分析&回答
什么是反压(backpressure)
反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。
反压的影响
反压并不会直接影响作业的可用性,它表明作业处于亚健康的状态,有潜在的性能瓶颈并可能导致更大的数据处理延迟。反压对Flink 作业的影响:
- checkpoint时长:checkpoint barrier跟随普通数据流动,如果数据处理被阻塞,使得checkpoint barrier流经整个数据管道的时长变长,导致checkpoint 总体时间变长。
- state大小:为保证Exactly-Once准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier需要对齐,即接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致checkpoint变大。
- checkpoint是保证准确一次的关键,checkpoint时间变长有可能导致checkpoint超时失败,而state大小可能拖慢checkpoint甚至导致OOM。
Flink的反压
1.5 版本之前是采用 TCP 流控机制,而没有采用feedback机制
TCP 利用滑动窗口实现网络流控
TCP报文段首部有16位窗口字段,当接收方收到发送方的数据后,ACK响应报文中就将自身缓冲区的剩余大小设置到放入16位窗口字段。该窗口字段值是随网络传输的情况变化的,窗口越大,网络吞吐量越高。TCP 利用滑动窗口限制流量:
步骤1:发送端将 4,5,6 发送,接收端也能接收全部数据。

步骤2:consumer 消费了 2 ,接收端的窗口会向前滑动一格,即窗口空余1格。接着向发送端发送 ACK = 7、window = 1。

步骤3:发送端将 7 发送后,接收端接收到 7 ,但是接收端的 consumer 故障不能消费数据。这时候接收端向发送端发送 ACK = 8、window = 0 ,由于这个时候 window = 0,发送端是不能发送任何数据,也就会使发送端的发送速度降为 0。


TCP-based 反压机制的缺点

TCP-based 反压机制的缺点
- 单个Task的反压,阻塞了整个TaskManager的socket,导致checkpoint barrier也无法传播,最终导致checkpoint时间增长甚至checkpoint超时失败。
- 反压路径太长,导致反压时间延迟。
Flink(since V1.5)的 Credit-based 反压机制
在 Flink 层面实现反压机制,通过 ResultPartition 和 InputGate 传输 feedback 。
Credit-base 的 feedback 步骤:
- 每一次 ResultPartition 向 InputGate 发送数据的时候,都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息。(backlog 的作用是为了让消费端感知到我们生产端的情况)
- 如果下游有充足的 Buffer ,就会返还给上游 Credit (表示剩余 buffer 数量),告知发送消息(图上两个虚线是还是采用 Netty 和 Socket 进行通信)。

生产段发送backlog=1

消费端返回credit=3

当生产端用完buffer,返回credit=0
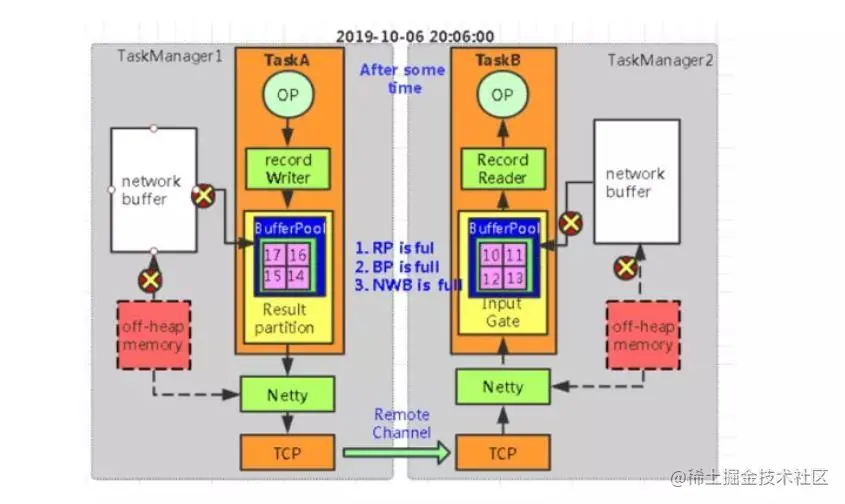
生产端也出现了数据积压
反思&扩展
怎么缓解、解决任务反压的情况?
事前:解决数据倾斜、算子性能等问题。
事中:在出现反压时:
- 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够够匀速消费数据,避免出现有的 Source 快,有的 Source 慢,导致窗口 input pool 打满,watermark 对不齐导致任务卡住。
- 关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。我们可以在数据回溯完成之后,再将 Checkpoint 打开。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!





![java八股文面试[多线程]——Synchronized优化手段:锁膨胀、锁消除、锁粗化和自适应自旋锁](https://img-blog.csdnimg.cn/img_convert/faeba682ad534b409ee0c0548f6f1f78.png)