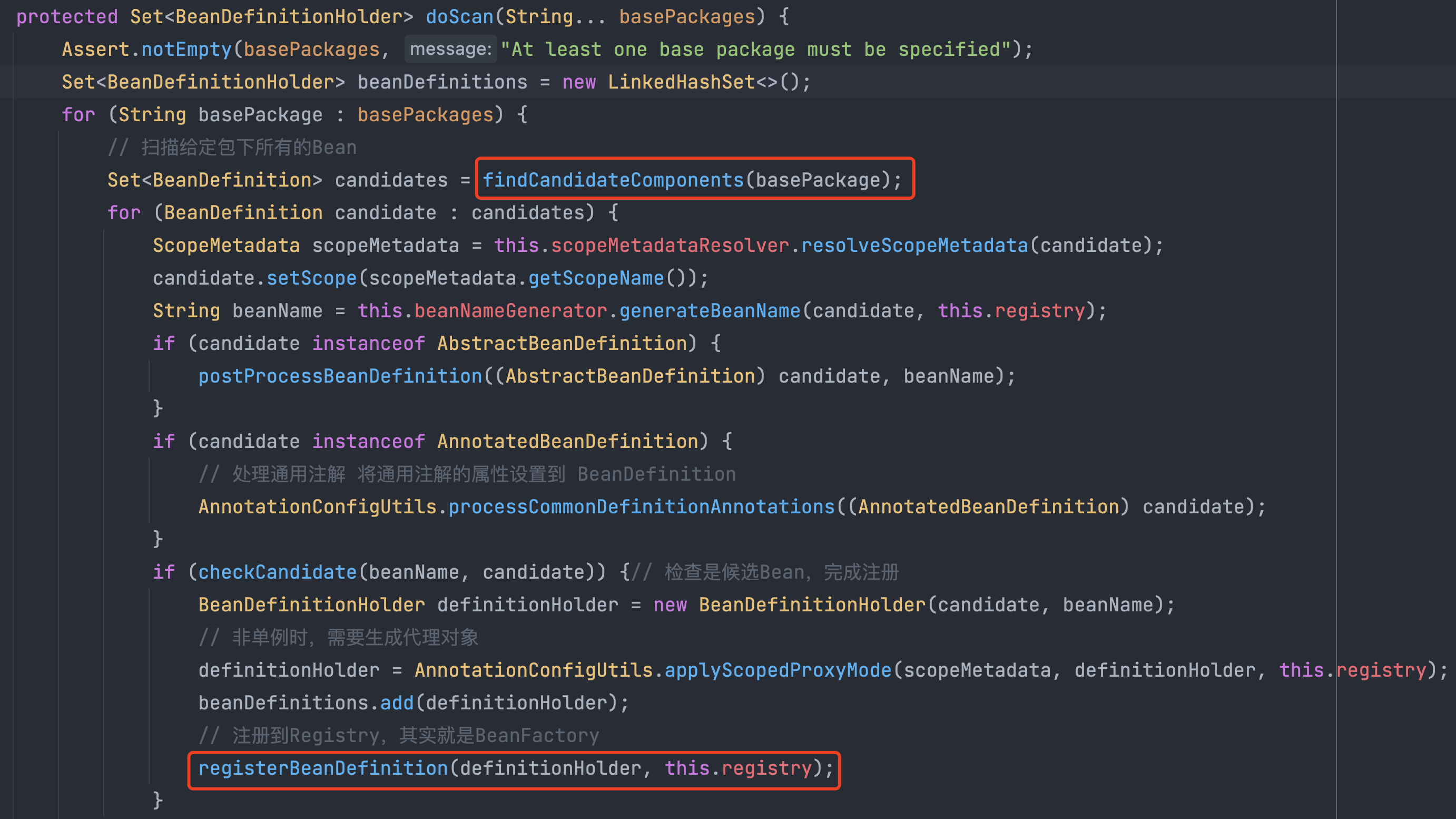
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
时间序列的共同属性
趋势
季节性
自相关
噪音
预测时间序列的技术
创建基线的朴素预测
衡量预测准确性
不那么天真:使用移动平均线进行预测
改进移动平均线分析
概括
时间系列无处不在。您可能在天气预报、股票价格和摩尔定律(图 9-1)等历史趋势中看到过它们。如果您不熟悉摩尔定律,它预测微芯片上的晶体管数量大约每两年翻一番。近 50 年来,它已被证明是未来计算能力和成本的准确预测指标。

