一、源码安装
安装
请按照以下步骤安装DB-GPT
1. Hardware Requirements

如果你的显存不够,DB-GPT支持8-bit和4-bit量化版本

2. Install
git clone https://github.com/eosphoros-ai/DB-GPT.git
目前使用Sqlite作为默认数据库,因此DB-GPT快速部署不需要部署相关数据库服务。如果你想使用其他数据库,需要先部署相关数据库服务。目前使用Miniconda进行python环境和包依赖管理安装 Miniconda
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
pip install -e .
在使用知识库之前
python -m spacy download zh_core_web_sm
如果你已经安装好了环境需要创建models, 然后到huggingface官网下载模型
cd DB-GPT
mkdir models and cd models
#### llm model
git clone https://huggingface.co/lmsys/vicuna-13b-v1.5
or
git clone https://huggingface.co/THUDM/chatglm2-6b
#### embedding model
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
or
git clone https://huggingface.co/moka-ai/m3e-large
配置.env文件,它需要从。env.template中复制和创建。
如果想使用openai大模型服务, 可以参考LLM Use FAQ
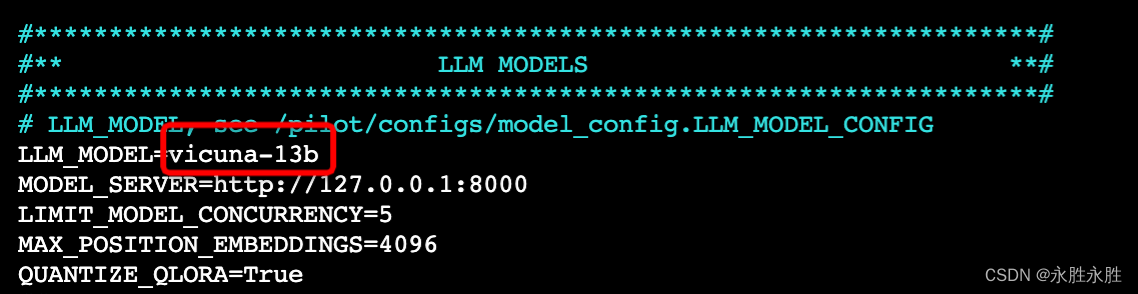
可以在.env文件中配置基本参数,例如将LLM_MODEL设置为要使用的模型。
可以在.env文件中配置基本参数,例如将LLM_MODEL设置为要使用的模型。(Vicuna-v1.5, 目前Vicuna-v1.5模型(基于llama2)已经开源了,推荐使用这个模型通过设置LLM_MODEL=vicuna-13b-v1.5
3. Run
(Optional) load examples into SQLlite
bash ./scripts/examples/load_examples.sh
On windows platform:
.\scripts\examples\load_examples.bat
1.Run db-gpt server
python pilot/server/dbgpt_server.py
打开浏览器访问http://localhost:5000
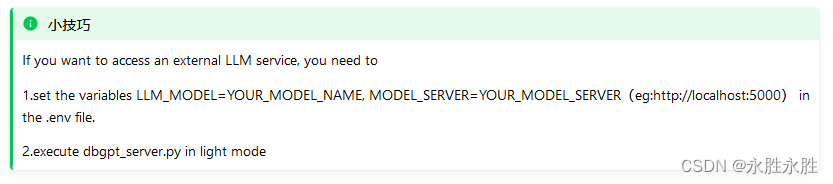
如果你想了解web-ui, 请访问https://github./csunny/DB-GPT/tree/new-page-framework/datacenter
python pilot/server/dbgpt_server.py --light
Multiple GPUs
DB-GPT默认加载可利用的gpu,你也可以通过修改 在.env文件 CUDA_VISIBLE_DEVICES=0,1来指定gpu IDs
你也可以指定gpu ID启动
# Specify 1 gpu
CUDA_VISIBLE_DEVICES=0 python3 pilot/server/dbgpt_server.py
# Specify 4 gpus
CUDA_VISIBLE_DEVICES=3,4,5,6 python3 pilot/server/dbgpt_server.py
同时你可以通过在.env文件设置MAX_GPU_MEMORY=xxGib修改每个GPU的最大使用内存
Not Enough Memory
DB-GPT 支持 8-bit quantization 和 4-bit quantization.
