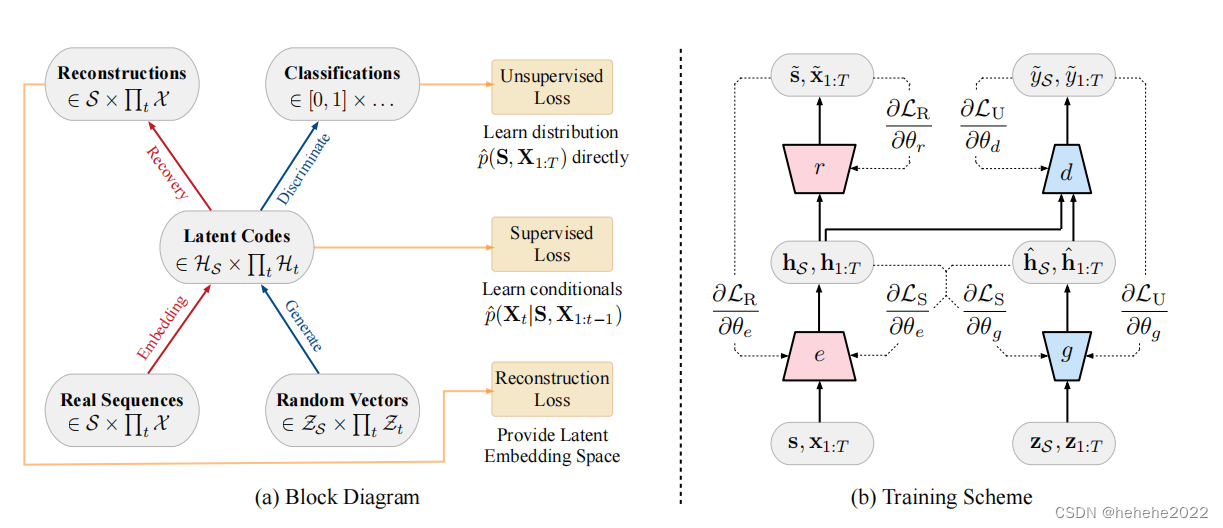
TimeGAN由四个网络组件组成:嵌入函数、恢复函数、序列生成器和序列鉴别器。关键的见解是,自动编码组件(前两个)与对抗组件(后两个)联合训练,这样TimeGAN就可以同时学习编码特征、生成表示和跨时间迭代。嵌入网络提供潜在空间,对抗网络在该空间内运行,真实数据和合成数据的潜在动态通过监督损失同步。
模型图:
文献还在学习当中。
代码学习
1.用MNIST数据集对基础的GAN网络进行学习
鉴别器模型
# 鉴别器模型,判别器的输入是(1,28,28)的图片,输出是二分类的概率值,输出使用sigmoid激活,输出[0,1]
#二分类模型的损失函数是BCELOSS计算交叉熵损失
class Discriminator(nn.Module):
def __init__(self, in_features):
super().__init__()
self.disc = nn.Sequential(
nn.Linear(in_features, 128), # 线性回归函数
nn.LeakyReLU(0.1), #在赋值部分会保留一定的梯度,相比于relu # 激活函数-relu
nn.Linear(128, 1), # 线性回归函数
nn.Sigmoid(), # 激活函数—sigmoid
)
def forward(self, x): #x是28*28的图片,x.view展平
return self.disc(x)
生成器模型
# 生成器模型,生成器的输入输出:设长度为100的噪声(随机数)和生成的图片(28*28)
#linear1:100----256
#linear2:256----512
#linear3:512----28*28
#reshape:28*28----(1,28,28)
class Generator(nn.Module):
def __init__(self, z_dim, img_dim): # z_dim: 将噪声图片拉伸成一维时候的大小
super().__init__()
self.gen = nn.Sequential(
nn.Linear(z_dim, 256),
nn.LeakyReLU(0.1),
nn.Linear(256, img_dim), # 28*28*1---784 # img_dim: 将生成的二维图像拉伸成一维时候的大小
nn.Tanh(), #tanh规范到[-1,1],使用tanh效果好
)
def forward(self, x): #定义前向传播,X是100的噪声输入
return self.gen(x)
#self.gen(x).view(-1,28,28,1) 展开
超参数设置,数据加载,损失函数
# 超参数的设置
device = "cuda" if torch.cuda.is_available() else "cpu"
lr = 3e-4 # 学习率
z_dim = 64 # 128 , 256
image_dim = 28*28*1 # 784
batch_size = 32 # 批量数
num_epochs = 50 # 训练次数
disc = Discriminator(image_dim).to(device) # 初始化鉴别器
gen = Generator(z_dim, image_dim).to(device) # 初始化生成器
fix_noise = torch.randn((batch_size, z_dim)).to(device) # 随机生成的噪声图像,大小为批量数*将噪声图片拉伸成一维时候的大小
#对数据进行归一化[-1,1]
transforms = transforms.Compose(
[transforms.ToTensor(), #0-1:channel,high,witch
#transforms.Normalize((0.1307, ), (0.3081, )),
transforms.Normalize((0.5, ), (0.5, )),#归一化到[-1,1]
]
)
# 下载数据和定义数据流
dataset = datasets.MNIST(root="../data/", transform=transforms, download=True)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 定义优化器类型和需要优化的参数
opt_disc = optim.Adam(disc.parameters(), lr=lr)
