1.考虑调整这个neural network的结构尝试让这个loss降低
(1)Linear(inputdim,64) - ReLU-Linear(64,1), loss=0.7174
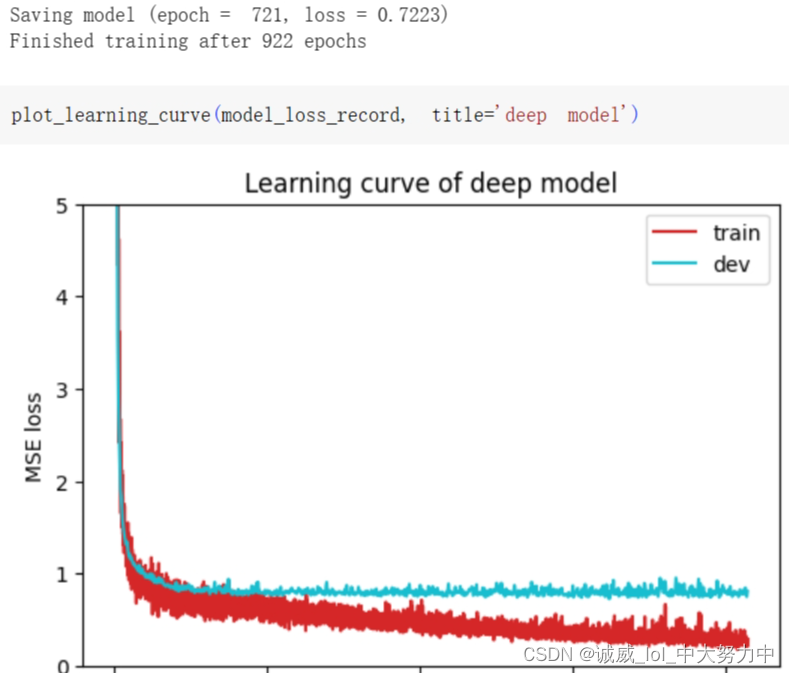
(2)Linear(inputdim,64) - ReLU-Linear(64,64) -ReLU-Linear(64,1),loss = 0.6996
(3) 这样设置的话,3个linear层中间夹着2个ReLU激活函数:
这样设置的话,3个linear层中间夹着2个ReLU激活函数:

(4)2个Linear层中间夹着2个ReLU激活函数:


(5)将2linear夹2ReLU中的w向量空间改为64:


(6)要不要加到3层的L-ReLU-L-ReLU-L-ReLU-L:

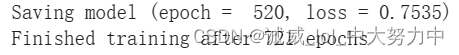
然而,效果并没有变好
2.下面考虑对上面的0.6996进一步优化,考虑从hypeparame 那里入手:
(1)初始0.6996时候的config:

(2)先尝试调整learning rate:0.001 --> 0.005或者 0.0001
0.005时,非常糟糕
0.0001时,也没有好的表现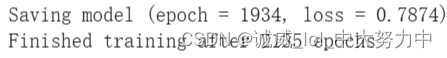
(3)再考虑调整momentum这个惯量:0.9 --> 1.0 或者0.8:
1.0时,直接完蛋:![]()
0.8时,也没有更好![]()
(4)那个early stop不打算调了,估计没戏,最后调一下这个batch_size:270 -->100,200,300,400
batch_size=100:
batch_size=200: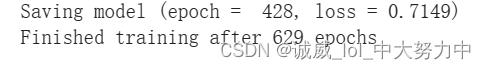
batch_size=300: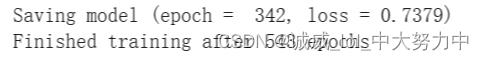
batch_size=400:
果然,270还是最好的结果。。。
3.我改用更加 “多的神经元”:
(1)一个ReLU

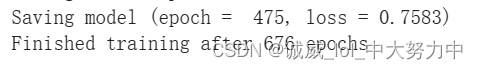
(2)2个ReLU:
出现了overfitting的case了,training上面的loss降下去了,但是validation上面的降不下去,
算了,以后再说。。。待我学成归来,定将你斩落马下