你可以通过在.env文件设置QUANTIZE_8bit=True or QUANTIZE_4bit=True
Llama-2-70b with 8-bit quantization 可以运行在80GB VRAM机器, 4-bit quantization可以运行在 48 GB VRAM
二、docker安装
1、安装docker镜像
docker pull eosphorosai/dbgpt:latest
bash docker/build_all_images.sh
docker images|grep "eosphorosai/dbgpt"
你也可以docker/build_all_images.sh构建的时候指定参数
bash docker/build_all_images.sh \
--base-image nvidia/cuda:11.8.0-runtime-ubuntu22.04 \
--pip-index-url https://pypi.tuna.tsinghua.edu.cn/simple \
--language zh
可以指定命令bash docker/build_all_images.sh --help查看如何使用
2、运行容器
Run with local model and SQLite database
docker run --gpus all -d \
-p 5000:5000 \
-e LOCAL_DB_TYPE=sqlite \
-e LOCAL_DB_PATH=data/default_sqlite.db \
-e LLM_MODEL=vicuna-13b-v1.5 \
-e LANGUAGE=zh \
-v /data/models:/app/models \
--name dbgpt \
eosphorosai/dbgpt
打开浏览器访问http://localhost:5000
-e LLM_MODEL=vicuna-13b-v1.5, means we use vicuna-13b-v1.5 as llm model, see /pilot/configs/model_config.LLM_MODEL_CONFIG
-v /data/models:/app/models, 指定挂载的模型文件 directory /data/models to the docker container directory /app/models, 你也可以替换成你自己的模型.
你也可以通过命令查看日志
docker logs dbgpt -f
Run with local model and MySQL database
docker run --gpus all -d -p 3306:3306 \
-p 5000:5000 \
-e LOCAL_DB_HOST=127.0.0.1 \
-e LOCAL_DB_PASSWORD=aa123456 \
-e MYSQL_ROOT_PASSWORD=aa123456 \
-e LLM_MODEL=vicuna-13b-v1.5 \
-e LANGUAGE=zh \
-v /data/models:/app/models \
--name db-gpt-allinone \
db-gpt-allinone
打开浏览器访问http://localhost:5000
-e LLM_MODEL=vicuna-13b-v1.5, means we use vicuna-13b-v1.5 as llm model, see /pilot/configs/model_config.LLM_MODEL_CONFIG
-v /data/models:/app/models, 指定挂载的模型文件 directory /data/models to the docker container directory /app/models, 你也可以替换成你自己的模型.
你也可以通过命令查看日志
docker logs db-gpt-allinone -f
Run with openai interface
PROXY_API_KEY="You api key"
PROXY_SERVER_URL="https://api.openai.com/v1/chat/completions"
docker run --gpus all -d -p 3306:3306 \
-p 5000:5000 \
-e LOCAL_DB_HOST=127.0.0.1 \
-e LOCAL_DB_PASSWORD=aa123456 \
-e MYSQL_ROOT_PASSWORD=aa123456 \
-e LLM_MODEL=proxyllm \
-e PROXY_API_KEY=$PROXY_API_KEY \
-e PROXY_SERVER_URL=$PROXY_SERVER_URL \
-e LANGUAGE=zh \
-v /data/models/text2vec-large-chinese:/app/models/text2vec-large-chinese \
--name db-gpt-allinone \
db-gpt-allinone
-e LLM_MODEL=proxyllm, 通过设置模型为第三方模型服务API, 可以是openai, 也可以是fastchat interface…
-v /data/models/text2vec-large-chinese:/app/models/text2vec-large-chinese, 设置知识库embedding模型为text2vec. container.”
