文章目录
- 1、微服务的设计原则
- 1.1、服务拆分方法
- 1.2、微服务的设计原则
- 1.3、微服务架构
- 2、高并发系统的一些优化经验
- 2.1、提高性能
- 2.1.1、数据库优化
- 2.1.2、使用缓存
- 2.1.3、服务调用优化
- 2.1.4、动静分离
- 2.1.5、数据库读写分离
- 2.2、服务高可用
- 2.2.1、限流和服务降级
- 2.2.2、隔离术
- 2.2.3、网关过滤
- 2.2.4、断路器
- 3、简易的微服务实例
在微服务中,要解决的大问题是高并发问题,这也是分布式中最受到关注的问题之一。
1、微服务的设计原则
微服务并没有一个严格的定义,它只需要遵循一定的风格即可。正因为没有严格的定义,所以它也没有严格的设计规则,只有一些经验和工具可用。但是无论如何,作为微服务开发,首先要考虑的是服务拆分方法,其次是微服务的一些设计原则和整体架构。
1.1、服务拆分方法
做微服务开发的第一步,也是最重要的一步,是服务拆分。按照微服务风格的要求,首要考虑的是按业务拆分,这就要求架构师,先分析业务需求,做好业务边界,然后再按照业务模块对系统进行拆分。一般来说,拆分需要考虑以下几点:
- 独立性:拆分出来的服务,应该是独立的,它可以独立运行,支撑某一块业务,是一个独立的产品,应该具备高内聚和低耦合的特点,同时它会保留一些明确的接口,提供给第三方进行服务调用。
- 明确服务粒度:服务是根据业务的需要进行划分的,但是有时候需要考虑粒度。例如,用户服务按照公司业务,需要十分精细化地划分为企业用户和个人用户,而企业用户十分复杂,这个时候就可以考虑将用户服务,拆分为企业用户服务和个人用户服务了。当然,如果两者区别不大,业务不多,也可以不进行拆分,这些都需要根据业务数据的大小、复杂度和边界(是否清晰)来决定。
- 团队分配:微服务的风格要求每一个服务是一个独立的产品,要有独立的团队进行开发、运维和部署。而实际上,这样成本会十分高。有时候,由于人员投入不足,一个团队维护多个业务微服务系统也是常见的,这时就需要考虑业务和团队的协作问题了,需要进行合理的分工和业务分配。
- 演进型:微服务的拆分不是一成不变的,它会随着时间的变化而变化。例如,刚开始,用户业务数据并不多,业务也相对单一,这个时候有一个用户服务就可以了。但是后续随着业务的深化,用户数据会急剧膨胀,在业务划分上也会更精细化,会将用户分为高级用户和普通用户管理,这时就可以考虑将原有的用户服务拆分为普通用户服务和高级用户服务两个服务了。所以在设计的时候,需要考虑未来可能的细化方向。
- 避免循环依赖和双向依赖:微服务应该避免循环依赖,一个业务不能同时由两个系统维护,必须有清晰的边界。例如,很多时候产品和财务是关联的,有时候财务需要按照产品维度出报表,这里需要明确的是,产品表只能在产品服务内维护,而财务需要产品的信息,需要有明确的接口和同步时间界限,以避免财务的内容去维护产品的内容,造成数据的混乱。
微服务的拆分规则并不是平等的,应该以业务拆分为第一原则,进行划分,界定清楚边界,提供少量的服务接口供外部调用,同时应该考虑实际的情况,如需求的细化程度、数据量、团队拥有的资源、未来的预期和硬件情况等,实施微服务。
1.2、微服务的设计原则
通过服务划分,可以得到各个单一功能的服务。紧接着着就要设计系统了,在微服务系统的设计中,会考虑以下原则:
- 高可用性:高可用性是微服务设计的第一原则,也就是尽可能给予反馈。任何一个服务都应该至少有2个实例,任何一个实例出现故障,都可以被微服务系统发现,并且微服务系统可以通过自我修复排除故障节点,尽可能保证微服务能够持续稳定地提供给用户服务。
- 伸缩性:对于快速膨胀、数据不断增加的服务,我们可以根据需要增加服务实例。对于业务减少、活跃用户减少的服务,也可以根据需要适当减少服务实例。
- 容错性:微服务应该具备高容错性,在一些糟糕的环境下(如高并发),可以通过限流、熔断和服务降级来保证服务之间的故障不蔓延,保证各个服务能够尽可能响应用户,降低服务出现的差错。
- 去中心化:微服务不推荐遵从服务器,而是推荐去中心化,任何一个服务实例都是平等的,或者按照一定的权重进行分配的。
- 基础设施自动化:可使用DevOps的理念进行开发和测试,也可使用容器(如Docker等)简化微服务的部署,使用这些工具可进一步简化开发、测试、部署和运维工作,使得工作更少,更加智能。
- 弱一致性:微服务不推荐使用强一致性,因为强一致性缓慢且复杂。弱一致性则相对简单,在分布式中能够做到简单就相当不易了。
- 性能:微服务推荐的是使用REST风格的请求来暴露服务接口,让各个服务能够通过服务调用来完成交互,共同完成业务。但是REST风格缓慢,在处理高并发场景的时候,还需要考虑使用其他的技术(如远程调用),以满足性能的需要。
- 可监控:服务实例都是可以监控的,出现故障可以及时发现,并且提示运维人员进行维护。
1.3、微服务架构
微服务的架构,如下图所示:
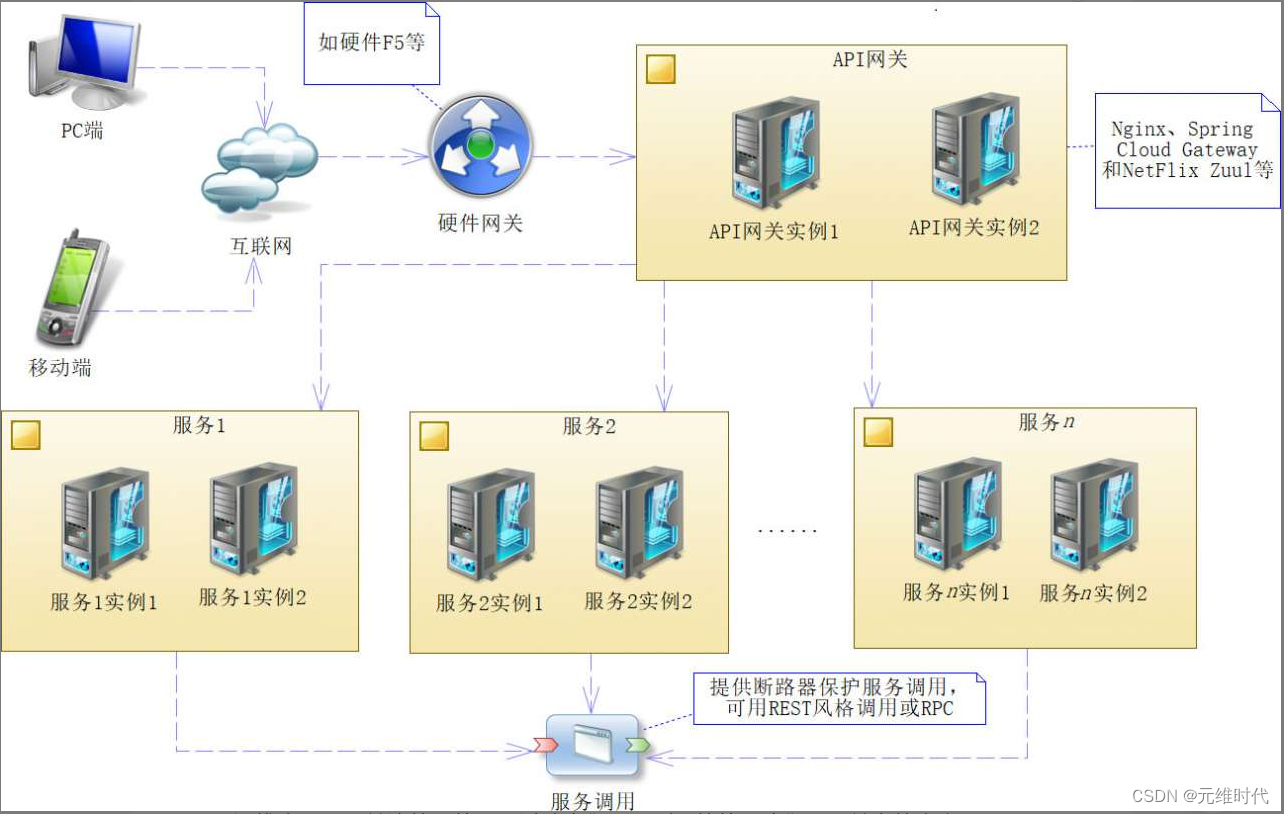
上图是一张比较复杂的图,所以省去了服务治理中心。事实上,所有的服务和对应的API网关都应该将其信息注册到服务治理中心。严格来说,图中的客户端(PC端和移动端)、互联网和硬件网关都不属于软件工程师关注的范围,这些是网络和运维人员需要关注的,就不再讨论它们了。剩下的就是我们需要关心的内容了。
- API网关:API网关可以实现路由、限流和降级的功能。例如,我们可以使用介绍过的Netflix Zuul或者Spring Cloud Gateway进行路由,也可以使用Resilience4j限速器或者Zuul插件进行限流,控制服务的流量。
- 服务和其实例:服务是根据服务拆分方法得到的一个独立的产品,它有明确的业务规则、边界和接口。服务是由多个实例来完成的,多个实例可以满足高可用和高性能的需求。
- 服务调用:各个服务通过服务调用来完成企业的业务。在一般情况下,我们可以使用基于REST风格的服务调用(如Ribbon和OpenFeign),它具备更高的可读性和独立性,但是性能不高,如果需要提升性能的,还可以考虑远程调用(RPC)技术,但是在一般情况下,需要考虑使用断路器(Hystrix或者Resilience4j)对服务调用进行保护,以避免出现雪崩效应,导致服务最终失败。