图 9-1。摩尔定律
时间序列数据是一组随时间间隔的值。绘制时,x 轴通常是时间性的。通常在时间轴上绘制多个值,例如在这个例子中,晶体管的数量是一个图,摩尔定律的预测值是另一个图。这个称为多元时间序列。如果只有一个值(例如,一段时间内的降雨量),则称为单变量时间序列。
有了摩尔定律,预测就变得简单了,因为有一个固定而简单的规则可以让我们粗略地预测未来——这个规则已经存在了大约 50 年。
但是像图 9-2那样的时间序列呢?

图 9-2。真实世界的时间序列
虽然这个时间序列是人为创建的(您将在本章后面看到如何创建),但它具有复杂的现实世界时间序列的所有属性,如股票图表或季节性降雨。尽管看似随机,但时间序列具有一些共同属性,这些属性有助于设计可以预测它们的 ML 模型,如下一节所述。
时间序列的共同属性
虽然时间序列可能看起来随机且嘈杂,但通常有一些可预测的共同属性。在本节中,我们将探讨其中的一些。
季节性

图 9-3。网站流量
它是逐周绘制的,您可以看到有规律的下降。你能猜出它们是什么吗?本例中的站点是为软件开发人员提供信息的站点,正如您所料,它在周末的访问量较少!因此,时间序列具有五个高天和两个低天的季节性。数据是按几个月绘制的,圣诞节和新年假期大致在中间,因此您可以在那里看到额外的季节性。如果我把它绘制了几年,你会清楚地看到额外的年末下降。
季节性可以通过多种方式体现在时间序列中。例如,零售网站的流量可能会在周末达到峰值。
自相关
其他您可能会在时间序列中看到的特征是事件发生后出现可预测的行为。您可以在图 9-4中看到这一点,其中有明显的尖峰,但在每个尖峰之后,都会出现确定性衰减。这称为自相关。
在这种情况下,我们可以看到重复的一组特定行为。自相关可能隐藏在时间序列模式中,但它们具有内在的可预测性,因此包含许多自相关的时间序列可能是可预测的。

图 9-4。自相关
噪音

图 9-5。添加噪声的自相关序列
鉴于所有这些因素,让我们探讨如何对包含这些属性的时间序列进行预测。
预测时间序列的技术
在我们进入基于 ML 的预测(接下来几章的主题)之前,我们将探索一些更朴素的预测方法。这些将使您能够建立一个基线,您可以使用该基线来衡量 ML 预测的准确性。
创建基线的朴素预测
这预测时间序列的最基本方法是说时间t + 1 的预测值与时间t的值相同,有效地将时间序列移动一个周期。
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
def trend(time, slope=0):
return slope * time
def seasonal_pattern(season_time):
"""Just an arbitrary pattern, you can change it if you wish"""
return np.where(season_time < 0.4,
np.cos(season_time * 2 * np.pi),
1 / np.exp(3 * season_time))
def seasonality(time, period, amplitude=1, phase=0):
"""Repeats the same pattern at each period"""
season_time = ((time + phase) % period) / period
return amplitude * seasonal_pattern(season_time)
def noise(time, noise_level=1, seed=None):
rnd = np.random.RandomState(seed)
return rnd.randn(len(time)) * noise_level
time = np.arange(4 * 365 + 1, dtype="float32")
baseline = 10
series = trend(time, .05)
baseline = 10
amplitude = 15
slope = 0.09
noise_level = 6
# Create the series
series = baseline + trend(time, slope)
+ seasonality(time, period=365, amplitude=amplitude)
# Update with noise
series += noise(time, noise_level, seed=42)绘制此图后,您会看到类似图 9-6的内容。

