文章目录
- 概念
- 倒排索引
- es的一些概念
- 安装ES、Kibana
- 总结
- 索引库操作
- mapping映射属性
- 创建索引库和映射
- 查询索引库
- 修改索引库
- 删除索引库
- 总结
- 文档操作
- 新增文档
- 查询文档
- 删除文档
- 修改文档
- 全量修改
- 增量修改
- RestAPI
- 引入依赖、初始化RestClient
- 索引库 操作
- 创建索引库
- 删除索引库
- 判断索引库是否存在
- 文档操作
- 新增文档
- 查询文档
- 删除文档
- 修改文档
- 批量导入文档
概念
倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
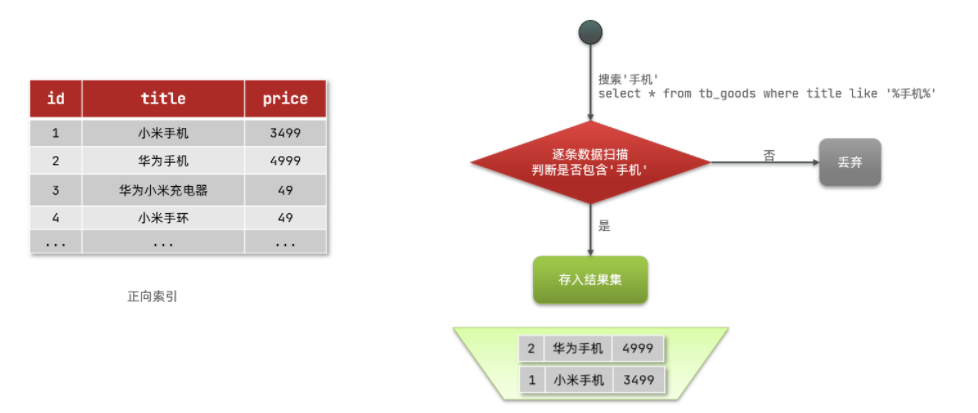
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
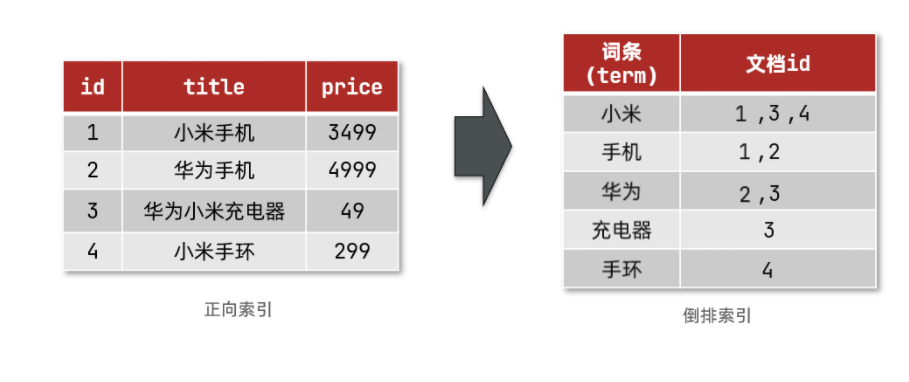
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对 文档数据或 用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个 文档的数据利用算法分词,得到一个个词条
- 创建表,每行 数据包括 词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:
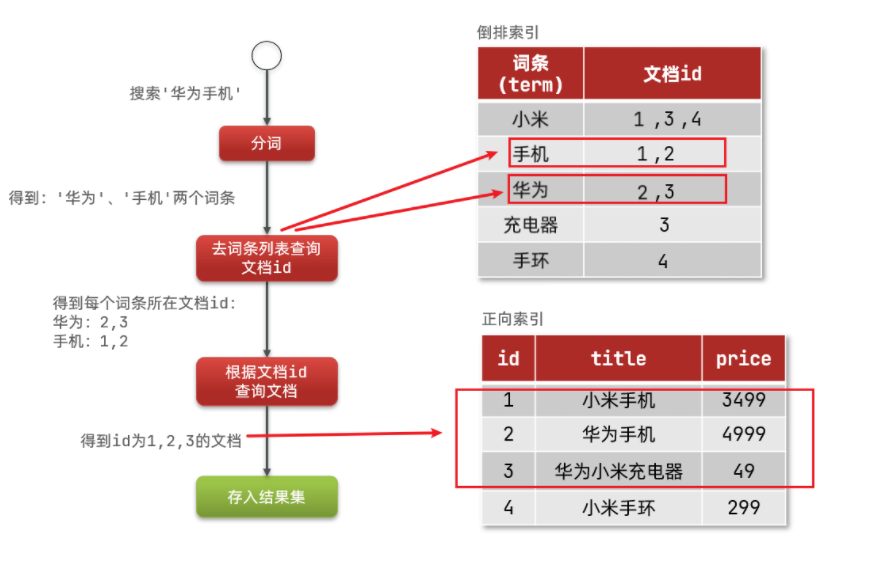
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
es的一些概念
文档和字段
elasticsearch是面向文档(Document)存储的,可以是 数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以 把索引当做 是数据库中的表
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
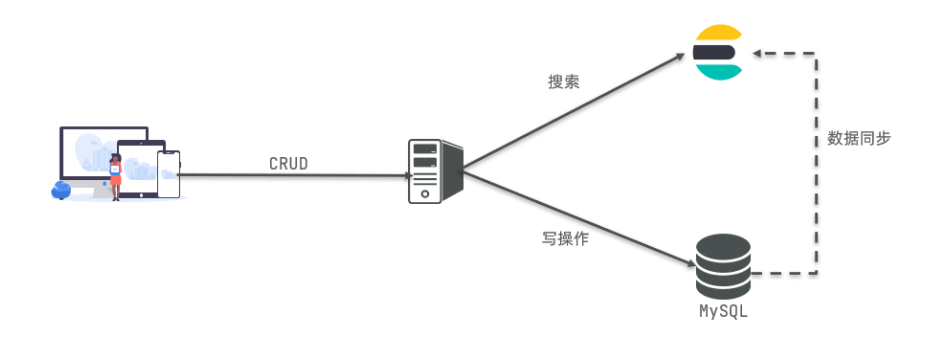
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
安装ES、Kibana
点击地址
总结
分词器的作用是什么?
