前言:Hello大家好,我是小哥谈。EfficientNetV2是一个网络模型,旨在提供更小的模型和更快的训练速度。它是EfficientNetV1的改进版本。EfficientNetV2通过使用更小的模型参数和采用一种称为Progressive Learning的渐进学习策略来实现这一目标。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
YOLOv5算法改进(7)— 添加SimAM注意力机制
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
YOLOv5算法改进(10)— 替换主干网络之GhostNet
目录
🚀1.论文
🚀2.EfficientNetV2详细解析
🚀3.YOLOv5结合EfficientNetV2
💥💥步骤1:在common.py中添加EfficientNetV2模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
EfficientNetV2是一种由Google AI开发的深度学习网络架构,它是在EfficientNet之上的一个改进版本,于2021年4月发表于 CVPR 。EfficientNetV2在保持与其他网络结构相同的准确率的情况下,可以显著减少网络的参数量和计算量,这使得EfficientNetV2在移动设备和嵌入式设备上更加高效。EfficientNetV2使用了一种叫做“模型缩放”的技术来自动调整网络的深度、宽度和分辨率,从而在保持准确率的同时最大限度地减少参数和计算量。EfficientNetV2在多个领域的图像分类任务中都取得了出色的结果。🌴
论文中给出的EfficientNetV2的性能参数如下图所示:

通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。在EfficientNetV1中作者关注的是准确率、参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。🌱

论文题目:《EfficientNetV2: Smaller Models and Faster Training》
论文地址: https://arxiv.org/abs/2104.00298