2、高并发系统的一些优化经验
应该说,有很多种设计高并发的方法,但是没有权威的方法,所以以下分析主要是基于我的经验。从大的方向来说,在高并发处理中要考虑以下4点:
- 提高性能:也就是单个服务,能够越快响应请求越好,这样在同一个单位时间内,响应的用户就越多,吞吐量也越大。
- 保证服务高可用:因为高并发意味着短时间的大流量,服务所承受的压力会远远大于平时的情况,可能出现线程占满、缓存溢出和队列溢出等情况,导致服务失败。
- 用户友好:即便内部出现问题,有些服务不可用,也要及时将请求结果(包括不成功)反馈给用户,保证用户对网站的忠诚度。常见的双十一电商网站会提示“小二正忙”。
- 增加和升级硬件:假如原来有2台服务器,现在使用5台来提供服务,并且再通过算法合理调整,那么性能就可以显著提高。或者使用性能更好的另外2台服务器来代替,也可以获得更好的性能。
用户友好,是即使出现不成功的情况时,也需要注意如何提示用户的问题,相对来说比较简单,只要将请求指向一个静态资源即可。同样,增加和升级硬件也是比较简单的,这些本章不再论述。这里需要谈的是提高性能和服务可用这两点。
2.1、提高性能
提高性能的手段,当前主要集中在数据库技术、缓存技术、动静分离和服务调用的方法上,下面让我们分别进行讨论。
2.1.1、数据库优化
数据库优化是最常见的优化方式,但在软件工程中,主要的优化来自3个方面:索引、SQL和锁。因为在互联网中广泛使用了MySQL,所以以下的讨论都会以MySQL数据库进行说明。为了更好地进行讨论,我们先来构建一个简单的模型,如下图所示:
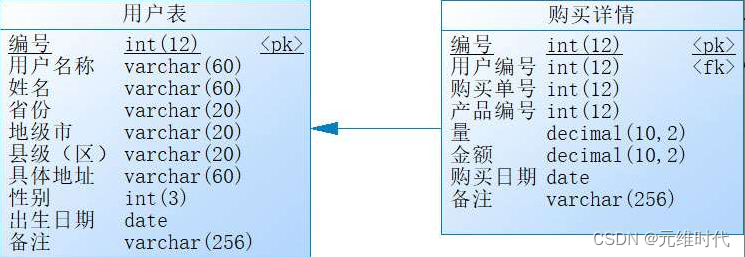
# 用户表
create table T_USER
(
id int(12) not null auto_increment,
user_name varchar(60) not null,
full_name varchar(60) not null,
province varchar(20) not null,
city varchar(20) not null,
county varchar(20) not null,
address varchar(60) not null,
sex int(3) not null default 0,
birthday date not null,
note varchar(256),
primary key (id)
);
# 购买详情表
create table t_purchasing_details
(
id int(12) not null,
user_id int(12) not null,
order_id int(12) not null,
product_id int(12) not null,
quantity decimal(10,2) not null,
amount decimal(10,2) not null,
purchase_date date not null,
note varchar(256),
primary key (id)
);
有了这两张表,下面来讨论索引和SQL优化。
数据库索引实际类似一个目录,当我们打开一本书籍时,如果需要快速找到所需内容,最直观的方法就是在目录中查找,找到对应的页码,就能找到我们感兴趣的内容了。同样,通过数据库的索引,就能够快速找到数据的地址,从而达到快速查询的目的,但是索引也有许多需要我们注意的地方。
既然索引可以快速找到数据,那么索引是否越多越好呢?答案当然是否定的,通过索引可以快速找到数据,但是在做数据写入(增删改)的时候,也需要维护索引,所以索引越多写入速度也就越慢,维护索引的开销也越大,同时索引也是需要消耗存储空间的。实际上,也不是什么场景都需要索引,对于数据量较少的表,就不需要加入索引了。一般来说,表主要是考虑在常用的检索字段上添加索引,每表索引应该在5个以下,索引只需要满足大部分的查询即可,而不是全部查询。下面我们先给用户表和购买详情表加入索引,如代码清单如下所示:
# ********** 创建索引 ********** #
# 用户表的用户名称,这是一个唯一索引
create unique index user_name_idx on T_USER(user_name);
# 用户表的区域索引,这是一个复合索引
create index area_idx on T_USER(province, city, county);
# 购买详情表的用户编号索引
create index user_id_idx on t_purchasing_details(user_id);
# 购买详情表的订单编号索引
create index order_id_idx on t_purchasing_details(order_id);
# 购买详情表的产品编号索引
create index product_id_idx on t_purchasing_details(product_id);
# 购买详情表的购买日期索引
create index purchase_date_idx on t_purchasing_details(purchase_date);
索引的有多种分法,例如,按存储地址区分的聚簇索引和非聚簇索引;按算法区分的位图索引、B+树索引;按索引涉及表的列数可区分为单列索引和复合索引,等等。限于篇幅,这里只讨论单列索引和复合索引,其中单列索引是指的一个索引只针对表的一个列,而复合索引则是一个索引针对多个列。对于索引列来说,尽量不要存在空值,有必要时可以使用默认值。对于复合索引的建立,尽量不要超过3列,因为列过多会造成索引复杂化,算法复杂,导致性能低下,提升维护索引的代价。此外,还要注意复合索引的使用,例如,用户表的区域索引存在一个索引有3个字段,即省份(province)、地级市(city)和县级(county)。如果SQL写成以下这样就不会启用索引:
select * from T_USER u where u.city = '广州' and u.county='天河'
这里的问题是缺少了省份,也就是对于复合索引来说,第一个列出现才会使用索引。例如,以下SQL都会使用索引:
# 缺少地级市
select * from T_USER u where u.province = '广东省' and u.county='天河';
# 缺少县级市
select * from T_USER u where u.province = '广东省' and u.city='广州';
只要出现了复合索引的第一列(例子里是province),就可以使用复合索引了。如果没出现,查询就不会使用索引,这是在复合索引的使用中需要注意的。此外,我们还需要注意一些索引失效的场景,下面通过举例进行说明。
# 索引字段模糊查询,第一个不为匹配符时,启用索引
select * from t_user u where u.user_name like '张%';
# 索引字段模糊查询,第一个为匹配符时,不启用索引
select * from t_user u where u.user_name like '%四';
# 在索引列加入运算函数时,不启用索引
select * from t_purchasing_details where DATE_FORMAT(purchase_date,'%Y-%m-%d')>'2019-08-08';
# 使索引列做空值判断时,不启用索引
select * from T_USER u where u.province is null and u.county='天河';
# 使用or关键字时,不启用索引
select * from t_user u where (u.province = '广东省' or u.province='江苏省') ;
# 使用不等号 “!=”或者“<>”时,不启用索引
select * from t_user u where u.province != '广东省' ;
以上就是一些使用索引的误区,此外,还会存在多种索引同时作为查询条件的陷阱。例如,下面这条SQL:
select * from t_purchasing_details
where purchase_date='2019-08-08' and user_id = 1;
这条SQL同时使用了购买日期和用户编号两个索引,那么在SQL中会用哪个索引呢?在MySQL中,采用的算法是B+树,所以在索引的选择上,它采用的是从左原则,也就是哪个索引出现在先,就采用哪个索引,因此这里将采用购买日期为索引进行查询。但是采用购买日期查询,如果单日购买数量多,显然索引的区分度就不大,通过索引得到的数据还是很多,做进一步无索引的筛选速度就慢;而采用用户进行区分,区分度往往会远远大于使用日期,这样筛选得到的数据就少许多,做进一步无索引的排查速度就快。因此应该修改这条SQL语句,改造成使用用户编号作为索引进行筛选数据在先,代码如下:
select * from t_purchasing_details
where user_id = 1 and purchase_date='2019-08-08';
应该说,只是介绍了一些索引常用的知识,还有很多需要读者再进行学习的。数据库除了使用索引外,还需要考虑SQL算法优化的问题,下面进行说明。例如,查询没有购买过商品的用户编号,很多初学者就会写成这样:
select u.id from t_user u
where u.id not in (select pd.user_id from t_purchasing_details pd);
这条SQL的意思是,先通过子查询找到购买详情表里的所有用户编号,然后再和用户表对比,找到没有购买商品的用户编号。事实上,使用子查询,会降低性能,应该考虑使用关联查询提高性能,因此修改如下:
select u.id from t_user u left join t_purchasing_details pd
on u.id = pd.user_id where pd.user_id is null;
为了找到没有购买商品的用户,这里使用了外连接中的左连接来关联两张表,然后通过on关键字指定了关联字段,设置了“判断购买详情表的用户编号是否为null”的查询条件。这里的最大特色是,将子查询修改为了连接查询,提升了SQL的性能。对于not in和not exists这样的查询,都应该考虑使用外连接去优化。
此外还有常用的UNION ALL和UNION的用法和区别,应该说,UNION ALL的性能会优于UNION,这是因为UNION会合并相同的记录,而UNION ALL则不会。例如,下面的SQL:
# 不会合并相同的记录,性能高
select u.id from t_user u
union all
select pd.user_id from t_purchasing_details pd;
# 会合并相同的记录,因为需要对比,所以性能低
select u.id from t_user u
union
select pd.user_id from t_purchasing_details pd;
除了使用索引和优化SQL外,我们还需要考虑锁的问题,尤其是在写入数据的时候。例如,下面的语句:
update t_purchasing_details set purchase_date = now() where order_id =1;
表面看上去,只是将订单编号为1的购物详情的购买时间修改为当前时间,但是当服务并发高了之后,很快就会出现性能的瓶颈。为什么会这样呢?这是因为在MySQL中,因为order_id是一个非主键的索引,所以在执行更新的时候,它就会加入表锁,将整个表锁定,这样在并发的时候,其他的SQL访问t_purchasing_details表时就需要等待了。为了解决这个问题,可以考虑先执行:
select id from t_purchasing_details where order_id =1;