- 创建 倒排索引时 对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用 config目录的 IkAnalyzer.cfg.xml 文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
索引库操作
索引库 就类似 数据库表,mapping映射 就类似表的结构。
我们要向 es中存储数据,必须先创建“库”和“表”
mapping映射属性
mapping 是 对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "我只不过是个菜鸟",
"email": "zy@163.com",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要 index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
修改索引库
倒排索引 结构虽然不复杂,但是 一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
格式:
DELETE /索引库名
总结
索引库操作 有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
文档操作
新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
查询文档
GET /{索引库名称}/_doc/{id}
删除文档
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
修改文档
全量修改
全量修改 是覆盖原来的文档,其本质是:
- 根据 指定的 id删除文档
- 新增 一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
示例:
PUT /heima/_doc/1
{
"info": "sdwe手动",
"email": "zy@163.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
RestAPI
create database hotel;
引入依赖、初始化RestClient
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.17.7</elasticsearch.version>
</properties>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
为了单元测试方便,我们创建一个测试类 HotelIndexTest,然后将初始化的代码编写在**@BeforeEach**方法中:
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient (RestClient.builder (
HttpHost.create ("http://192.168.111.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close ();
}
索引库 操作
创建索引库
创建 索引库的API如下:
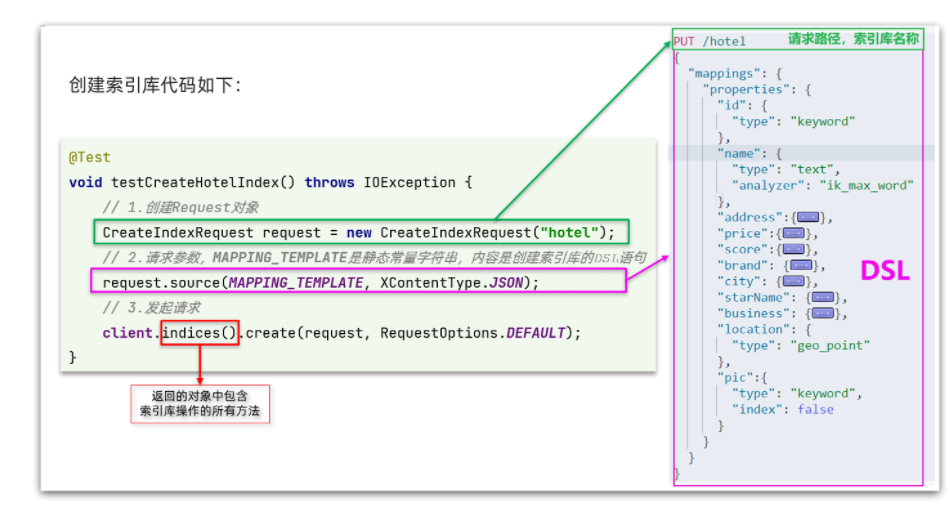
代码分为三步:
- 1)创建 Request对象。因为是创建索引库的操作,因此 Request是CreateIndexRequest。
- 2)添加请求参数,其实就是DSL的JSON参数部分。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求,client.indices() 方法的返回值是IndicesClient类型,封装了 所有与索引库操作有关的方法
MAPPING_TEMPLATE:创建索引库 映射json
public class HotelConstants {
public static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
测试:
@Test
void createHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
删除索引库
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
判断索引库是否存在
@Test
void testExistsHotelIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
文档操作
@Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient (RestClient.builder (
HttpHost.create ("http://192.168.111.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close ();
}
新增文档
索引库 实体类
数据库查询后的结果是一个Hotel类型的对象。结构如下
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}
与我们的索引库结构
存在差异:
- longitude和latitude需要合并为 location
因此,我们需要定义一个新的类型,与索引库结构吻合:
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
语法说明:
POST /{索引库名}/_doc/1
{
"name": "Jack",
"age": 21
}

我们导入酒店数据,基本流程一致,但是需要考虑几点变化:
- 酒店数据来自于数据库,我们需要先查询出来,得到hotel对象
- hotel对象需要转为HotelDoc对象
- HotelDoc需要序列化为json格式
@Test
void testAddDocument() throws IOException {
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
// 2.转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String json = JSON.toJSONString(hotelDoc);
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
查询文档

@Test
void testGetDocumentById() throws IOException {
// 1.准备Request
GetRequest request = new GetRequest("hotel", "61083");
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
删除文档
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
修改文档
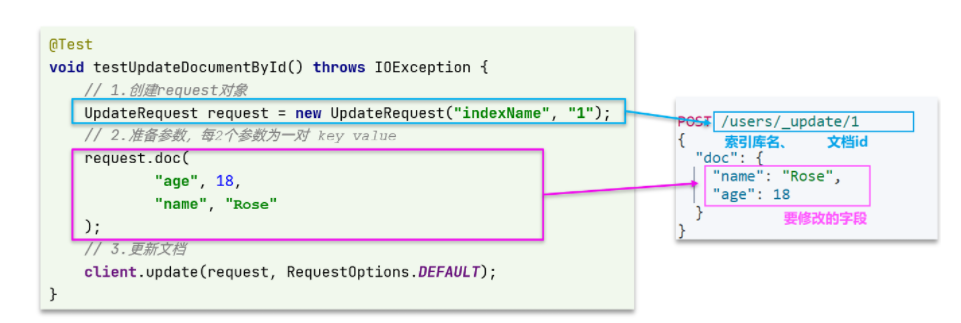
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}
批量导入文档
批量处理BulkRequest,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,用来添加其他请求:
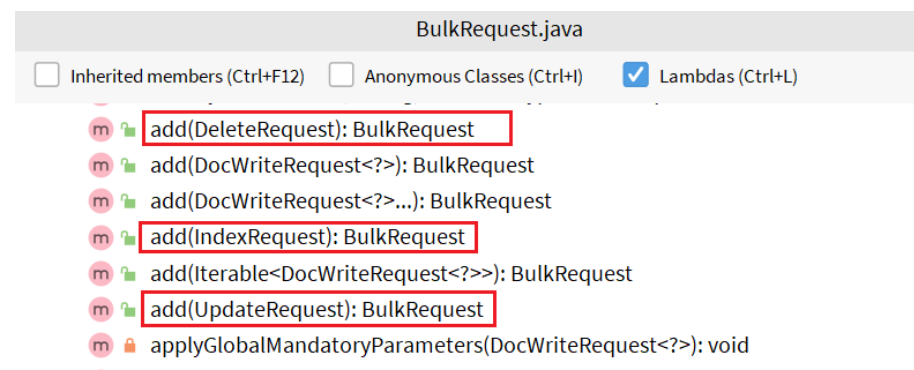
可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
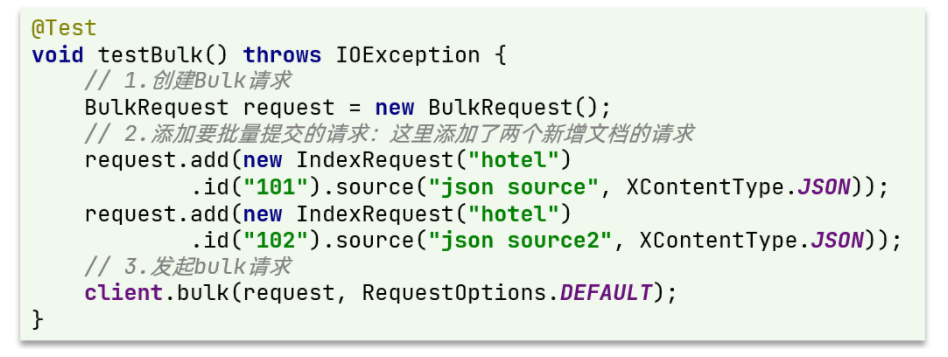
@Test
void testBulkRequest() throws IOException {
// 批量查询酒店数据
List<Hotel> hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
![[附源码]Python计算机毕业设计黑河学院校友交流网站Django(程序+LW)](https://img-blog.csdnimg.cn/a8e98b3df1fc4e81a24506f0a2a78f46.png)



![[paddledet][深度学习][原创]paddledet打印出FLops正确方法](https://img-blog.csdnimg.cn/e98419a5c2454f1991e01fd0f1b1e805.png)

![[附源码]Node.js计算机毕业设计黑格伯爵国际英语贵族学校官网Express](https://img-blog.csdnimg.cn/ea11f0c2b11345ff950825ba5fb52fe0.png)