有时为了排版需要,我们可能需要在文章的中英文之间添加空格,特别是中文中引用了英文单词时,这种情况使用正则表达式整体修订是最明智的做法。首先,推荐使用在线的正则表格式工具:https://regex101.com/ , 该工具非常强大,支持几乎所有的编程语言风格!
本文所谓的“英文单词”实为:由多个英文字符、空格、数字、小数点、连字符、下划线构成的复合短语,其中英文字符是必须的(避免替换类似:“第1节” 这样的文本),其他字符可选,这种Pattern除了可以匹配纯单词外,还能匹配类似S3、EC2、V1.0、Example-1等文本。以下具体的做法,由于替换的方式不同,所以以下几种替换需要依次执行。
1. 前后都是中文字符,中间是英文单词
正则表达式:
([\u4e00-\u9fa5]+)([A-Za-z]+[\s\d\.\-_]*)+([\u4e00-\u9fa5]+)
替换表达式:
$1 $2 $3
2. 前面是中文字符,中间是英文单词,后面是中文标点符号
正则表达式:
([\u4e00-\u9fa5]+)([A-Za-z]+[\s\d\.\-_]*)+([\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b])
替换表达式:
$1 $2$3
3. 以英文单词开头(段落开始处),后面是中文字符
正则表达式:
(^([A-Za-z]+[\s\d\.\-\_]*)+)([\u4e00-\u9fa5]+)