找到对应的编号后,再通过id作为参数,使用下面的语句更新数据:
update t_purchasing_details set purchase_date = now() where id in (......);
这样的好处是,使用了主键更新,当使用主键更新的时候,MySQL加入行锁,只是锁定需要更新的数据,而其他的数据并不会被锁定,这样就可以避免全表锁定,从而提高并发了。
2.1.2、使用缓存
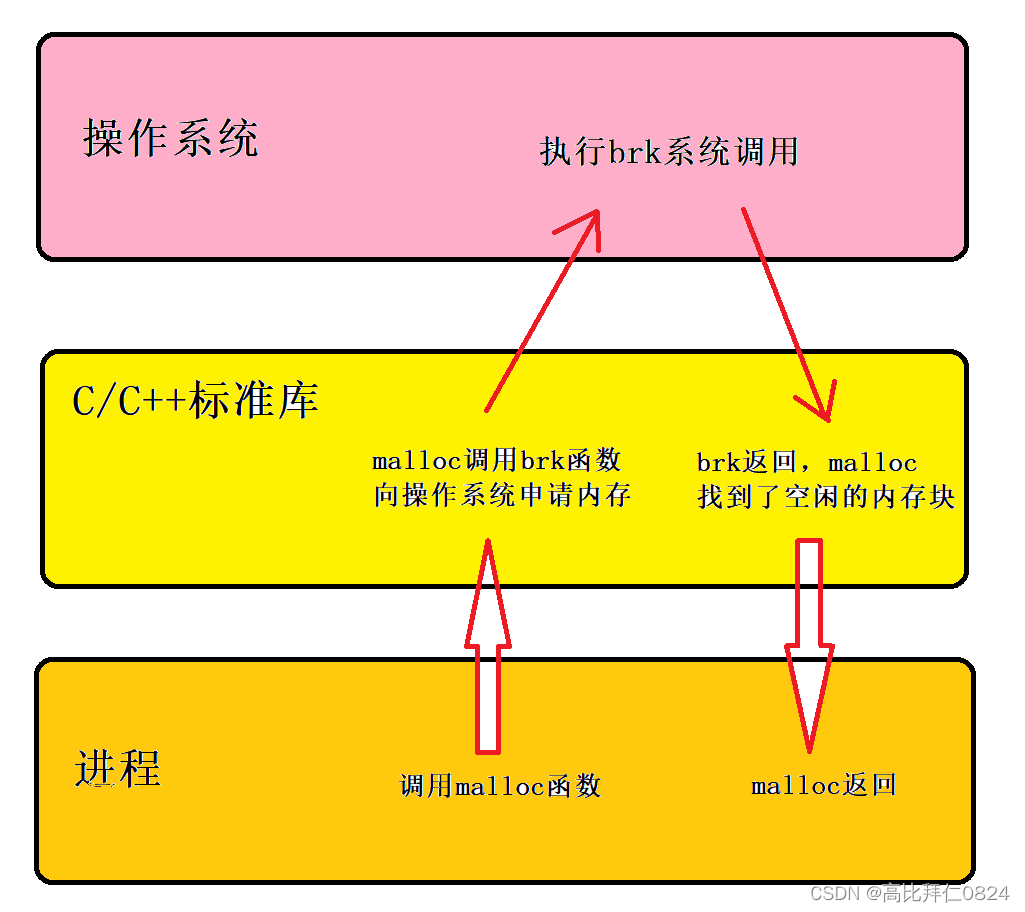
为了提高性能,很容易就会让人联想到缓存。缓存一般是将数据存放在内存中,而数据库的数据却存放在磁盘中,内存的速度是磁盘的几倍到几十倍,所以如果大部分的数据是从内存读取,就能够显著提升性能。
2.1.3、服务调用优化
在单机上,每一个线程的执行都是快速的,但当我们使用REST风格的调用的时候,因为传输数据多,且需要较多的校验,所以会导致调用十分缓慢影响性能。为了解决这个问题,可以考虑用远程调用(RPC)去代替REST风格的调用,这样可以数倍提升服务调用的性能。此外还有使用异步的形式处理高并发的,下面进行介绍。
无论何种服务调用,都需要通过网络调用完成,而这个过程是缓慢的。为了解决这个问题,我们可以使用异步的形式来处理,为了更好地介绍它的原理,先给出图示:
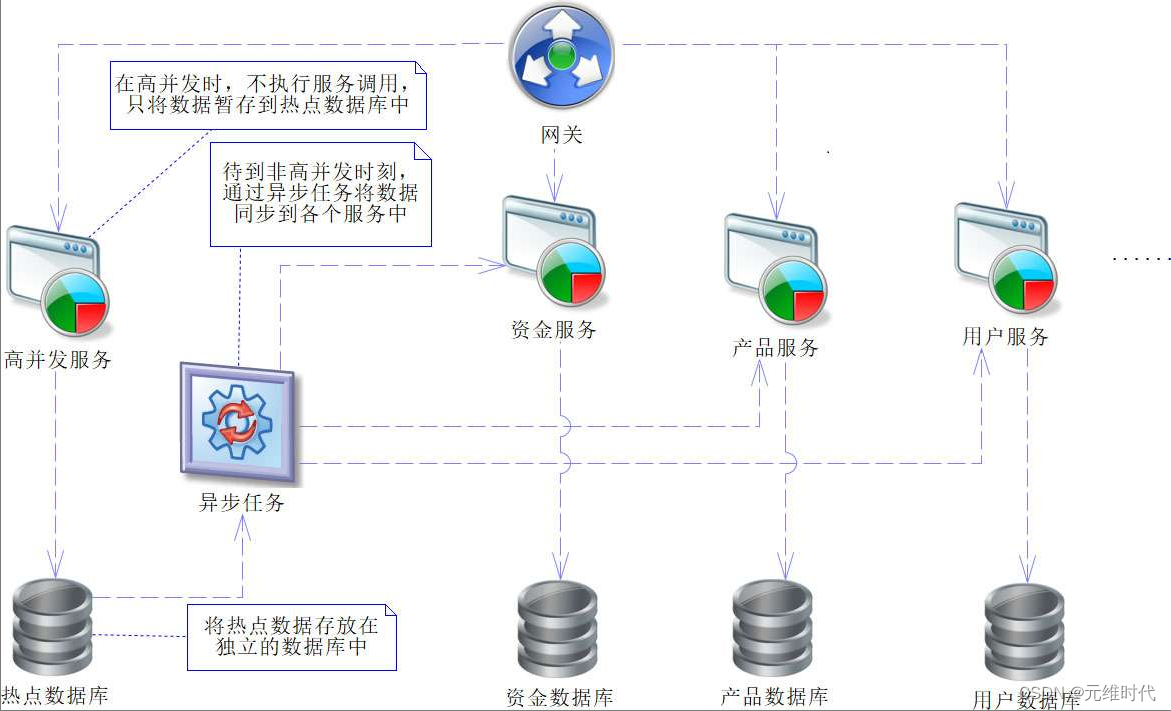
异步任务的原理是利用数据的不等价性,注意这里所说的不等价,是指数据被访问的频率,按此区分,必然会存在热点数据和冷门数据。进一步再分析,可以发现,在大部分情况下,高并发请求会集中在这些热点数据上,因此可以将热点数据先存放到热点数据库中单独处理,而冷门数据采用原有的服务调用即可,毕竟并发的可能性并不高。当到达高并发时段时,如果请求的是热点数据,就通过网关将请求路由到高并发服务上,但该服务只是暂存此次请求数据,并不执行任何服务调用,执行完成后响应用户,这时就可以避免因为服务调用带来的性能丢失了。在等待一段时间,系统高并发时段过去之后,再将热点数据,通过异步任务同步到各个服务中。
只是这样的方式会需要一个独立的服务系统去撑起高并发,而不再使用服务调用,相对容易实现,但是也需要付出更多的硬件成本。这样的隔离属于硬件隔离,对于高并发,我们只需要优化对应的系统即可,毕竟经过隔离后独立且清晰。此外,如果高并发引发服务器雪崩,那么只会让高并发服务系统崩溃,而正常的服务还可以继续使用,因此具备一定的高可用性。
2.1.4、动静分离
动静分离是指将内容拆分为动态(需要根据具体的请求分析)内容和静态(不需要具体的请求分析)内容。因为动态内容需要分析和处理数据,所以涉及数据的运算,一般来说会比较慢;而静态部分是不需要做分析和处理的,所以请求静态部分速度会更快,直接展示数据即可。一个好的网站往往会做动静分离,将服务拆分开来,为服务优化奠定后续基础。对于静态内容,如HTML、JavaScript、CSS和图片等文件,可以放在静态的HTTP服务器上,如典型的Nginx和Apache HTTP Server,都可以作为高效的HTTP静态服务器。对于那些需要优化的动态内容,可以放到Tomcat、Jetty之类的Java Web容器中。
在新的互联网技术中还有一种技术,可以更加有效地提高静态数据的访问,那就是内容分发网络(Content Delivery Network,CDN)。CDN技术主要是发挥网络节点的作用,企业会将其最常被访问的静态内容发送到CDN的各个节点,例如将静态内容放到北京、上海和广州的CDN节点上。这样用户就可以进行就近访问了,如下图所示:
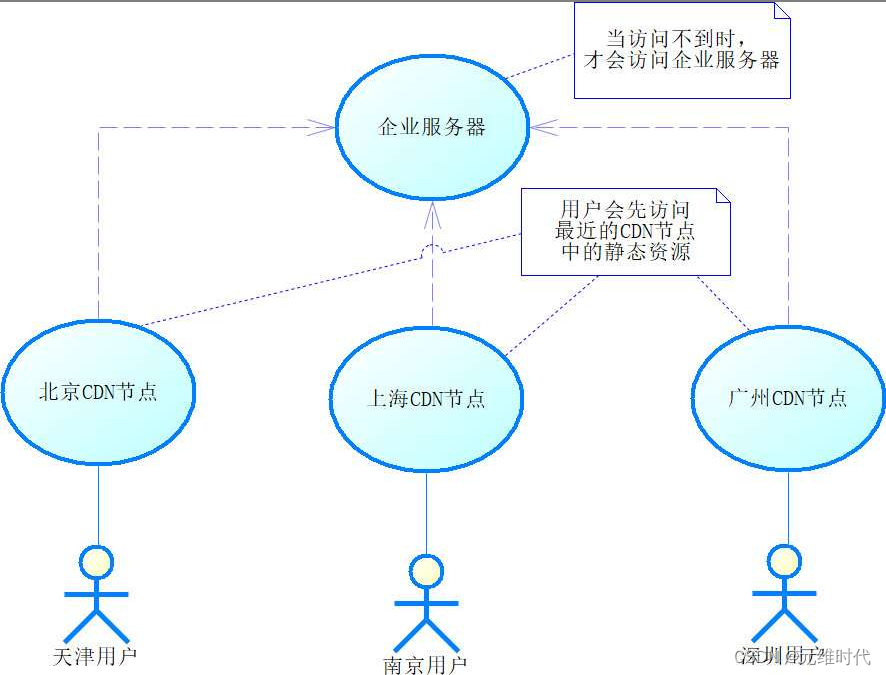
从上图中可以看出,用户在访问一个网站时,首先会访问就近的CDN节点存储的静态内容,例如深圳用户访问的是广州的CDN节点,因为距离近,加上资源是静态的,所以加载和传输的速度都会十分快,能极大地提升用户的体验。
只有当CDN节点没有内容或者内容需要动态计算的时候,才去访问企业的真实服务器。当然,访问企业真实服务器的速度相对较慢,所以需要常常访问的静态内容,最好还是制作成静态内容放到各地的CDN节点。我们熟悉的新浪、搜狐和网易等门户网站,它们首页上包含的信息量实际上是很多的,但是响应速度也很快,利用的就是这个原理。
2.1.5、数据库读写分离
一般来说,数据库也会提供复制的功能,例如MySQL就提供一种主从数据的架构,如下图所示。
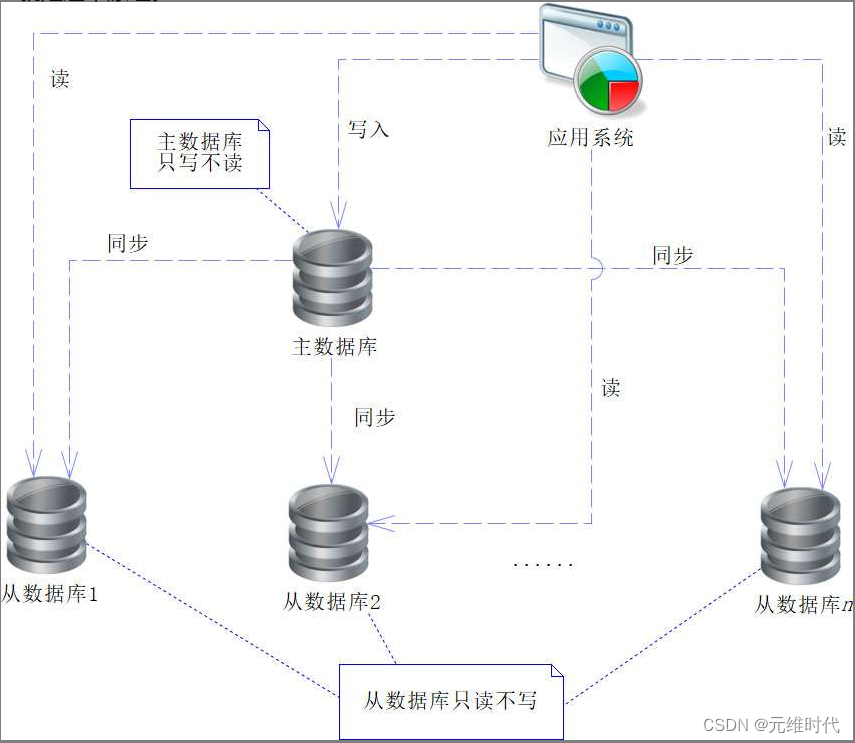
根据上图,我们将服务应用分为写入和读取两个维度进行说明。先谈写入维度,首先服务应用将数据写入主数据库,然后主数据库通过网络将数据同步到从数据库(可有多个节点),这样从数据库就有主数据库的数据了。再谈读取维度,服务应用只从从数据库中读取数据。从上述的两个维度可以看到,主数据库只写不读,从数据库只读不写,这样就可以进行读写分离了。读写分离可以降低主数据库的压力。从多台从数据库中读取数据,能更有效地分摊压力。
但是主从结构也出现一些问题(如写入压力大)的时候,同步数据可能会不及时,或者写入后需要快速读出的时候,读出的数据也可能不同步。这些都需要考虑限制流量,以防同步数据过大,造成不及时的问题。对于用户的读写,也可以考虑增加一些时间间隔,给同步数据留出时间。
2.2、服务高可用
在提高性能方面,我们主要解决了请求响应速度的问题,但是还没有处理另外一个问题,那就是如何保证服务的可用性。当出现高并发的时候,随时会出现服务不可用,可能会导致系统可用性降低,我们知道,评价服务效果的第一要素就是可用性。因此,在高并发出现各种不稳定因素时,我们也需要考虑使用一定的技术手段,保证服务的可用性。目前流行的方法有限流和服务降级、隔离术、网关过滤和断路器,下面让我们一一进行讨论。
2.2.1、限流和服务降级
限流和服务降级是高并发最常用的技术之一,它可以控制单位时间请求的流量,避免过多的请求流量压垮后端服务器。这里以Spring cloud Gateway结合Resilience4j为例进行说明。
新建模块ms-gateway,然后加入以下依赖。