打开浏览器访问http://localhost:5000
3、AutoDL部署
创建实例
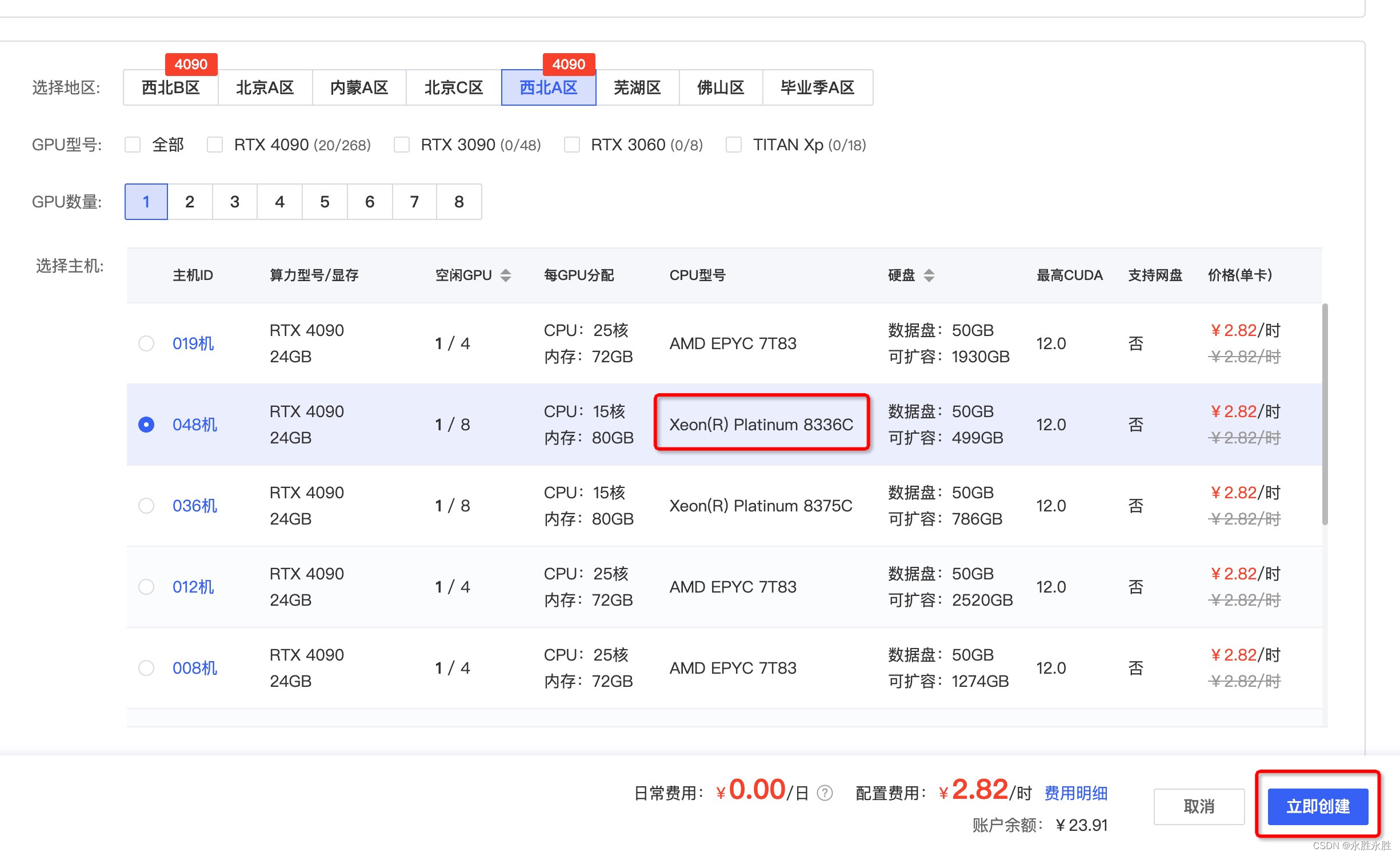
1、选择右侧镜像AutoDL创建实例
2、选择主机环境,GPU环境,这里CPU类型选择Xeon®Platnum8336C,GPU根据情况,建议4090
3、开机

4、打开jupyterLab
 5、选择终端
5、选择终端
终端构建过程
1.安装环境依赖
设置加速
source /etc/network_turbo
conda activate dbgpt_env
2.模型准备(这里已经准备好了chatglm2-6b-int4)