代码实现: https://github.com/google/automl/tree/master/efficientnetv2
🚀2.EfficientNetV2详细解析
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
🍀(1)训练图像的尺寸很大时,训练速度非常慢。 这确实是个槽点,在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size。🐳

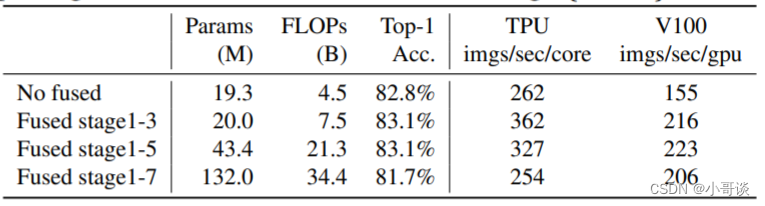
🍀(2)在网络浅层中使用Depthwise convolutions速度会很慢。 虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。🐳
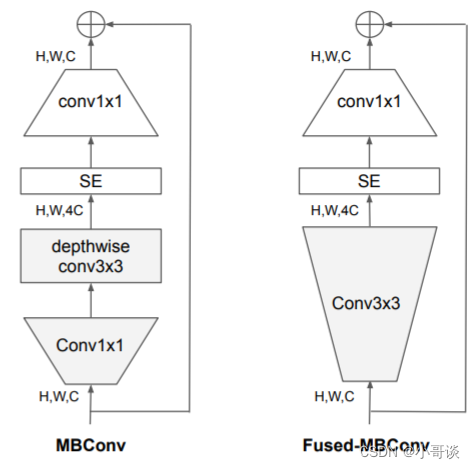
🍀(3)同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。🐳
通过论文可知,作者首先通过NAS搜索得到模型EfficientNetV2-S的架构。与EfficientNet的主干相比,EfficientNetV2主要有以下几个区别:
💞(1)EfficientNetV2在早期阶段使用上面新加的Fused-MBConv结构,在后期阶段使用MBConv结构。
💞(2)EfficientNetV2在MBConv结构中更喜欢使用较小的扩展率,因为较小的扩展率往往具有更小的内存访问开销。
💞(3)EfficientNetV2更喜欢使用较小的3*3尺寸的内核,但EfficientNetV2增加更多层来补偿较小内核导致的感受野的减少。
💞(4)EfficientNetV2完全删除了原始EfficientNet中的最后一个有MBConv结构的阶段,可能因为该阶段较大的参数大小和内存访问开销。
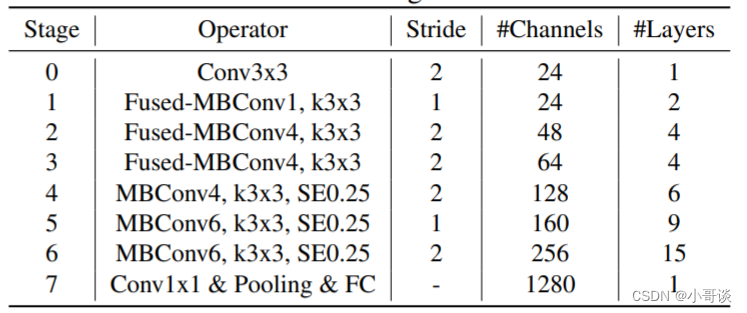
作者采用与EfficientNet相似的复合扩展策略来扩展EfficientNetV2-S来获得EfficientNetV2-M/L,并进行了一些额外的优化。
💞(1)将最大的推理图像大小限制为480,上面已经讲过非常大的图像通常会导致昂贵的内存和训练速度开销。
💞(2)在网络的后期阶段添加更多的层,以在不增加太多运算时开销的情况下增加网络容量。
本文主要贡献:
🍀(1)本文提出了EfficientNet V2,一个更小更快的模型,基于training-aware NAS和scaling,EfficientNetV2在训练速度和参数效率方面都优于之前的模型。
🍀(2)本文提出了一种改进的渐进式训练方法,它自适应的调整正则化和输入大小,通过实验证明该方法既加快了训练速度,同时也提高了准确性。
🍀(3)EfficientNetV2结合改进的渐进式训练方法,在ImageNet、CIFAR、Cars、Flowers数据集上,比之前的模型训练速度最高提升了11倍,参数效率最高提升了6.8倍。
🚀3.YOLOv5结合EfficientNetV2
💥💥步骤1:在common.py中添加EfficientNetV2模块
将下面EfficientNetV2模块的代码复制粘贴到common.py文件的末尾。
#EfficientNetV2
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
# kernel_size为3时,padding 为1,kernel为1时,padding为0
padding = (kernel_size - 1) // 2
# 由于要加bn层,所以不加偏置
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
# shorcut 是指到残差结构 expansion是为了先升维,再卷积,再降维,再残差
self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接
self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
self.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# 先用1x1的卷积增加升维
result = self.expansion_conv(x)
# 再用一般的卷积特征提取
result = self.dw_conv(result)
# 添加se模块
result = self.se(result)
# 再用1x1的卷积降维
result = self.project_conv(result)
# 如果使用shortcut连接,则加入dropout操作
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了
result += x
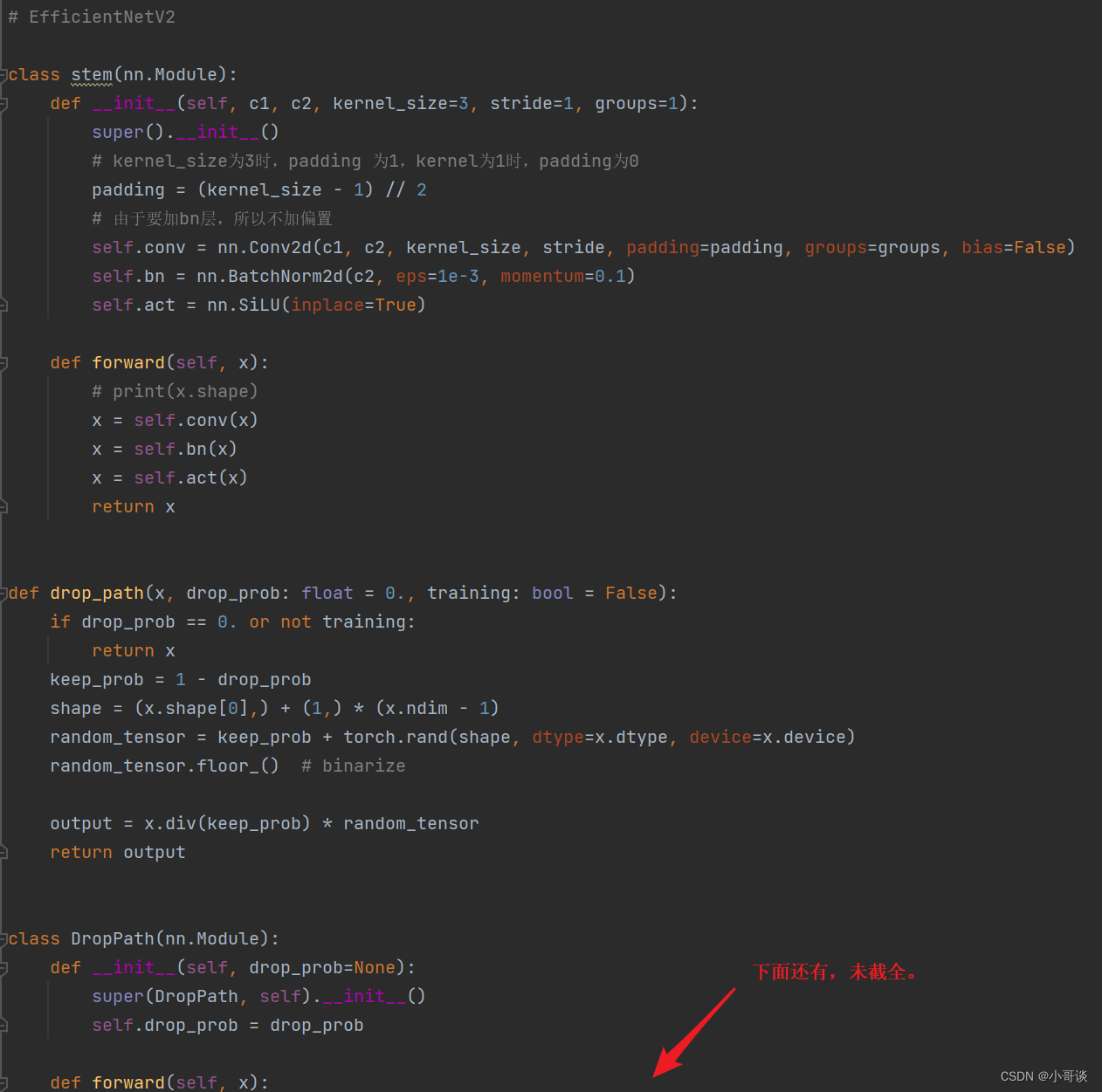
return result具体如下图所示:
💥💥步骤2:在yolo.py文件中加入类名
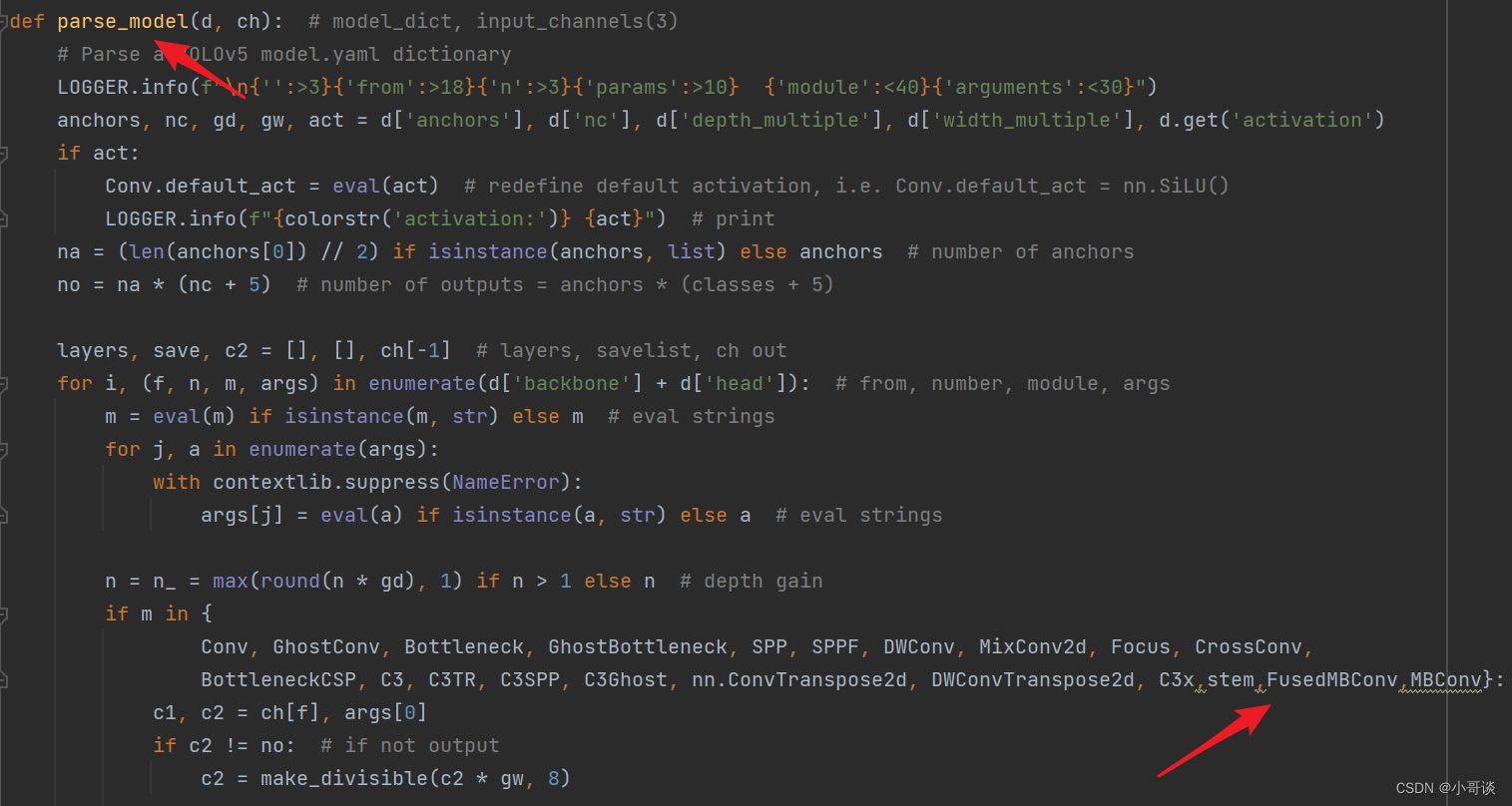
首先在yolo.py文件中找到parse_model函数这一行,加入stem、FusedMBConv、MBConv三个模块。
💥💥步骤3:创建自定义yaml文件
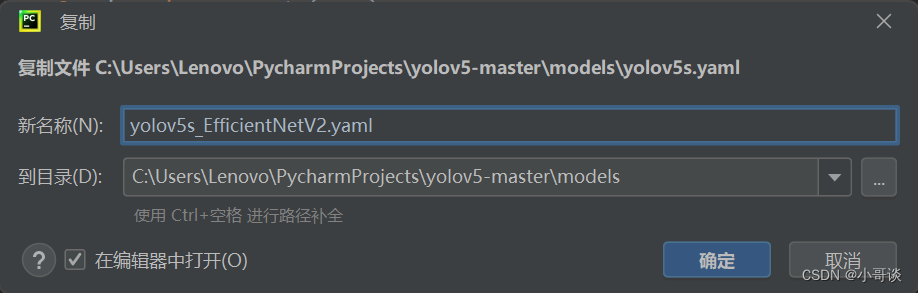
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_EfficientNetV2.yaml。
然后根据EfficientNetV2的网络架构来修改配置文件。

yaml文件修改后的完整代码如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, stem, [24, 3, 2]], #0 p1/2
[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1- last is use SE
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2-p2/4
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4-p3/8
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6-p4/16 last is use SE and ratio
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9
[-1, 1, MBConv, [272, 3, 2, 4, 0.25]], # 10-p5/64
[-1, 14, MBConv, [272, 3, 1, 4, 0.25]], # 11
[-1, 1, SPPF, [1024, 5]], #12
# [-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 13
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14
[[-1, 9], 1, Concat, [1]], # 15 cat backbone P4
[-1, 3, C3, [512, False]], # 16
[-1, 1, Conv, [256, 1, 1]], # 17
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 18
[[-1, 7], 1, Concat, [1]], # 19 cat backbone P3
[-1, 3, C3, [256, False]], # 20 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 21
[[-1, 17], 1, Concat, [1]], # 22 cat head P4
[-1, 3, C3, [512, False]], # 23 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 24
[[-1, 13], 1, Concat, [1]], # 25 cat head P5
[-1, 3, C3, [1024, False]], # 26 (P5/32-large)
[[20, 23, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_EfficientNetV2.yaml。
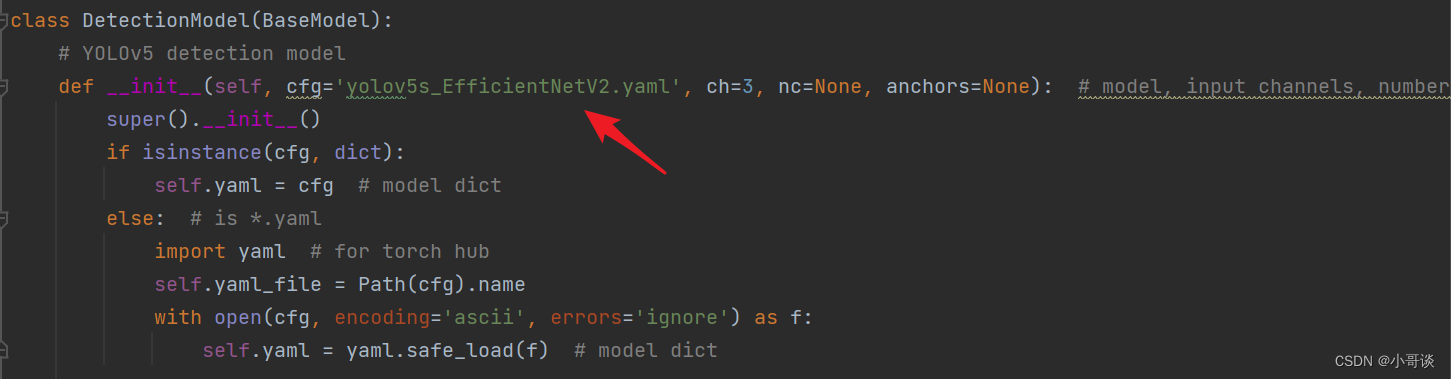
然后运行yolo.py,得到结果。

这样就算添加成功了。🎉🎉🎉
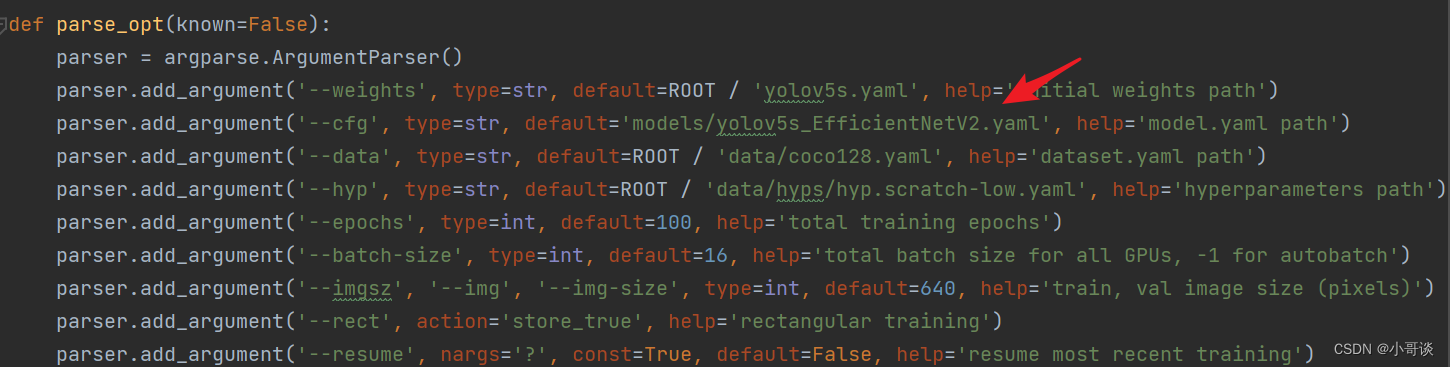
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_EfficientNetV2.yaml ',然后就可以开始进行训练了。🎈🎈🎈