COCO-stuff数据集
COCO-Stuff数据集对COCO数据集中全部164K图片做了像素级的标注。
80 thing classes, 91 stuff classes and 1 class ‘unlabeled’

数据集下载
wget --directory-prefix=downloads http://images.cocodataset.org/zips/train2017.zip
wget --directory-prefix=downloads http://images.cocodataset.org/zips/val2017.zip
wget --directory-prefix=downloads http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
解压数据集
mkdir -p dataset/images
mkdir -p dataset/annotations
unzip downloads/train2017.zip -d dataset/images/
unzip downloads/val2017.zip -d dataset/images/
unzip downloads/stuffthingmaps_trainval2017.zip -d dataset/annotations/
下载完成数据集后需要生成数据集的读取文件,即train.txt,val.txt,根据先前cityspaces数据集的文件格式,博主发现COCO-stuff数据集的结构更为简单,因此便自己写了数据集目标生成代码,代码如下:
import os
import random
filePath1 = '/data/datasets/cocostuff/dataset/images/train2017/'
filePath2 = '/data/datasets/cocostuff/dataset/annotations/train2017/'
list_data1=os.listdir(filePath1)
list_data2=os.listdir(filePath2)
file = open("/data/datasets/cocostuff/dataset/train.txt", 'w+')
for i,j in zip(list_data1,list_data2):
file.write('/data/datasets/cocostuff/dataset/images/train2017/'+i+' ')
file.write('/data/datasets/cocostuff/dataset/annotations/train2017/'+j+'\n')
file.close()
生成的目录文件如下:其中第一组数据是数据集图片地址,第二组数据是标注文件地址
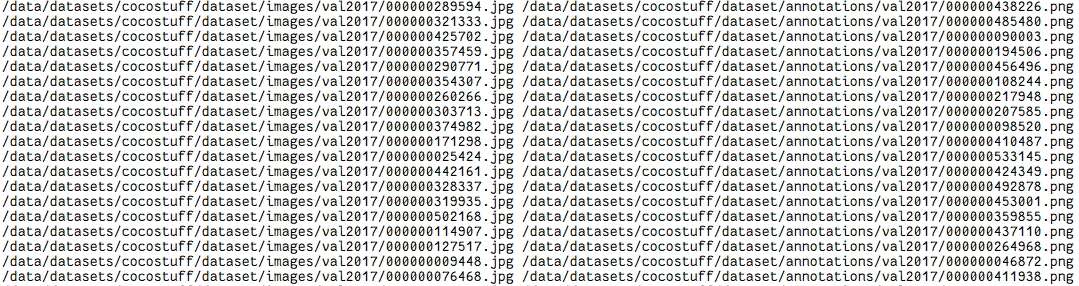
然而,却报错了,提升pre与lable不一致,即图片维度不一致,此时才发现,先前写的目录生成文件没有将图片与标注正确对应,重新改写:
import os
import random
path="train2017/"
filePath1 = '/data/datasets/cocostuff/dataset/images/'+path
list_data1=os.listdir(filePath1)
file = open("/data/datasets/cocostuff/dataset/train.txt", 'w+')
for i in list_data1:
i=os.path.splitext(i)[0]
file.write('/data/datasets/cocostuff/dataset/images/'+path+i+'.jpg ')
file.write('/data/datasets/cocostuff/dataset/annotations/'+path+i+'.png'+'\n')
file.close()
生成数据集目录地址后,即可编辑数据集配置文件。
修改数据集配置文件,新建cfg文件,即在configs文件夹的rtformer中新建rtformer_cocostuff_512x512_120k.yml,具体内容如下:
_base_: '../_base_/coco_stuff.yml'
batch_size: 3 # total batch size: 4 * 3
iters: 190000
train_dataset:
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [520, 520]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
val_dataset:
transforms:
- type: Resize
target_size: [2048, 1024]
keep_ratio: True
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
export:
transforms:
- type: Resize
target_size: [2048, 512]
keep_ratio: True
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
optimizer:
_inherited_: False
type: AdamW
beta1: 0.9
beta2: 0.999
weight_decay: 0.0125
lr_scheduler:
_inherited_: False
type: PolynomialDecay
learning_rate: 4.0e-4
power: 1.
end_lr: 1.0e-6
warmup_iters: 1500
warmup_start_lr: 1.0e-6
loss:
types:
- type: CrossEntropyLoss
coef: [1, 0.4]
model:
type: RTFormer
base_channels: 64
head_channels: 128
use_injection: [True, False]
pretrained: https://paddleseg.bj.bcebos.com/dygraph/backbone/rtformer_base_backbone_imagenet_pretrained.zip
新建coco-stuff.yaml文件,配置数据集:
batch_size: 2
iters: 80000
train_dataset:
type: Dataset
dataset_root: /
train_path: /data/datasets/cocostuff/dataset/train.txt
num_classes: 182
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [520, 520]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mode: train
val_dataset:
type: Dataset
dataset_root: /
val_path: /data/datasets/cocostuff/dataset/val.txt
num_classes: 182
transforms:
- type: Normalize
mode: val
optimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1]
随后便可以运行了
报错问题
报错1:这个问题令我感到困惑,因为先前已经用该环境训练过cityspces数据集,但还是重新又部署了一下环境,但依旧出错,最后发现是由于博主的数据集类别设置错误导致的,这实在是令人匪夷所思。
OSError: (External) CUDNN error(8), CUDNN_STATUS_EXECUTION_FAILED. [Hint: Please search for the error code(8) on website (https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnStatus_t) to get Nvidia's official solution and advice about CUDNN Error.] (at /paddle/paddle/phi/kernels/gpudnn/conv_grad_kernel.cu:502)
为以防万一,还是给出环境配置:
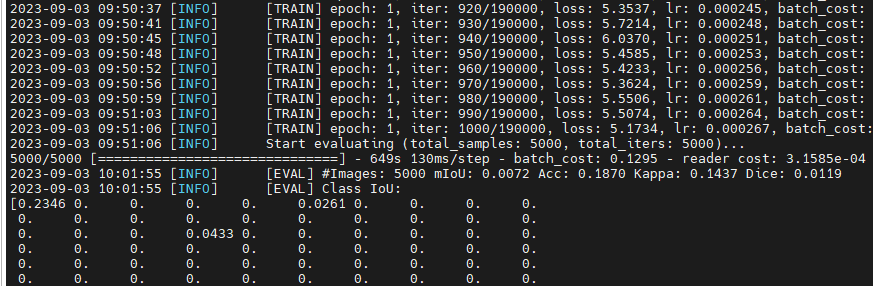
最终运行train.py文件即可
报错2
The axis is expected to be in range of [0, 0), but got 0
[Hint: Expected axis >= -rank && axis < rank == true, but received axis >= -rank && axis < rank:0 != true:1.] (at ../paddle/phi/infermeta/multiary.cc:961)
这个似乎是版本问题导致的,将paddle调整到2.4.0后该问题就解决了。
报错3
ValueError: (InvalidArgument) The shape of input[0] and input[1] is expected to be equal.But received input[0]'s shape = [1], input[1]'s shape = [1, 1].
[Hint: Expected inputs_dims[i].size() == out_dims.size(), but received inputs_dims[i].size():2 != out_dims.size():1.] (at /paddle/paddle/phi/kernels/funcs/concat_funcs.h:55)
似乎是之前博主修改了metrics.py文件导致的,但好像并不是,保持metrics.py文件原样即可,修改下数据集目录即可。
警告
Warning:: 0D Tensor cannot be used as 'Tensor.numpy()[0]' . In order to avoid this problem, 0D Tensor will be changed to 1D numpy currently, but it's not correct and will be removed in release 2.6. For Tensor contain only one element, Please modify 'Tensor.numpy()[0]' to 'float(Tensor)' as soon as possible, otherwise 'Tensor.numpy()[0]' will raise error in release 2.6.
警告提醒,据说是该设计在paddle2.6已经被弃用了,但该警告其实并不影响实验进程,只是看着不舒服而已,那就不看好了。但作为一个完美主义者,怎么能容忍这种情况呢,而且这样输出警告会给日志文件造成很大负担,因此果断降低版本。2.4.0的是可以的。


![[管理与领导-66]:IT基层管理者 - 辅助技能 - 4- 职业发展规划 - 乌卡时代(VUCA )的团队管理思维方式的转变](https://img-blog.csdnimg.cn/bb97d59f814e4c9bb5a3b55b7b94eaa1.png)