图 9-6。显示趋势、季节性和噪声的时间序列
现在您有了数据,您可以像任何数据源一样将其拆分为训练集、验证集和测试集。当数据中存在一些季节性时,如您在本例中所见,拆分系列时最好确保每个拆分中都有整个季节。因此,举例来说,如果您想将图 9-6中的数据拆分为训练集和验证集,那么执行此操作的好地方可能是时间步长 1,000,为您提供直到步长 1,000 的训练数据和步长 1,000 之后的验证数据.
您实际上不需要在此处进行拆分,因为您只是在进行简单的预测,其中每个值t只是步骤t – 1 的值,但为了在接下来的几幅图中进行说明,我们将放大从时间步长 1,000 开始的数据。
要从分割时间段开始预测序列,您要分割的时间段在变量split_time中,您可以使用如下代码:
naive_forecast = series[split_time - 1:-1]图 9-7显示了覆盖朴素预测的验证集(从时间步长 1,000 开始,您可以将其设置split_time为1000)。
图 9-7。时间序列的朴素预测
它看起来非常好——值之间存在关系——而且,随着时间的推移绘制图表时,预测似乎与原始值非常接近。但是您将如何衡量准确性?
衡量预测准确性
那里衡量预测准确性的方法有很多种,但我们将集中讨论其中两种: 均方误差(MSE) 和 平均绝对误差(MAE)。
使用 MSE,您只需计算时间t的预测值与实际值之间的差值,将其平方(以去除负值),然后求出所有这些值的平均值。
使用 MAE,您可以计算时间t的预测值与实际值之间的差值,取其绝对值以去除负值(而不是平方),然后找到所有这些值的平均值。
对于您刚刚基于我们的合成时间序列创建的朴素预测,您可以像这样获得 MSE 和 MAE:
print(keras.metrics.mean_squared_error(x_valid, naive_forecast).numpy())
print(keras.metrics.mean_absolute_error(x_valid, naive_forecast).numpy())我得到了 76.47 的 MSE 和 6.89 的 MAE。与任何预测一样,如果可以减少误差,就可以提高预测的准确性。接下来我们将看看如何做到这一点。
不那么天真:使用移动平均线进行预测
这先前的朴素预测将时间t – 1 的值作为时间 t 的预测值。使用移动平均线是类似的,但它不是只从t – 1中取值,而是取一组值(比如 30),对它们进行平均,并将其设置为时间t的预测值。这是代码:
def moving_average_forecast(series, window_size):
"""Forecasts the mean of the last few values.
If window_size=1, then this is equivalent to naive forecast"""
forecast = []
for time in range(len(series) - window_size):
forecast.append(series[time:time + window_size].mean())
return np.array(forecast)
moving_avg = moving_average_forecast(series, 30)[split_time - 30:]
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, moving_avg)图 9-8显示了移动平均线与数据的关系图。

图 9-8。绘制移动平均线
当我绘制这个时间序列时,我得到的 MSE 和 MAE 分别为 49 和 5.5,因此它确实稍微改进了预测。但是这种方法没有考虑趋势或季节性,所以我们可以通过一些分析进一步改进它。
改进移动平均线分析
鉴于这个时间序列的季节性是 365 天,你可以使用一种叫做平滑趋势和季节性的技术 差分,它只是从 t 处的值减去t – 365 处的值。这将使图表变平。这是代码:
diff_series = (series[365:] - series[:-365])
diff_time = time[365:]您现在可以计算这些值的移动平均值并将过去的值加回去:
diff_moving_avg =
moving_average_forecast(diff_series, 50)[split_time - 365 - 50:]
diff_moving_avg_plus_smooth_past =
moving_average_forecast(series[split_time - 370:-360], 10) +
diff_moving_avg绘制此图时(参见图 9-9),您已经可以看到预测值有所改善:趋势线非常接近实际值,尽管噪音被消除了。季节性似乎在起作用,趋势也是如此。
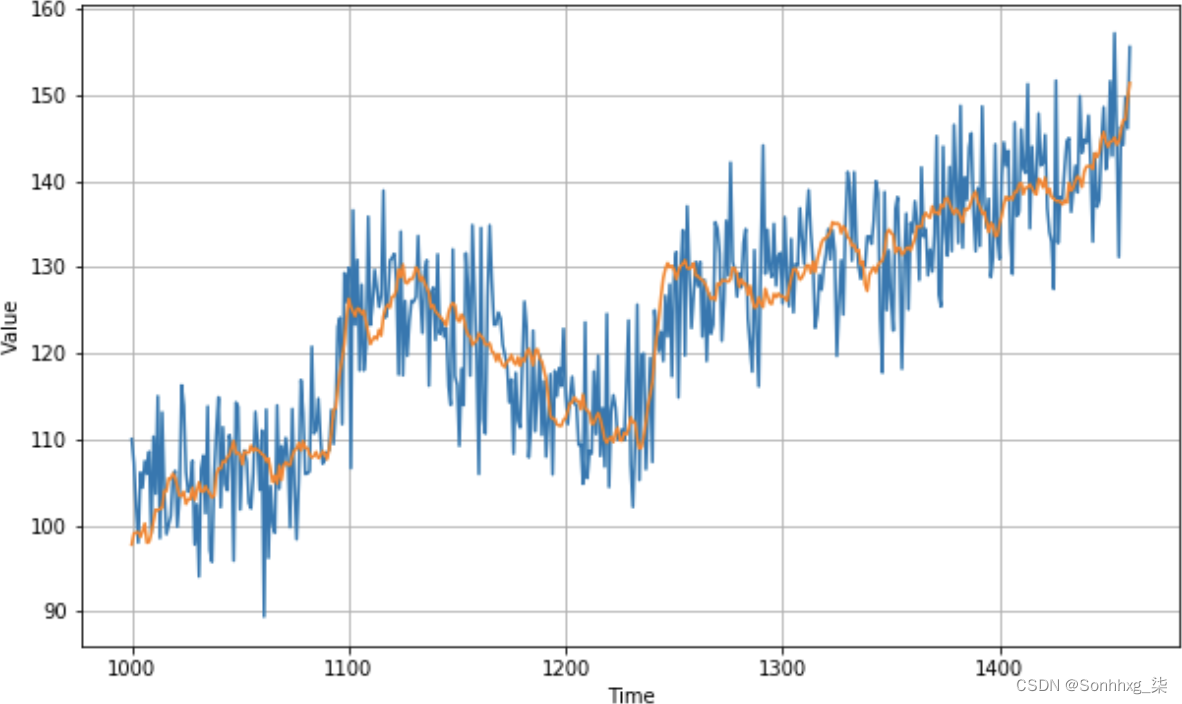
图 9-9。改进的移动平均线
这种印象通过计算 MSE 和 MAE 得到证实——在这种情况下,我分别得到 40.9 和 5.13,表明预测有明显改善。
概括
本章介绍了时间序列数据和时间序列的一些常见属性。您创建了一个综合时间序列,并了解了如何开始对其进行朴素预测。根据这些预测,您使用均方误差和平均误差建立了基线测量。这是对 TensorFlow 的一个很好的突破,但在下一章中,您将返回使用 TensorFlow 和 ML,看看是否可以改进您的预测!


![[内网渗透]—权限维持](https://img-blog.csdnimg.cn/347cb26470314bd6bd080853376864f4.png#pic_center)