opt_gen = optim.Adam(gen.parameters(), lr=lr)
# 损失函数
criterion = nn.BCELoss()
训练代码
# 进行训练
for epoch in range(num_epochs):
for batch_idx, (real, _) in enumerate(loader): # 遍历读取影像数据
real = real.view(-1, 784).to(device) # 将影像拉升成一维的数组形式
batch_size = real.shape[0]
# 训练鉴别器 max(log(D(real)))+log(1-D(G(z)))
noise = torch.randn(batch_size, z_dim).to(device) # 噪声影像
fake = gen(noise) # 将噪声影像放入生成器里面
disc_real = disc(real).view(-1) #判别器输入真实图片,对真实图片的判断 # 将真实影像放入鉴别器中进行处理
lossD_real = criterion(disc_real, torch.ones_like(disc_real)) # 计算鉴别器处理的真实影像和 1 的损失值--- 得log(D(real))
#torch.ones_like(disc_real) 希望得到和disc_real一样的的结果为全1
disc_fake = disc(fake).view(-1) #判别器输入生成图片,对生成图片的预测结果 # 将噪声影像放入鉴别器中进行处理
lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) # 计算鉴别器处理的生成影像和 0 的损失值--— 得log(1-D(G(z)))
lossD = (lossD_real + lossD_fake)/2 # 得到鉴别器的损失值(上面讲解会提到)
disc.zero_grad() # 梯度清零
lossD.backward(retain_graph=True) # 后向传播
opt_disc.step() # 更新参数
# 训练生成器 min(log(1-D(G(z))) ----max (log(D(G(z)))
output = disc(fake).view(-1) # 将生成的fake图像放入鉴别器中
lossG = criterion(output, torch.ones_like(output)) #希望生成器的损失判定为1 # 得到生成器的损失值 ———— 得log(D(G(z))
gen.zero_grad() #梯度归零
lossG.backward()
opt_gen.step()
if batch_idx == 0:
print(
f"Epoch[{epoch}/{num_epochs}] Batch {batch_idx}/{len(loader)} \ "
f"Loss D:{lossD:.4f}, Loss G:{lossG:.4f}"
)
with torch.no_grad(): #累加所有的loss
fake = gen(fix_noise).reshape(-1, 1, 28, 28)
data = real.reshape(-1, 1, 28, 28)
img_grid_fake = torchvision.utils.make_grid(fake, normalize=True)
img_grid_real = torchvision.utils.make_grid(data, normalize=True)
writer_fake.add_image(
"Mnist Fake Images", img_grid_fake, global_step=step
)
writer_real.add_image(
"Mnist Real Images", img_grid_real, global_step=step
)
step += 1
TimeGAN原论文的代码学习
源代码下载下来了,原代码是tensorflow版本的,版本较低,运行会报错,还在修改中。
总结
在阅读TimeGAN论文,对里面的数学表达不是很理解,想结合论文代码加深对论文内容以及TimeGAN框架的理解。
下周主要学习水文模型以及TimeGAN代码,阅读环境+TimeGAN方面的论文。

![[Linux]文件描述符(万字详解)](https://img-blog.csdnimg.cn/img_convert/f2ac4b10b9eb35a05a81968da5a210c2.png)