- 背景
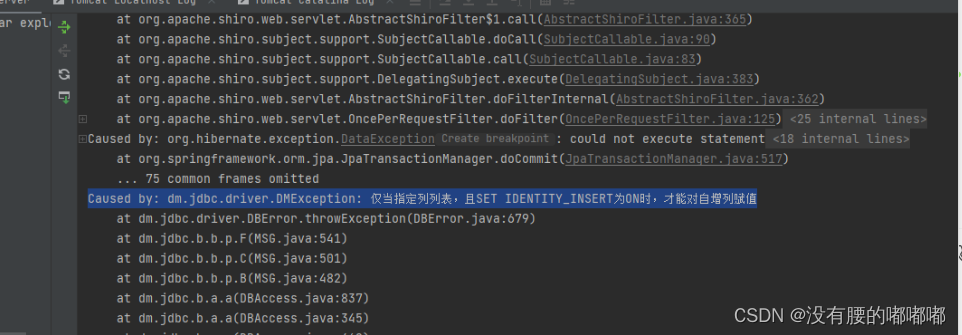
想要了解CUDA并行计算原理,同时针对深度学习中出现一些“不支持算子”可能需要手写的需要,配置一个简单的CUDA编译环境,探索CUDA编程的范式【注:CUDA环境配置略】。 - 结果展示
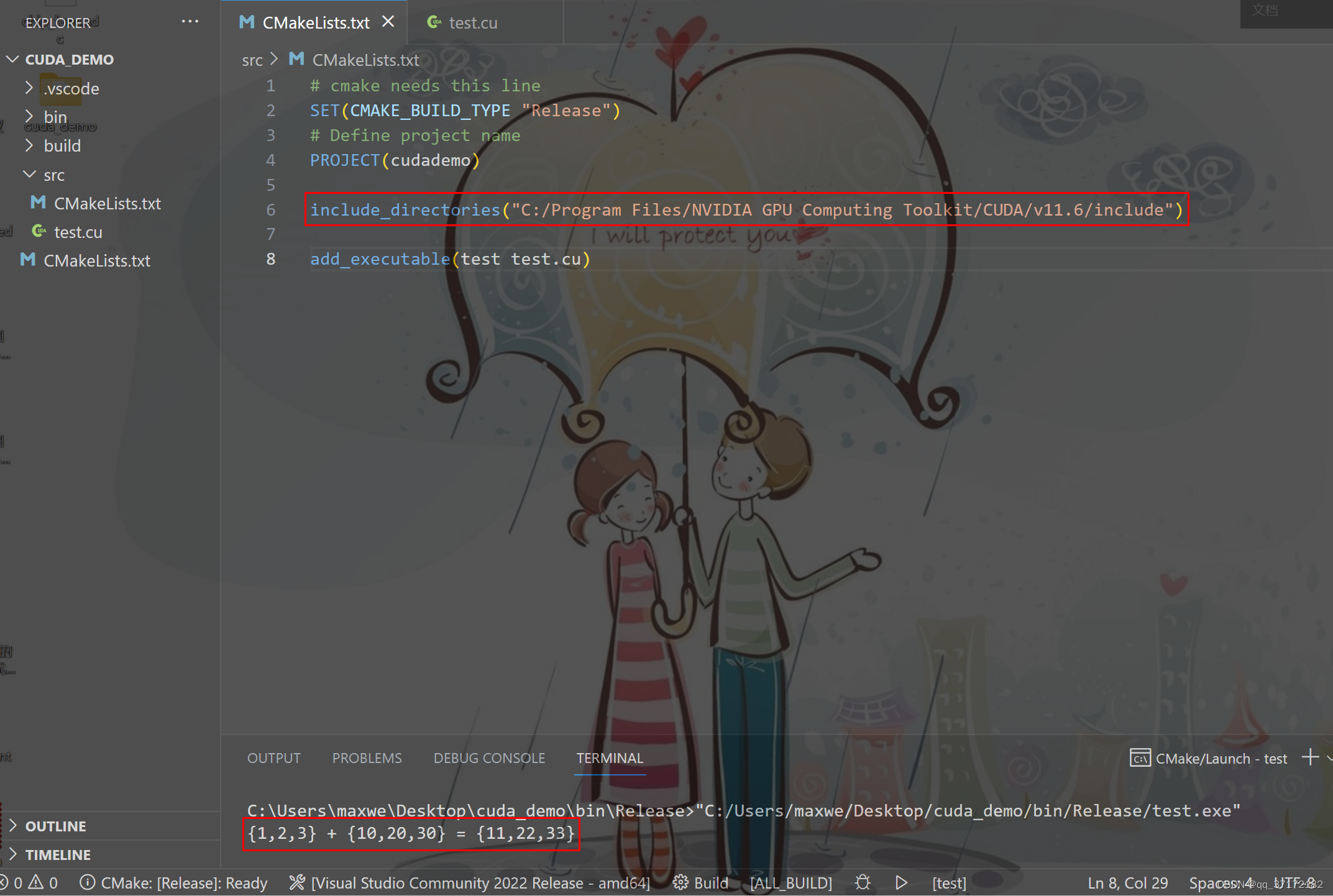
- 示例代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
__global__ void VecAdd(int* A, int* B, int* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
void test_cuda(){
const int size = 3;
int a[size] = { 1,2,3 };
int b[size] = { 10,20,30 };
int c[size] = { 0 };
int* dev_a = 0;
int* dev_b = 0;
int* dev_c = 0;
cudaError_t cudaStatus;
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "GPU device error");
return;
}
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess)
fprintf(stderr, "device_c allocate error");
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess)
fprintf(stderr, "device_a allocate error");
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess)
fprintf(stderr, "device_b allocate error");
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "device_a copy error");
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "device_b copy error");
}
VecAdd <<<1, size>>> (dev_a, dev_b, dev_c);
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "VecAdd call error: %s\n", cudaGetErrorString(cudaStatus));
}
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize not sucess %d!\n", cudaStatus);
}
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "copy result to host error");
}
printf("{1,2,3} + {10,20,30} = {%d,%d,%d}\n", c[0], c[1], c[2]);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}
int main() {
test_cuda();
return 0;
}
- 小结
- NVCC编译cuda命令与g++编译C++较为相似,从而借鉴引入对应的include,实现Windows下cmake编译CUDA代码;
- 示例代码展示了从CPU读取数据,在GPU端进行计算,最终传输给CPU的过程,与深度学习数据加载过程类似,是较为通用的过程;
- 理解C++到CUDA的过渡、预加载过程,进一步从底层了解CUDA。