<!-- 依赖Spring Cloud Gateway -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- resilience4j Spring Boot Starter依赖,
它会依赖circuitbreaker、ratelimiter和consumer模块 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot2</artifactId>
<version>0.13.2</version>
</dependency>
<!-- Alibaba Fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.59</version>
</dependency>
这里引入了Spring Cloud Gateway、Resilience4j和Alibaba Fastjson,这样就可以通过Resilience4j的限速器来限制网关的流量了。跟着我们配置application.yml文件,如代码清单如下所示。
# resilience4j 限速器(ratelimiter)配置
resilience4j:
# 限速器注册机
ratelimiter:
limiters:
# 名称为commonLimiter的限速器
commonLimiter:
# 时间戳内限制通过的请求数,默认值为50
limitForPeriod: 2000
# 配置时间戳,默认值为500 ns
limitRefreshPeriodInMillis: 1000
# 超时时间
timeoutInMillis: 100
# 服务器端口
server:
port: 2001
# 路由配置
spring:
cloud:
gateway:
# 开始配置路径
routes:
# 路径匹配
- id: demo
# 转发URI
uri: http://localhost:3001
filters:
- StripPrefix=1
# 断言配置
predicates:
# 请求方法为GET
- Path=/demo/**
这里先配置了一个命名为commonLimiter的限速器,跟着将启动端口配置为2001,最后配置了路由。这个例子会路由到http://localhost:3001/test上,所以需要提供另外一个服务,这比较简单,我就不再提供相关的代码了。
为了限制请求的速度,我们需要开发一个Gateway的全局过滤器,为此,我们将Spring Boot启动类MsGatewayApplication修改为代码清单如下:
package com.spring.cloud.ms.gateway.main;
/**** imports ****/
@SpringBootApplication
public class MsGatewayApplication {
// 注入Resilience4j限流器注册机
@Autowired
private RateLimiterRegistry rateLimiterRegistry = null; // ①
// 创建全局过滤器
@Bean("limitGlobalFilter")
public GlobalFilter limitGlobalFilter() {
// Lambda表达式
return (exchange, chain) -> {
// 获取Resilience4j限速器
RateLimiter userRateLimiter
= rateLimiterRegistry.rateLimiter("commonLimiter");
// 绑定限速器
Callable<ResultMessage> call // ②
= RateLimiter.decorateCallable(userRateLimiter,
() -> new ResultMessage(true, "PASS") );
// 尝试获取结果
Try<ResultMessage> tryResult = Try.of(() -> call.call()) // ③
// 降级逻辑
.recover(ex -> new ResultMessage(false, "TOO MANY REQUESTS"));
// 获取请求结果
ResultMessage result = tryResult.get();
if (result.isSuccess()) { // 没有超过流量
// 执行下层过滤器
return chain.filter(exchange);
} else { // 超过流量
// 响应对象
ServerHttpResponse serverHttpResponse = exchange.getResponse();
// 设置响应码
serverHttpResponse.setStatusCode(HttpStatus.TOO_MANY_REQUESTS);
// 转换为JSON字节
byte[] bytes = JSONObject.toJSONString(result).getBytes();
DataBuffer buffer
= exchange.getResponse().bufferFactory().wrap(bytes);
// 响应体,提示请求超流量
return serverHttpResponse.writeWith(Flux.just(buffer));
}
};
}
class ResultMessage {
// 通过成功标志
private boolean success;
// 信息
private String note;
public ResultMessage() {
}
public ResultMessage(boolean success, String note) {
this.success = success;
this.note = note;
}
/**** setters and getters ****/
}