3.启动数据库
service mysql start
如果遇到mysql实例启动问题,需要卸载重装下

#卸载
sudo apt-get autoremove --purge mysql-server
sudo apt-get remove mysql-server
sudo apt-get autoremove mysql-server
sudo apt-get remove mysql-common
sudo apt update
sudo apt install mysql-server
service mysql start
4.启动DBGPT服务
python /root/DB-GPT/pilot/server/dbgpt_server.py --port 6006
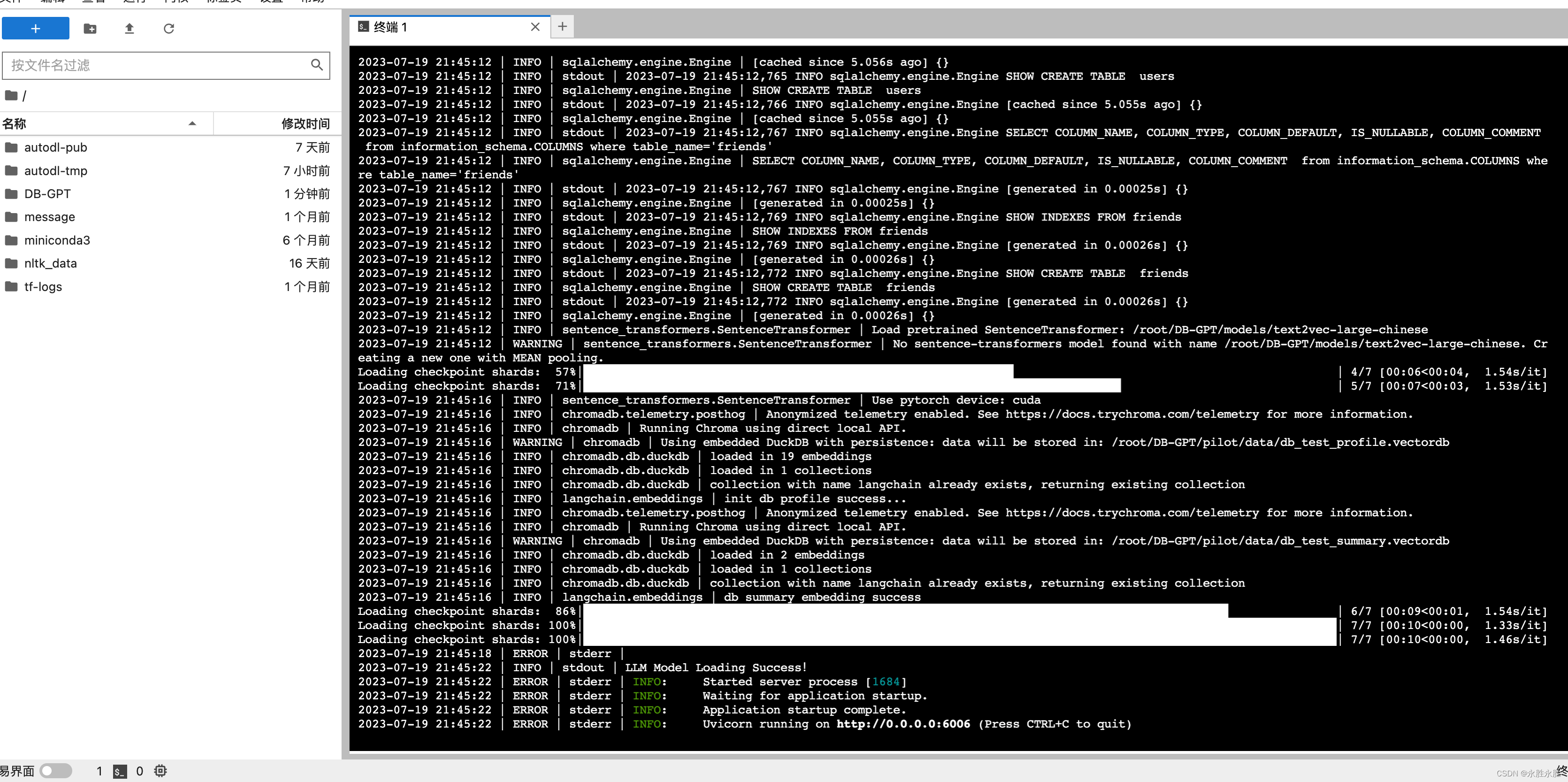
访问服务
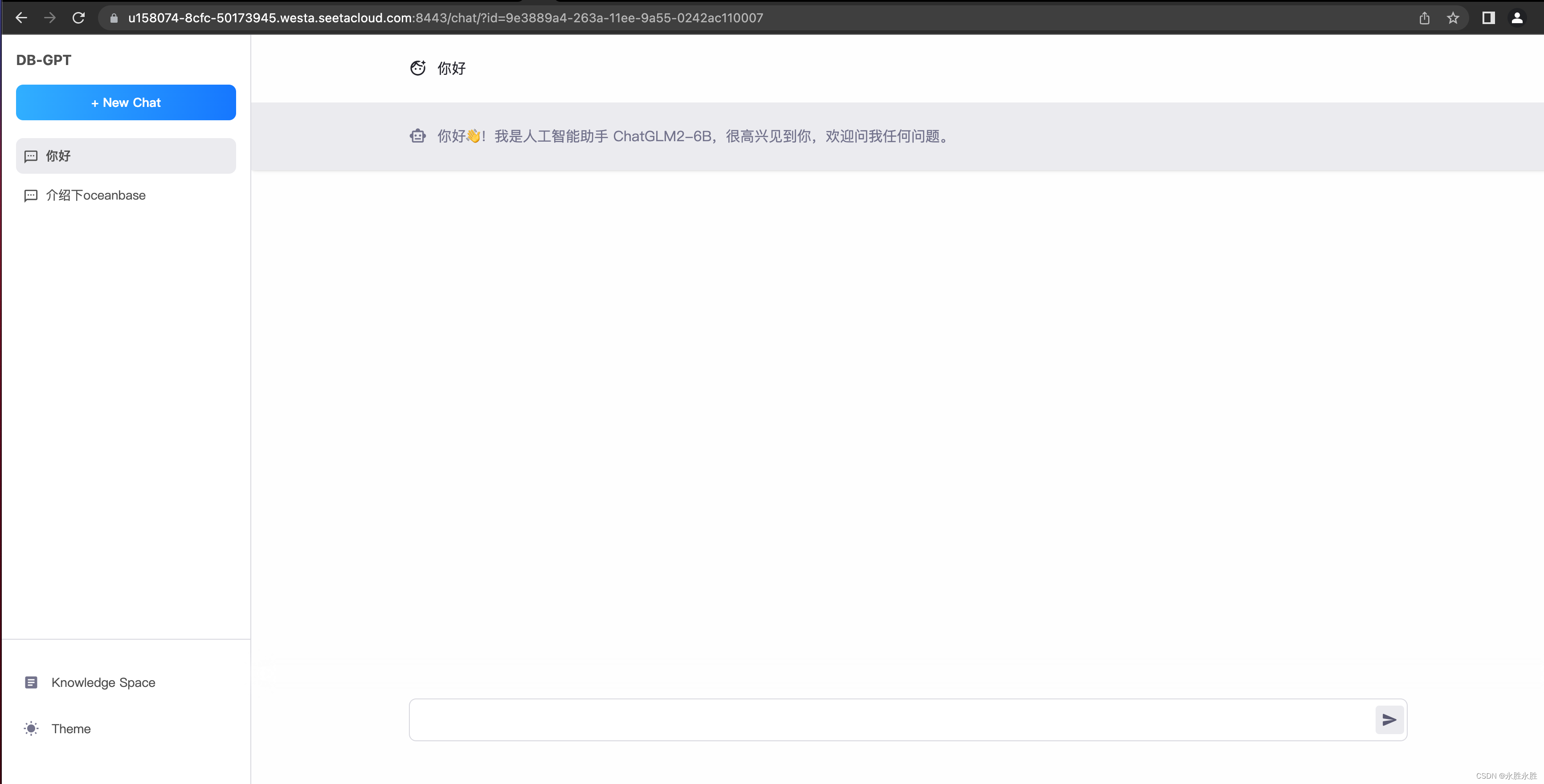
使用其他模型
chatgpt
1.申请openai API_KEY

2.修改/root/DB-GPT/.env配置文件
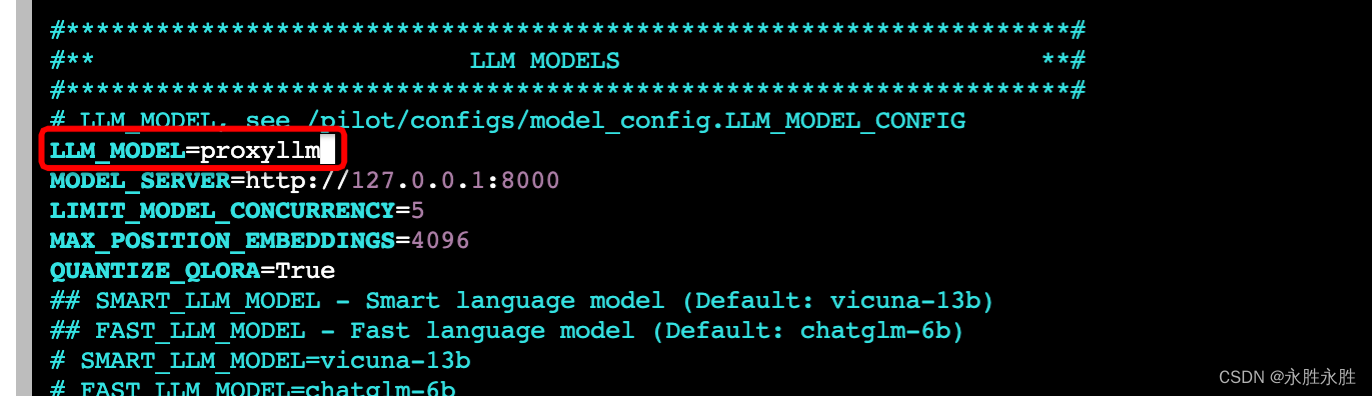
chatglm-6b2
1.下载chatglm-6b2模型(确保你的数据盘足够,chatglm-6b 24G)