替换表达式:
$1 $3
细节说明:
在测试第3种情况时,遇到一个“弯”,简单记录一下。起初测试的是下面的版本:
^([A-Za-z]+[\s\d\.\-\_]*)+([\u4e00-\u9fa5]+)
发现对于Spark 2 Spark-2 Spark_2 Spark2.0是种测试情况这样的文本,虽然能匹配上,但是替换时的分组有问题:
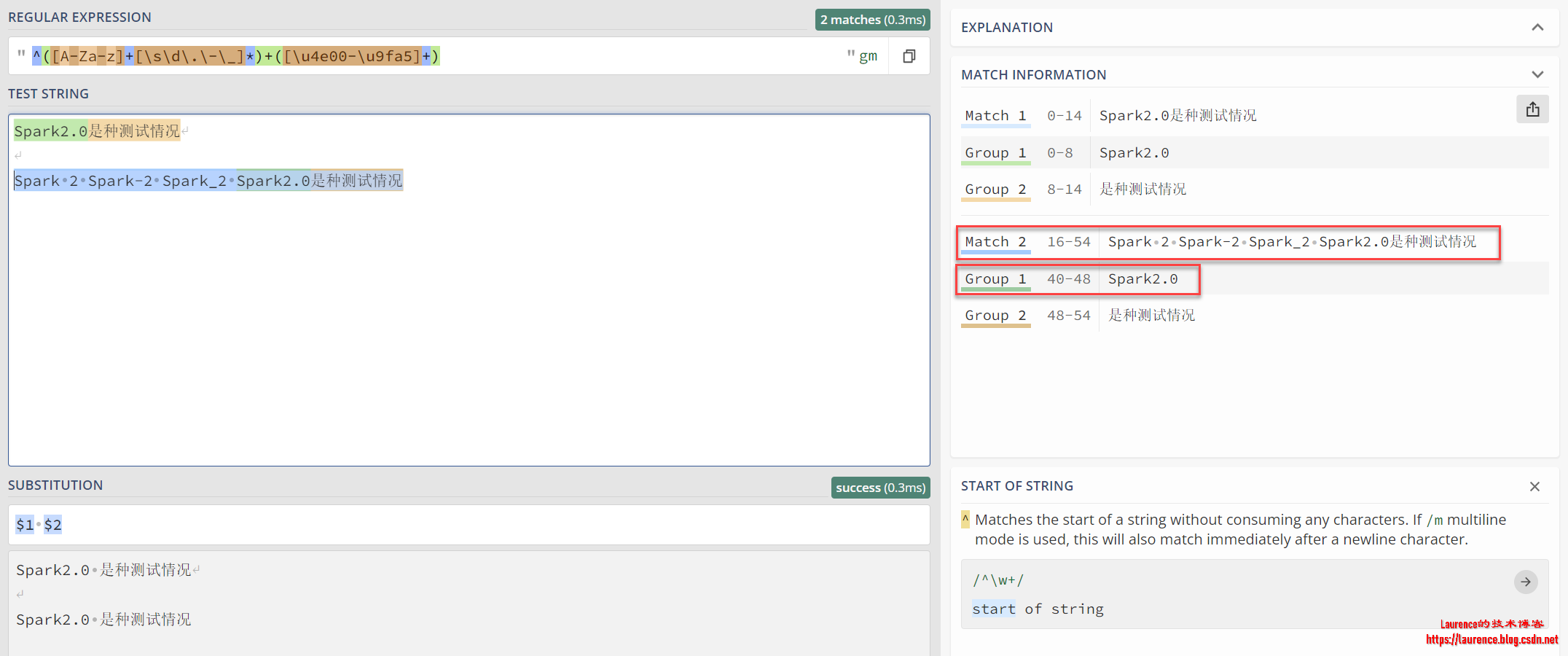
从上面的截图来看,第1分组实际上是最后一组单词,这就导致替换后前面的Spark 2 Spark-2 Spark_2 都丢失了。这个问题并不是匹配表达式写的不对,而是提取分组不对,对比上面的正确版本可知,我们需要在^([A-Za-z]+[\s\d\.\-\_]*)+的外面再用小括号包裹一层,从而形成一个独立分组,相应的分组替换就变成了$1 $3:
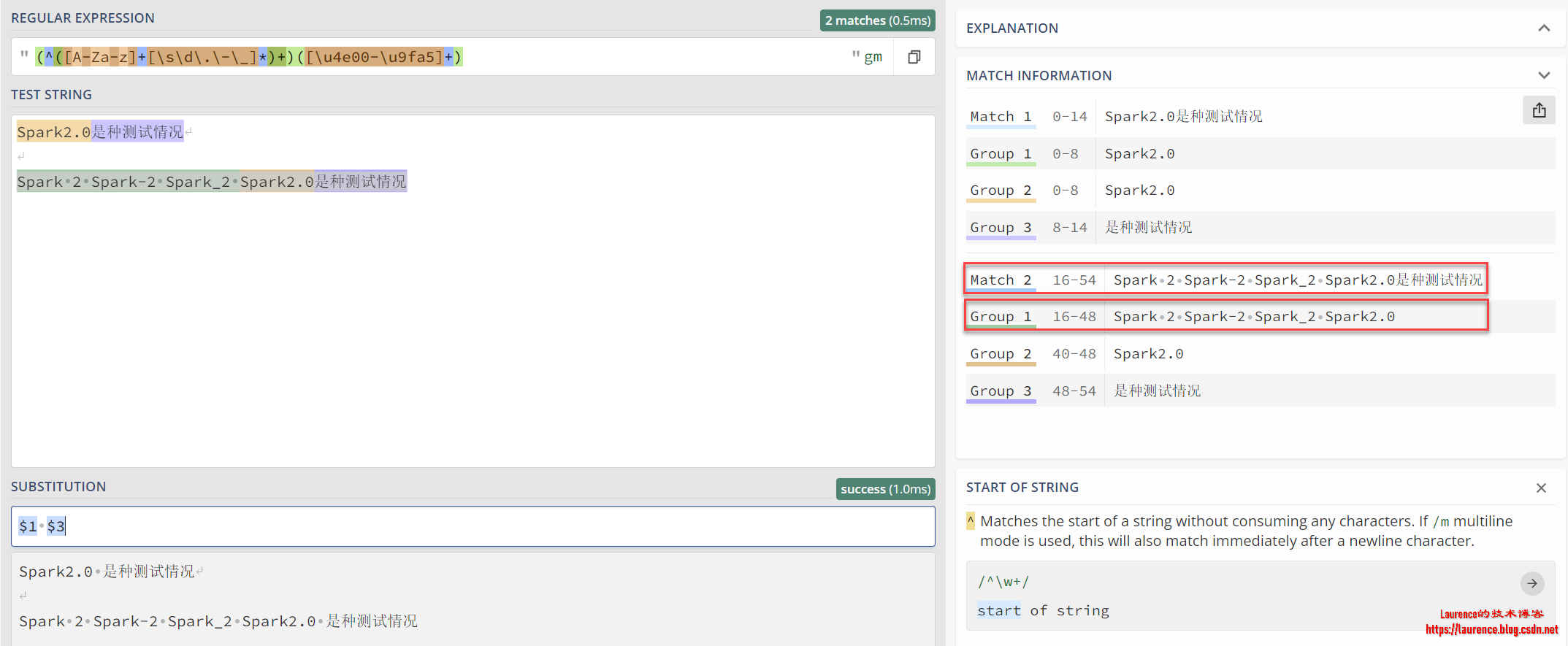
测试文本:
测试Spark 2这种情况
测试Spark-2这种情况
测试Spark_2这种情况
测试Spark2.0这种情况
测试Spark 2 Spark-2 Spark_2 Spark2.0这种情况
Spark 2是种测试情况
Spark-2是种测试情况
Spark_2是种测试情况
Spark2.0是种测试情况
Spark 2 Spark-2 Spark_2 Spark2.0是种测试情况