public static void main(String[] args) {
SpringApplication.run(MsGatewayApplication.class, args);
}
}
在代码①处,注入了resilience4j-spring-boot2为我们创建的Resilience4j的限速器,通过它就可以获取我们配置好的限速器了。limitGlobalFilter方法是我们的核心逻辑,它先获取配置的限速器。跟着,在代码②处将限速器绑定到具体的逻辑里,返回一个成功的ResultMessage对象。然后,在代码③处尝试获取结果,并且绑定服务降级逻辑,如果执行服务降级,就返回一个失败的ResultMessage对象。最后,根据获取的结果来判定是否超速,如果未超速,则执行限速器的下一步逻辑,否则返回超速的信息。这里如果超速了,还会返回对应的超速信息,以提示前端做对应的动作。提供有效的提示,可以提高用户的体验。
2.2.2、隔离术
隔离术是处理高并发高的一种常用方法。严格来说,之前谈到的动静分离也是隔离术的一种——动静隔离术。应该说,隔离方法有很多种,如集群隔离、线程隔离、机房隔离、爬虫隔离和热点隔离等。一般来说,隔离分为物理隔离和逻辑隔离两大类。物理隔离主要是通过不同的硬件进行隔离,例如,机房隔离就是一种物理隔离。逻辑隔离主要是按照业务逻辑、数据类型等逻辑维度的需要进行隔离,甚至可以将多种逻辑隔离结合在同一台机器上。其实对于逻辑隔离,我们之前也讨论过,例如,Hystrix的线程池和Resilience4j的舱壁隔离(Bulkhead),都是典型的线程隔离术的实现方法。在服务调用优化中,我们谈到的热点数据也是根据数据类型进行的隔离术,我们可以称其为热点隔离术。
隔离术可以将某项业务独立出来,当这项业务出现故障不可用时,其他与之无关的业务依旧可用。这样就很方便了,对于已经隔离的业务,可以进行独立的调优和其他处理。显然,隔离术大大提供了系统的可用性和灵活性,所以在分布式中,隔离术也是被广泛使用的技术之一。
虽然隔离术拥有很多种类型,但是目前最主要的还是线程隔离。数据类型隔离和机房隔离等主要是系统设计上的考量,是架构师需要考虑的问题。对于线程隔离术,Hystrix和Resilience4j都支持,其中Hystrix只需要进行配置即可,但是作为即将被Spring Cloud移除的技术,这里就不再进行深入讨论了。下面从Resilience4j的角度进行说明。为了使用Resilience4j的隔离术,我们首先需要在Maven中引入舱壁模式,代码如下:
<!-- 引入Resilience4j舱壁模式 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
<version>0.13.2</version>
</dependency>
引入舱壁之后,就可以使用Resilience4j的舱壁隔离了,下面我们通过代码进行演示,代码清单如下所示:
package com.spring.cloud.ms.gateway.rest;
/**** imports ****/
public class BulkheadMain {
// 舱壁隔离配置
private static BulkheadConfig bulkheadConfig = null;
// 初始化舱壁配置
private static BulkheadConfig initBulkheadConfig() {
if (bulkheadConfig == null) {
// 舱壁配置
bulkheadConfig = BulkheadConfig.custom()
// 最大并发数,默认值为25
.maxConcurrentCalls(20)
/* 调度线程最大等待时间(单位毫秒),默认值为0,
如果存在高并发的场景,强烈建议设置为0,
如果设置为非0,那么在高并发的场景下,
可能导致线程积压的后果*/
.maxWaitTime(0)
.build();
}
return bulkheadConfig;
}
// 舱壁注册机
private static BulkheadRegistry bulkheadRegistry;
// 初始化舱壁注册机
private static BulkheadRegistry initBulkheadRegistry() {
if (bulkheadConfig == null) { // 初始化
initBulkheadConfig();
}
if (bulkheadRegistry == null) {
// 创建舱壁注册器,并设置默认配置
bulkheadRegistry = BulkheadRegistry.of(bulkheadConfig);
// 创建一个命名为test的舱壁
bulkheadRegistry.bulkhead("test");
}
return bulkheadRegistry;
}
public static void main(String[] args) {
initBulkheadRegistry(); // 初始化
RestTemplate restTemplate = new RestTemplate();
// 获取舱壁
Bulkhead bulkhead = bulkheadRegistry.bulkhead("test");
String url = "http://localhost:3001/test";
// 描述事件 ①
CheckedFunction0<String> decoratedSupplier
= Bulkhead.decorateCheckedSupplier(
bulkhead, () ->
restTemplate.getForObject(url, String.class));
// 尝试
Try<String> result = Try.of(decoratedSupplier)
.recover(ex -> { // 降级服务
ex.printStackTrace();
return "服务调用失败";
});
