大数据概念
大数据:无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现李和流程优化能力的海量、高增长率和多样化的信息资产。
大的概念是相对来说的:目前来说,大数据的规模至少10T以上。
目前单台主机一般只能存放1T左右的数据,所以要进行计算首先要进行分布式存储,分开到10台电脑中进行存储。然后后面的计算也必须基于分布式的存储结构来进行分布式运算。
大数据特点
- 大量(Volume)
- 高速(Velocity)
- 多样(Variety)
- 低价值密度(Value)
大数据应用
- 增加用户粘性:进行客户画像,推荐客户喜欢的内容。
- 多臂试探:当用户画像基本完成时,尝试推送其他内容,并重新画像。
- 发现多个事务之间的潜在关联性:比如纸尿布和啤酒。
- 获取商场的流量信息,分析运营情况。
- 保险/金融:挖掘潜在客户,助力保险行业精准营销。
大数据不是用来开发一个独立的软件,而且需要贴合其他软件来叠加使用,助力软件更加智能和贴合用户需求。
业务分析
数据部门搭建数据平台,分析数据指标。分析分为两种,一种是离线数仓分析,一种是实时分析。处理好后的展示环节交给前端处理。
大数据部门组织结构:
- 平台组:搭建Hadoop、Flume、Kafka、HBase平台
- 数据仓库组:ETL数据清洗、数据分析
- 实时组:实时指标分析
- 数据挖掘组:算法工程师、推荐系统工程师、用户画像工程师
- 报表开发组:javaEE工程师 + 前端工程师(非大数据部分)
Hadoop概述
Hadoop是什么
是一个分布式系统架构,Apache基金会所开发的。主要解决海量数据的存储和海量数据的分析计算问题。Hadoop通常指一个更广泛的概念,Hadoop生态圈(Hadoop, Hive, )
大数据之父:Doug Cutting,开发了Lucene,一个搜索引擎,类似谷歌搜索引擎。为了在对Lucene进行优化升级,提升面对大数据的查询效率,结合谷歌发布的三篇论文,实现了DFS和MapReduce机制,使Nutch搜索引擎性能飙升。之后项目立项更名为Hadoop,从此Hadoop诞生了。

Hadoop三大发行版本
- Apache原始版本
- 国外开发的图形化版本
- 国内的阿里云、腾讯云版本
Hadoop优势
- 高可靠性:有备份
- 高扩展性:可以扩展节点数量
- 高效性:Hadoop是并行运算的
- 高容错性:能够自动将失败的任务重新分配
Hadoop组成
- Hadoop1.x:
- HDFS数据存储
- MapReduce计算+资源调度
- Hadoop2.x/3.x:
- HDFS数据存储
- MapReduce计算
- Yarn资源调度
HDFS架构概述
- NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性
- DataNode(dn): 存储文件块数据, 以及校验和
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
YARN架构概述
- 永久节点:
- ResourceManager(RM): 汇总所有资源信息
- NodeManager(NM): 动态收集当前节点的资源情况
- 任务节点:
- ApplicationMaster(AM): 单个任务运行的管理员
- Container: 容器,相当于一台独立的服务器,里面封装了任务所需要的资源,如内存、CPU、磁盘、网络等,类似一个小虚拟机。
MapReduce架构概述
MapReduce有两个阶段。Map表示细分为子任务,Reduce表示合并计算结果。细分任务的名称为MapTask, 合并任务名称为ReduceTask(规约)。MapReduce这个名称概括了分布式系统进行计算的基本过程。
HDFS、YARN、MapReduce三者关系

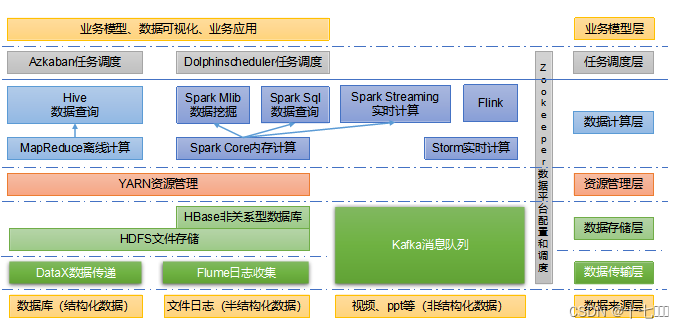
大数据技术生态体系
Hadoop搭建
创建模版机
- 最小化安装
- 安装一些必要软件
- 修改ip为静态ip
- 修改主机名和hosts映射文件
- 关闭防火墙
- 创建atguigu用户,配置sudo权限
- 在/opt目录下创建两个子目录
- module安装好的软件
- software安装包
- 修改module和software的所属者和所属组
使用xshell连接查询虚拟机ip地址:
- ip addr命令查看ip地址连接
安装jdk和Hadoop
- 使用ftp将jdk传输到software文件中
- 使用jar -zxfc解压到module文件中
- 配置环境变量
- profile.d目录下声明环境变量
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
shell的补充
- 父子shell项
- 父类定义变量子类不能获取:有办法获取,使用
export 变量名将父类变量传递给子类shell - 子类定义变量父类不能获取:获取不了
- 父类定义变量子类不能获取:有办法获取,使用
- 使用pstree命令可以查看进程之间的父子关系
- shell的三种执行方式
- 开子bash的形式执行,使用子类的shell的环境变量
bash + 脚本文件chmod 777 脚本文件 + ./ 脚本文件
- 在当前bash中执行,使用当前shell的环境变量
. 或者 source 脚本文件
- 一般情况下脚本都是开子shell来执行的,除了环境变量是父shell中运行
- 开子bash的形式执行,使用子类的shell的环境变量




![[C/C++]天天酷跑超详细教程-中篇](https://img-blog.csdnimg.cn/79e2f0cd769945f5b326f0c2dcb85c74.jpeg)