cd /root/autodl-tmp/models
git lfs clone https://huggingface.co/THUDM/chatglm2-6b
2.修改/root/DB-GPT/.env配置文件
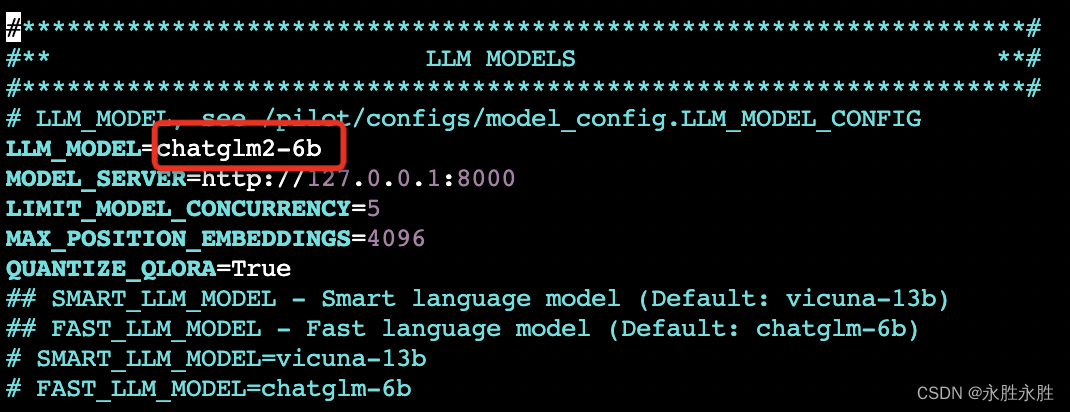
vicunna-13b
1.下载vicuna-13b模型(确保你的数据盘足够,vicunna-13b有50G)
cd /root/autodl-tmp/models
git lfs clone https://huggingface.co/Tribbiani/vicuna-13b
2.修改/root/DB-GPT/.env配置文件