// 发送请求
System.out.println(result.get());
}
}
在代码中,initBulkheadConfig方法是初始化舱壁配置(BulkheadConfig),设置了线程数为20,等待时间为0ms。注意,这里设置为0ms的等待时间,意味着得不到线程分配的请求就会快速失败,执行降级逻辑,提示用户。倘若等待时间不为0,则会存放在队列中,在高并发的时候,如果存放在队列中,容易造成队列溢出,和请求长期得不到响应的结果,这显然对用户更不友好,因此推荐这里将等待时间配置为0ms。initBulkheadRegistry方法是创建一个舱壁注册机(BulkheadRegistry),在这个过程中,使用舱壁配置创建了一个名为“test”的舱壁。对于main方法,主要是使用RestTemplate进行服务调用,它先从舱壁注册机中获取“test”舱壁,然后在代码①处对服务调用和舱壁进行捆绑,这样就能够将该服务调用进行隔离了。
通过上述代码就可以让某项业务在一个独立的舱壁中运行了。如果这项业务发生故障,或者舱壁本身出现故障,显然只会损坏这项业务或舱壁本身,而不会危及整个服务,这样就可以有效控制系统的受损范围,提高服务的可用性了。此外,对于舱壁线程池长期不满的情况,可以调小并发线程数,对于舱壁线程不足的情况,也可以调大线程数,这体现了线程隔离的灵活性,支持对某项业务单独优化。
2.2.3、网关过滤
网关过滤也是常用的处理高并发的技术之一,通过它可以区分请求的有效性。判断请求是否有效的办法,常见的有这么几种:验证码(如图片验证码、短信验证码和拖动验证码等)、用户黑名单、限制用户单位时间戳的请求数、实名制、区分僵尸用户和IP封禁等。虽然这些判断可以放在网关进行,但是网关一般不进行复杂的业务逻辑判断,并且需要注意性能的问题。推荐使用缓存技术对一些请求进行简易快速的判断,尽可能避免使用数据库,因为数据库的性能较低,会影响到全局的性能。通过这些简单快速的判断,能避免大量的无效请求来到后端服务器,从而保护应用。
对于验证码来说,现今图片验证码已经比较少使用了,因为当前存在大量的图片识别软件,所以取而代之的是短信验证码和拖动验证码等方式,这样就可以避免图片识别软件自动补齐验证码进行大量请求。用户黑名单指的是系统内部发现常常攻击网站的用户,对于它们进行区分对待。可以考虑将黑名单保存到缓存中,如Redis,然后通过用户名判断是否为黑名单用户,如果是则进行拦截,这样就可以避免它们的请求路由到后端服务器了。限制用户单位时间戳的请求数也是常用的方法,例如,限制用户1分钟只能进行3次购买操作,这样就可以避免恶意刷请求,限制用户操作的频度了。当然,这些操作记录也可以存放到Redis中,以便于快速判定。对系统实现实名制,对于涉及账户和商品操作的系统,可以考虑实名制,处理一名多户的情况,从而压制不合理的注册,减少恶意刷请求的可能性。系统内还有些僵尸用户,所谓僵尸用户是指平时不上线,只是偶尔上线,但它们在一些关键时刻,如春运抢票,就开始大量购买,然后高价倒卖黄牛票。对于这样的僵尸用户,应该进行区分,在关键时刻限制它们购买的票数。IP封禁是指封禁在某个网段进行频繁请求的IP,但使用IP封禁可能会误伤正常用户,所以在使用时应该慎重一些。
为了更好地说明,我们以用户黑名单为例进行说明。首先需要引入Redis的依赖,代码如下:
<!-- 加入Spring Boot的Redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<!--排除同步Redis客户端Lettuce-->
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--加入Redis客户端Jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
紧跟着需要在application.yml文件中增加Redis部分的配置,如代码清单如下所示:
hset blacklist user1 1
这里,“blacklist”是一个哈希结构的名称,“user1”是用户名,“1”表示是黑名单用户,这样黑名单就可以保存在哈希结构中了。为了在网关拦截黑名单用户,可以在Spring Boot的启动文件中添加一个全局拦截器,如代码清单如下所示:
@Autowired // 注入StringRedisTemplate对象
private StringRedisTemplate stringRedisTemplate = null;
@Bean(name = "blacklistFilter")
public GlobalFilter blacklistFilter() {
return (exchange, chain) -> {
String username = exchange.getRequest(). // 获取请求参数
getQueryParams().getFirst("username");
// 如果参数为空,则不执行过滤逻辑
if (StringUtils.isEmpty(username)) {
return chain.filter(exchange);
}
String value = (String)stringRedisTemplate.opsForHash()
.get("blacklist", username); // 获取黑名单用户信息
// 不存在或者标志为0,则为正常用户,放行
if (StringUtils.isEmpty(value) || "0".equals(value)) {
return chain.filter(exchange);
} else { // 是黑名单用户,则拦截请求
// 响应对象
ServerHttpResponse serverHttpResponse = exchange.getResponse();
// 设置响应码(禁止请求)
serverHttpResponse.setStatusCode(HttpStatus.FORBIDDEN);
ResultMessage result
