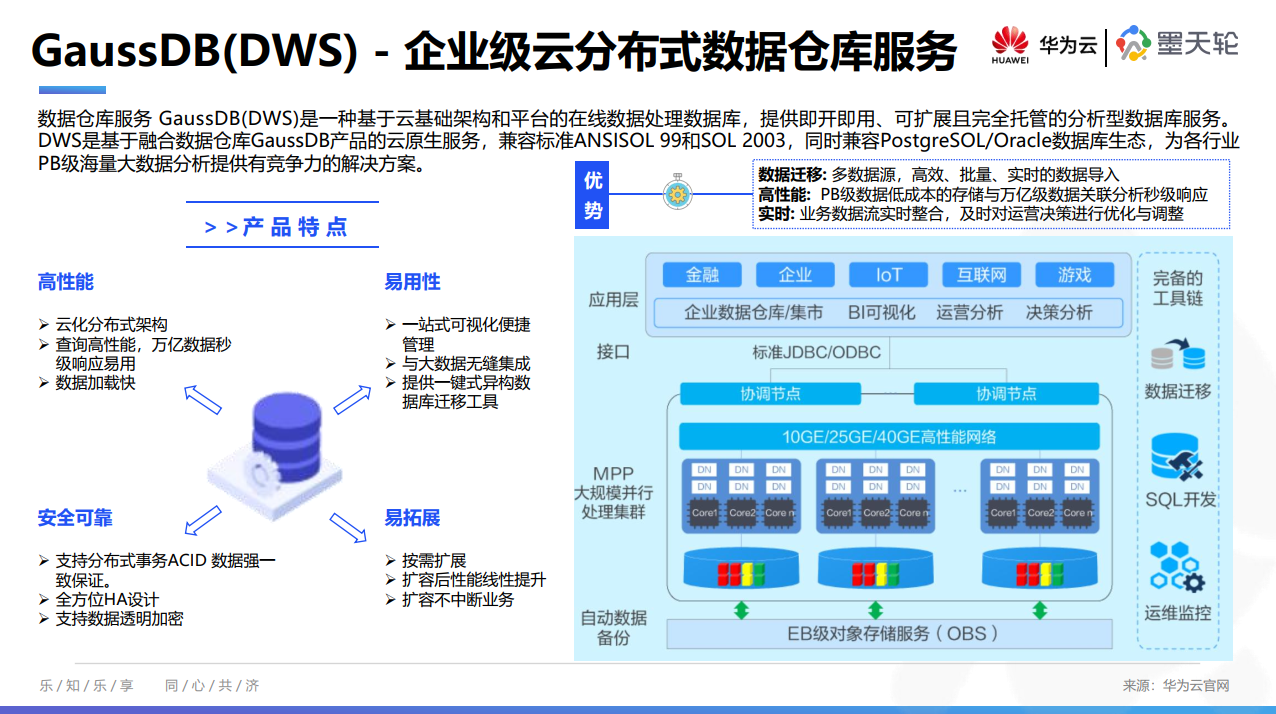
DEAP是一个新的用于快速验证和测试新想法的演化计算框架。它致力于直接地构建算法和数据结构的简单化。它可以很好地应用在并行机制中。下面的文档将会展示许多关键概念以及构建你自己的演化算法时的一些特征。
第一步
1、总览(从这里开始)
2、安装
3、如何进入端口?(porting guide)
基础教程
Part1:创造类型
Part2:操作与算法
Part3:记录数据
Part4:使用多进程
进阶教程
遗传程序设计(GP)
检查点?(checkpoint)
收敛控制
针对最优解的基准测试(BBOB)
与numpy的继承关系
1、总览
如果你已经习惯于其他的演化计算框架,你将会发现我们在DEAP中所做的事情是不同的。我们提供了创建适当类型的方法,而不是限制你使用预定义类型。我们使得你能够定制你的初始化选项而不是封闭它。我们希望你能够更明智地选择一些操作而不是使用预定义好的。我们允许你能够写一个适合于你自己需求的算法而不是仅仅提供许多封闭的算法。这个教程将通过说明DEAP的每一个程序组成来快速地展示DEAP的所有内容。
2、类型
首先要做的事情是思考适合你问题的类型。然后,不像之前的方法那样为你提供一些可用类型的列表,DEAP会为你构建适合你自己的。这个操作需要使用creator模块。创建一个合适的类型可能听起来很难,但是creator使得这个过程变得十分简单。事实上,这通常在单行操作上实现。例如:下面为一个最小值优化问题创建一个FitnessMin class,并且会从刚刚设置好的适应度列表中再创造一个individual class

3、初始化
一旦你创建了一个你需要为它们填充一些随机值的类型,DEAP可以通过简单的方法去完成它。Toolbox是一个包含了所有的初始化工具的容器,它可以做你需要它去完成任何事情。下面代码的目标就是去为个体和种群随机地生成浮点数类型的初始值。

这个产生初始种群的生成功能,是通过个体自身不断进行随机生成完成的。这个功能和它的默认参数已经被放入了toolbox中。例如,调用toolbox.population()将会有可能立即创建一个种群,更多的初始化方法将会在基础教程的Part1中以及后面的例子中讲到
4、操作
除了一些在tools模式下已经设定好的东西以外,操作与初始化类似。一旦你选择了一个最好的,简单的在toolbox中注册它们。除此之外你必须创造你的评估函数,下面展示具体的做法

这些已经注册的函数会被toolbox重命名,使得遗传算法(广义)不会依赖于操作的名称。还要注意的是,适应度本身是可以迭代的,这就是为什么evaluate函数必须返回元组的原因。更多的细节在后面中会说到。
5、算法
现在一切都准备就绪了,我们可以自己来写一个算法了。它通常在一个main()中执行。为了实现这个目标我们将简单地写一个迭代算法
def main():
pop = toolbox.population(n=300)
# Evaluate the entire population
fitnesses = list(map(toolbox.evaluate, pop))
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = fit
CXPB, MUTPB = 0.5, 0.2
fits = [ind.fitness.values[0] for ind in pop]
g = 0
# Begin the evolution
while max(fits) < 100 and g < 1000:
# A new generation
g = g + 1
print("-- Generation %i --" % g)
# Select the next generation individuals
offspring = toolbox.select(pop, len(pop))
# Clone the selected individuals
offspring = list(map(toolbox.clone, offspring))
# Apply crossover and mutation on the offspring
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < CXPB:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < MUTPB:
toolbox.mutate(mutant)
del mutant.fitness.values
# Evaluate the individuals with an invalid fitness 评估适应度无效的个体
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
pop[:] = offspring
# Gather all the fitnesses in one list and print the stats
fits = [ind.fitness.values[0] for ind in pop]
length = len(pop)
mean = sum(fits) / length
sum2 = sum(x*x for x in fits)
std = abs(sum2 / length - mean**2)**0.5
print(" Min %s" % min(fits))
print(" Max %s" % max(fits))
print(" Avg %s" % mean)
print(" Std %s" % std)使用在algorithm中四个已有的算法也是可以的,或者在这个模块中搭建一些其它区域的变化也是可行的。
6、总结
在这一节中,教程大致介绍了上述四个核心步骤的基本操作,并给出了一个寻找最大和的实例。
关键的步骤似乎均在toolbox中,无论是初始化还是遗传操作还是最后的选择,均可以使用toolbox对其进行register,一旦register一种方法,并搭建好计算框架便可以是一种新的模型,这可能就是前言中所说的“灵活性”。