= new ResultMessage(false, "黑名单用户,请联系客服处理");
// 转换为JSON字节
byte[] bytes = JSONObject.toJSONString(result).getBytes();
DataBuffer buffer
= exchange.getResponse().bufferFactory().wrap(bytes);
// 响应体,提示请求黑名单用户,禁止请求
return serverHttpResponse.writeWith(Mono.just(buffer));
}
};
}
代码首先注入了StringRedisTemplate对象,这个对象是spring-boot-starter-data-redis自动装配的。跟着是blacklistFilter方法,它读取用户名的请求参数,然后在Redis中查询是否存在,如果存在且不为黑名单用户,则放行,如果为黑名单用户,则进行拦截,返回拦截原因,表明是黑名单用户。为了验证黑名单的功能,我们可以在浏览器中请求地址http://localhost:2001/demo/test?username=user1,可以看到下图所示的界面了。
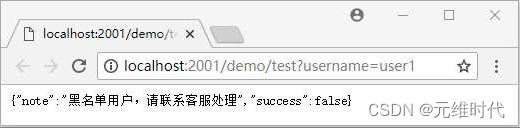
这样,通过网关的拦截器,就可以拦截黑名单用户了。此外,还可以根据自己业务的需要,添加对应的过滤功能,例如,限制单位时间戳内用户请求的次数,从而避免用户的恶意攻击。
2.2.4、断路器
在介绍Hystrix时,我们谈到过因服务依赖引发的服务器雪崩现象,在高并发时,更容易产生这个现象,因此,往往还需要使用断路器,保护那些可能引发问题的服务调用。关于断路器,本书谈过Hystrix和Resilience4j两种,这里采用Resilience4j进行介绍。为此,先对断路器进行配置,如代码清单如下所示:
resilience4j:
# 配置断路器,配置的断路器会注册到断路器注册机(CircuitBreakerRegistry)中
circuitbreaker:
backends:
# 名称为test的断路器
test:
# 当断路器处于关闭状态时,监测到环形数组有多少位信息时,
# 重新分析请求结果,确定是否改变断路器的状态
ring-Buffer-size-in-closed-state: 10
# 当断路器处于打开状态时,监测到环形数组有多少位信息时,
# 重新分析请求结果,确定是否改变断路器的状态
ring-buffer-size-in-half-open-state: 10
# 当断路器处于打开状态时,等待多少时间(单位毫秒),
# 转变为半打开状态,默认为60秒
wait-duration-in-open-state: 5000
# 当请求失败比例达到30%时,打开断路器,默认为50%
failure-rate-threshold: 30
# 是否注册metrics监控
register-health-indicator: true
关于配置的内容,可以参考代码中的注释,这里就不再赘述了。有了配置,就可以在应用中使用断路器了。为此,新建控制器CircuitBreakerController,其内容如代码清单如下所示:
package com.spring.cloud.ms.gateway.controller;
/**** imports ****/
@RestController
public class CircuitBreakerController {
// 断路器注册机 ①
@Autowired
private CircuitBreakerRegistry circuitBreakerRegistry = null;
@GetMapping("/test")
public String test() {
// 从断路器注册机中获取“test”断路器
CircuitBreaker testCircuitBreaker
= circuitBreakerRegistry.circuitBreaker("test");
String url = "http://localhost:3001/test";
RestTemplate restTemplate = new RestTemplate();
// 描述事件并和断路器捆绑到一起 ②
CheckedFunction0<String> decoratedSupplier =
CircuitBreaker.decorateCheckedSupplier(
testCircuitBreaker,
()-> restTemplate.getForObject(url, String.class));
// 发送事件
Try<String> result = Try.of(decoratedSupplier)
// 如果发生异常,则执行降级方法
.recover(ex -> "产生了异常"); // ③
// 返回结果
return result.get();
}
}
先看一下代码①处,它主要是注入resilience4j-spring-boot2,为我们自动装配断路器注册机。核心是test方法,它首先从断路器注册机获取“test”断路器。然后在代码②处描述事件,并且将断路器绑定在一起。最后发送事件,在代码③处定义降级方法。通过这样就可以保护服务调用了。
3、简易的微服务实例
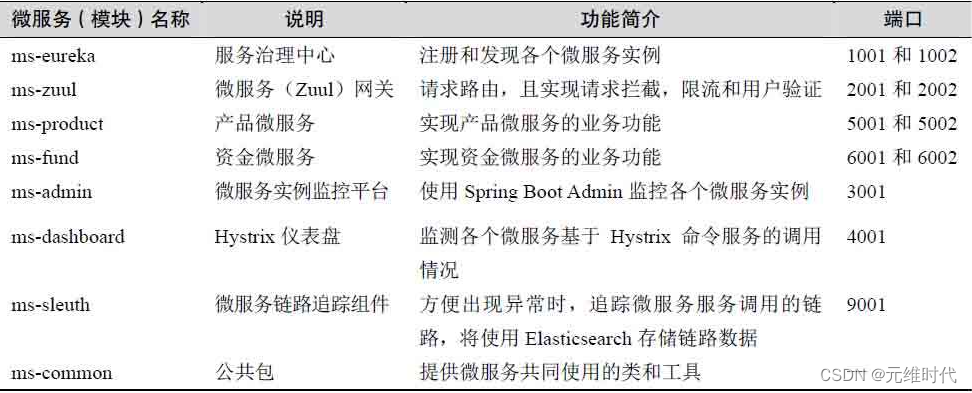
要搭建微服务系统,应该先从大的架构设计开始,然后再落实到细节,所以先让我们来看实例的架构图,如下图所示:
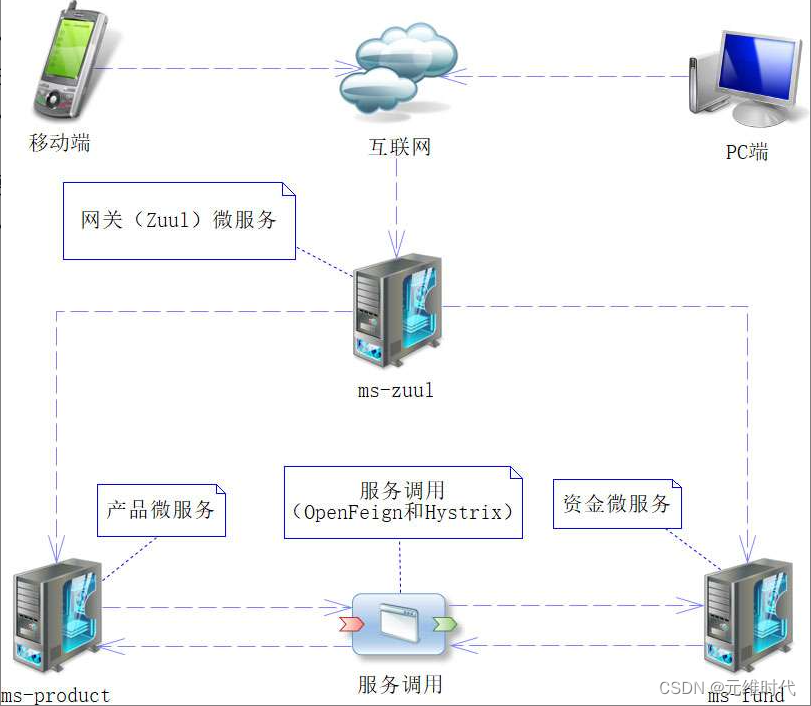
上图的架构还是比较简单的,并且很多辅助的微服务模块也没有画出来,这些辅助的模块包括:服务发现(ms-eureka)、Spring Boot Admin监控平台(ms-admin)、Hystrix断路器仪表盘(ms-dashboard)和服务追踪组件(ms-sleuth)。为了更好地理解它们,这里将它们的功能罗列出来,如下表所示: