目录
一、短路本地读取:Short Circuit Local Reads
1.1 背景
1.2 老版本的设计实现
1.3 安全性改进版设计实现
1.4 短路本地读取配置
1.4.1 libhadoop.so
1.4.2 hdfs-site.xml
1.4.3 查看 Datanode 日志
二、HDFS Block 负载平衡器:Balancer
2.1 背景
2.2 命令行配置
2.3 如何运行 Balancer
2.3.1 设置平衡数据传输带
2.3.2 运行 balancer
三、磁盘均衡器:HDFS Disk Balancer
3.1 背景
3.2 HDFS Disk Balancer 简介
3.3 HDFS Disk Balancer 功能
3.3.1 数据传播报告
3.3.1.1 Volume data density metric(卷数据密度)计算
3.3.1.2 Node Data Density 计算过程
3.3.2 磁盘平衡
3.4 HDFS Disk Balancer 开启
3.5 HDFS Disk Balancer 相关命令
3.5.1 plan 计划
3.5.2 Execute 执行
3.5.3 Query 查询
3.5.4 Cancel 取消
3.5.5 Report 汇报
四、纠删码技术:Erasure Coding
4.1 背景:3 副本策略弊端
4.2 Erasure Coding(EC)简介
4.3 Reed-Solomon(RS)码
4.4 Hadoop EC架构
4.5 Erasure Coding 部署方式
4.5.1 集群和硬件配置
4.5.2 纠删码策略设置
4.5.3 启用英特尔 ISA-L(智能存储加速库)
4.5.3.1 安装 yasm 和 nasm
4.5.3.2 编译安装isa-l-2.28.0
4.5.3.3 Hadoop 上检查是否启用 isa-l
4.5.4 EC 命令
一、短路本地读取:Short Circuit Local Reads
1.1 背景
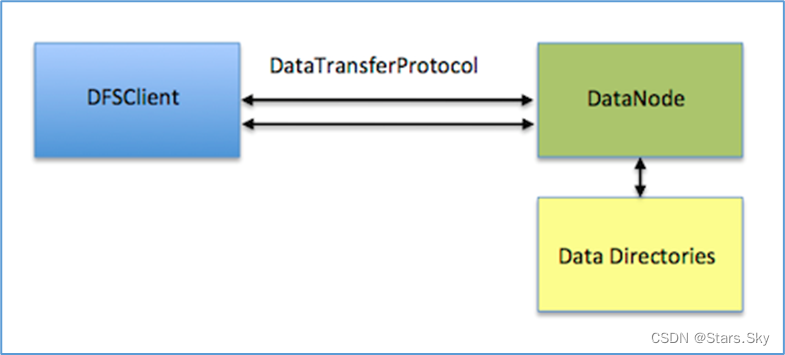
在 HDFS 中,不管是 Local Reads(DFSClient 和 Datanode 在同一个节点)还是 Reads(DFSClient 和 Datanode 不在同一个节点),底层处理方式都是一样的,都是先由 Datanode 读取数据,然后再通过 RPC(基于 TCP)把数据传给 DFSClient。这样处理是比较简单的,但是性能会受到一些影响,因为需要 Datanode 在中间做一次中转。
尤其 Local Reads 的时候,既然 DFSClient 和数据是在一个机器上面,那么很自然的想法,就是让 DFSClient 绕开 Datanode 自己去读取数据。所谓的“短路”读取绕过了 DataNode,从而允许客户端直接读取文件。显然,这仅在客户端与数据位于同一机器的情况下才可行。短路读取为许多应用提供了显着的性能提升。
 1.2 老版本的设计实现
1.2 老版本的设计实现
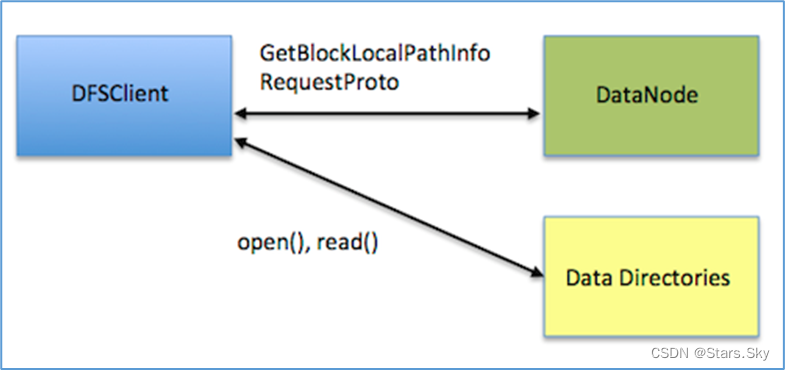
HDFS-2246 这个 JIRA 中,工程师们的想法是既然读取数据 DFSClient 和数据在同一台机器上,那么 Datanode 就把数据在文件系统中的路径,从什么地方开始读(offset)和需要读取多少(length)等信息告诉 DFSClient,然后 DFSClient 去打开文件自己读取。
想法很好,问题在于配置复杂以及安全问题。
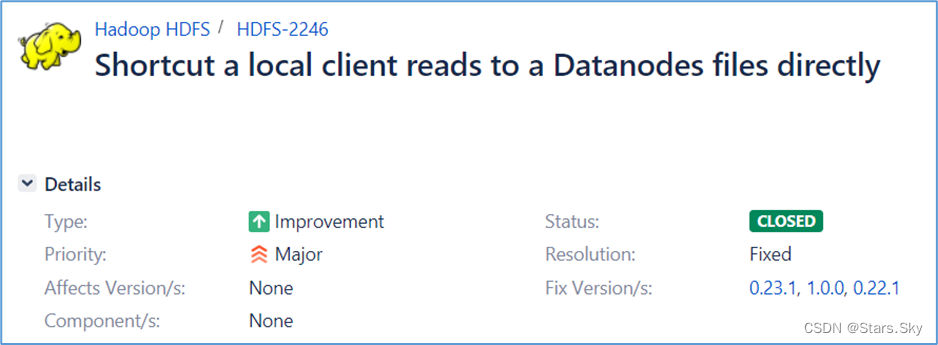 首先是配置问题,因为是让 DFSClient 自己打开文件读取数据,那么就需要配置一个白名单,定义哪些用户拥有访问 Datanode 的数据目录权限。
首先是配置问题,因为是让 DFSClient 自己打开文件读取数据,那么就需要配置一个白名单,定义哪些用户拥有访问 Datanode 的数据目录权限。
如果有新用户加入,那么就得修改白名单。需要注意的是,这里是允许客户端访问 Datanode的数据目录,也就意味着,任何用户拥有了这个权限,就可以访问目录下其他数据,从而导致了安全漏洞。
因此,这个实现已经不建议使用了。
 1.3 安全性改进版设计实现
1.3 安全性改进版设计实现
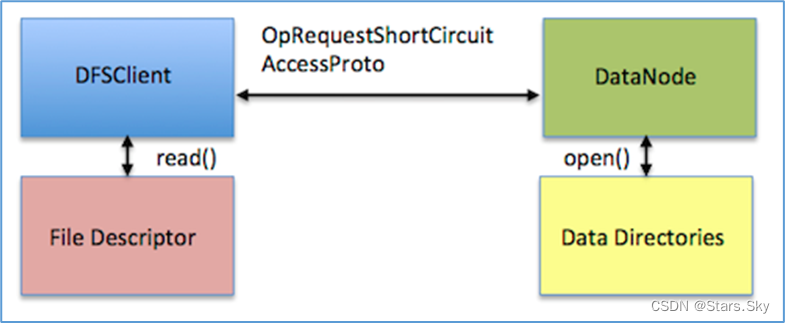
在 HDFS-347 中,提出了一种新的解决方案,让短路本地读取数据更加安全。在 Linux 中,有个技术叫做 Unix Domain Socket。Unix Domain Socket 是一种进程间的通讯方式,它使得同一个机器上的两个进程能以Socket的方式通讯。它带来的另一大好处是,利用它两个进程除了可以传递普通数据外,还可以在进程间传递文件描述符。
 假设机器上的两个用户 A 和 B,A 拥有访问某个文件的权限而 B 没有,而 B 又需要访问这个文件。借助 Unix Domain Socket,可以让 A 打开文件得到一个文件描述符,然后把文件描述符传递给 B,B 就能读取文件里面的内容了即使它没有相应的权限。
假设机器上的两个用户 A 和 B,A 拥有访问某个文件的权限而 B 没有,而 B 又需要访问这个文件。借助 Unix Domain Socket,可以让 A 打开文件得到一个文件描述符,然后把文件描述符传递给 B,B 就能读取文件里面的内容了即使它没有相应的权限。
在 HDFS 的场景里面,A 就是 Datanode,B 就是 DFSClient,需要读取的文件就是 Datanode 数据目录中的某个文件。
1.4 短路本地读取配置
1.4.1 libhadoop.so
因为 Java 不能直接操作 Unix Domain Socket,所以需要安装 Hadoop 的 native 包libhadoop.so。在编译 Hadoop 源码的时候可以通过编译 native 模块获取。可以用如下命令来检查native 包是否安装好。

1.4.2 hdfs-site.xml
[root@hadoop01 ~]# vim /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>- dfs.client.read.shortcircuit 是打开短路本地读取功能的开关。
- dfs.domain.socket.path 是 Dtanode 和 DFSClient 之间沟通的 Socket 的本地路径。
还要确保 Socket 本地路径提前创建好(集群的每个节点都需要创建):
[root@hadoop01 ~]# mkdir -p /var/lib/hadoop-hdfs
注意:这里创建的是文件夹 hadoop-hdfs,而上述配置中的 dn_socket 是 datanode 自己创建的,不是文件夹。
最后把配置文件推送到其他节点上,并重启 HDFS 集群即可。
1.4.3 查看 Datanode 日志
在 Datanode 的启动日志中,看到如下相关的日志表明 Unix Domain Socket 被启用了,确认配置生效。
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/logs/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/logs]# tail -100 hadoop-root-datanode-hadoop01.log

二、HDFS Block 负载平衡器:Balancer
2.1 背景
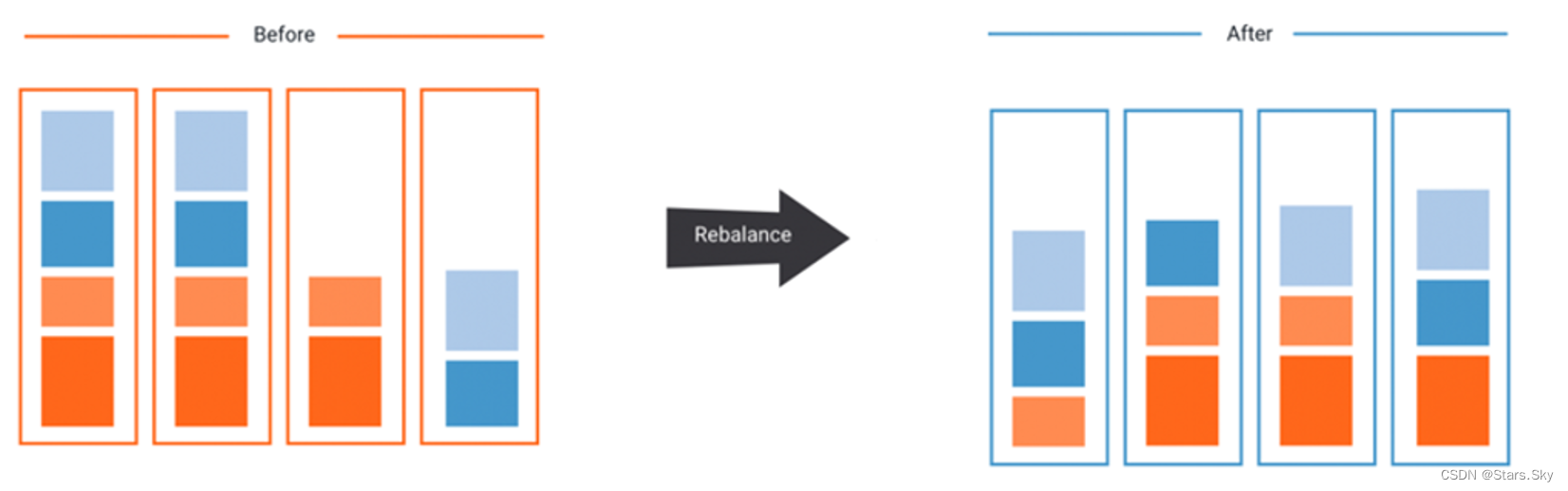
HDFS数据可能并不总是在DataNode之间均匀分布。一个常见的原因是向现有群集中添加了新的 DataNode。HDFS 提供了一个 Balancer 程序,分析 block 放置信息并且在整个 DataNode 节点之间平衡数据,直到被视为平衡为止。
所谓的平衡指的是每个 DataNode 的利用率(本机已用空间与本机总容量之比)与集群的利用率(HDFS 整体已用空间与 HDFS 集群总容量的比)之间相差不超过给定阈值百分比。 平衡器无法在单个 DataNode 上的各个卷(磁盘)之间进行平衡。
 2.2 命令行配置
2.2 命令行配置
[root@hadoop01 ~]# hdfs balancer --help
Usage: hdfs balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | <comma-separated list of hosts>]] Excludes the specified datanodes.
[-include [-f <hosts-file> | <comma-separated list of hosts>]] Includes only the specified datanodes.
[-source [-f <hosts-file> | <comma-separated list of hosts>]] Pick only the specified datanodes as source nodes.
[-blockpools <comma-separated list of blockpool ids>] The balancer will only run on blockpools included in this list.
[-idleiterations <idleiterations>] Number of consecutive idle iterations (-1 for Infinite) before exit.
[-runDuringUpgrade] Whether to run the balancer during an ongoing HDFS upgrade.This is usually not desired since it will not affect used space on over-utilized machines.
-
-threshold 10 集群平衡的条件,datanode 间磁盘使用率相差阈值,区间选择:0~100
-
-policy datanode 平衡策略,默认为 datanode,如果 datanode 平衡,则集群已平衡.
-
-exclude -f /tmp/ip1.txt 默认为空,指定该部分 ip 不参与 balance,-f 指定输入为文件
-
-include -f /tmp/ip2.txt 默认为空,只允许该部分 ip 参与 balance,-f 指定输入为文件
-
-idleiterations 5 迭代 5
2.3 如何运行 Balancer
2.3.1 设置平衡数据传输带
hdfs dfsadmin -setBalancerBandwidth newbandwidth
其中 newbandwidth 是每个 DataNode 在平衡操作期间可以使用的最大网络带宽量,以每秒字节数为单位。
比如:hdfs dfsadmin -setBalancerBandwidth 104857600(100M)
2.3.2 运行 balancer
默认参数运行:hdfs balancer
指定阈值运行:hdfs balancer -threshold 5 Balancer 将以阈值 5% 运行(默认值 10%)。
这意味着程序将确保每个 DataNode 上的磁盘使用量与群集中的总体使用量相差不超过 5%。例如,如果集群中所有 DataNode 的总体使用率是集群磁盘总存储容量的 40%,则程序将确保每个 DataNode 的磁盘使用率在该 DataNode 磁盘存储容量的 35% 至 45% 之间。
三、磁盘均衡器:HDFS Disk Balancer
3.1 背景
相比较于个人 PC,服务器一般可以通过挂载多块磁盘来扩大单机的存储能力。在 Hadoop HDFS 中,DataNode 负责最终数据 block 的存储,在所在机器上的磁盘之间分配数据块。当写入新 block 时,DataNodes 将根据选择策略(循环策略或可用空间策略)来选择 block 的磁盘(卷)。

- 循环策略:它将新 block 均匀分布在可用磁盘上。默认此策略。
- 可用空间策略:此策略将数据写入具有更多可用空间(按百分比)的磁盘。

但是在长期运行的群集中采用循环策略时,DataNode 有时会不均匀地填充其存储目录(磁盘/卷),从而导致某些磁盘已满而其他磁盘却很少使用的情况。发生这种情况的原因可能是由于大量的写入和删除操作,也可能是由于更换了磁盘。
另外,如果我们使用基于可用空间的选择策略,则每个新写入将进入新添加的空磁盘,从而使该期间的其他磁盘处于空闲状态。这将在新磁盘上创建瓶颈。因此,需要一种 Intra DataNode Balancing(DataNode 内数据块的均匀分布)来解决 Intra-DataNode 偏斜(磁盘上块的不均匀分布),这种偏斜是由于磁盘更换或随机写入和删除而发生的。
因此,Hadoop 3.0 中引入了一个名为 Disk Balancer 的工具,该工具专注于在 DataNode 内分发数据。
3.2 HDFS Disk Balancer 简介
HDFS disk balancer 是 Hadoop 3 中引入的命令行工具,用于平衡 DataNode 中的数据在磁盘之间分布不均匀问题。 这里要特别注意,HDFS disk balancer 与 HDFS Balancer 是不同的:
- HDFS disk balancer 针对给定的 DataNode 进行操作,并将块从一个磁盘移动到另一个磁盘,是 DataNode 内部数据在不同磁盘间平衡;
- HDFS Balancer 平衡了 DataNode 节点之间的分布。
3.3 HDFS Disk Balancer 功能
3.3.1 数据传播报告
为了衡量集群中哪些计算机遭受数据分布不均的影响,磁盘平衡器定义了 Volume Data Density metric(卷/磁盘数据密度度量标准)和 Node Data Density metric(节点数据密度度量标准)。
- 卷(磁盘)数据密度:比较同台机器上不同卷之间的数据分布情况。
- 节点数据密度:比较的是不同机器之间的。
3.3.1.1 Volume data density metric(卷数据密度)计算
volume Data Density的 正值表示磁盘未充分利用,而负值表示磁盘相对于当前理想存储目标的利用率过高。
假设有一台具有四个卷/磁盘的计算机-Disk1,Disk2,Disk3,Disk4,各个磁盘使用情况:

Total Capacity= 200 + 300 + 350 + 500 = 1350 GB
Total Used= 100 + 76 + 300 + 475 = 951 GB
因此,每个卷/磁盘上的理想存储为:
Ideal Storage = Total Used ÷ Total Capacity= 951÷1350 = 0.70
也就是每个磁盘应该保持在70%理想存储容量。
Volume Data Density = Ideal Storage – dfs Used Ratio
比如 Disk1 的卷数据密度 = 0.70 - 0.50 = 0.20。其他以此类推。
3.3.1.2 Node Data Density 计算过程
Node Data Density(节点数据密度)= 该节点上所有volume data density卷(磁盘)数据密度绝对值的总和。
上述例子中的节点数据密度=|0.20|+|0.45|+|-0.15|+|-0.24| =1.04
较低的 node Data Density 值表示该机器节点具有较好的扩展性,而较高的值表示节点具有更倾斜的数据分布。
一旦有了 volume Data Density 和 node Data Density,就可以找到集群中数据分布倾斜的节点和机器上数据分步倾斜的磁盘。
3.3.2 磁盘平衡
当指定某个 DataNode 节点进行 disk 数据平衡,就可以先计算或读取当前的 volume Data Density(磁卷数据密度)。有了这些信息,我们可以轻松地确定哪些卷已超量配置,哪些卷已不足。
为了将数据从一个卷移动到 DataNode 中的另一个卷,Hadoop 开发实现了基于 RPC 协议的Disk Balancer。
3.4 HDFS Disk Balancer 开启
HDFS Disk Balancer 通过创建计划进行操作,该计划是一组语句,描述应在两个磁盘之间移动多少数据,然后在 DataNode 上执行该组语句。计划包含多个移动步骤。计划中的每个移动步骤都具有目标磁盘,源磁盘的地址。移动步骤还具有要移动的字节数。该计划是针对可操作的DataNode 执行的。
默认情况下,Hadoop 群集上已经启用了 Disk Balancer 功能。通过在 hdfs-site.xml 中调整dfs.disk.balancer.enabled 参数值,选择在 Hadoop 中是否启用磁盘平衡器。
3.5 HDFS Disk Balancer 相关命令
3.5.1 plan 计划
命令:hdfs diskbalancer -plan <datanode>
-
-out 控制计划文件的输出位置
-
-bandwidth 设置用于运行 Disk Balancer 的最大带宽,默认带宽 10 MB/s.
-
-thresholdPercentage 定义磁盘开始参与数据重新分配或平衡操作的值。默认的thresholdPercentage 值为 10%,这意味着仅当磁盘包含的数据比理想存储值多10%或更少时,磁盘才用于平衡操作.
-
-maxerror 它允许用户在中止移动步骤之前为两个磁盘之间的移动操作指定要忽略的错误数.
-
-v 详细模式,指定此选项将强制 plan 命令在 stdout 上显示计划的摘要.
-
-fs 此选项指定要使用的 NameNode。如果未指定,则 Disk Balancer 将使用配置中的默认 NameNode.
3.5.2 Execute 执行
命令:hdfs diskbalancer -execute <JSON file path>
execute 命令针对为其生成计划的 DataNode 执行计划。
3.5.3 Query 查询
命令:hdfs diskbalancer -query <datanode>
query 命令从运行计划的 DataNode 获取 HDFS 磁盘平衡器的当前状态
3.5.4 Cancel 取消
命令:hdfs diskbalancer -cancel <JSON file path>
hdfs diskbalancer -cancel planID node <nodename>
cancel 命令取消运行计划。
3.5.5 Report 汇报
命令:hdfs diskbalancer -fs hdfs://nn_host:8020 -report
四、纠删码技术:Erasure Coding
4.1 背景:3 副本策略弊端
为了提供容错能力,HDFS 会根据 replication factor(复制因子)在不同的 DataNode 上复制文件块。
默认复制因子为 3(注意这里的 3 指的是 1+2=3,不是额外 3 个),则原始块除外,还将有额外两个副本。每个副本使用 100% 的存储开销,因此导致 200% 的存储开销。这些副本也消耗其他资源,例如网络带宽。
在复制因子为 N 时,存在 N-1 个容错能力,但存储效率仅为 1/N。
 4.2 Erasure Coding(EC)简介
4.2 Erasure Coding(EC)简介
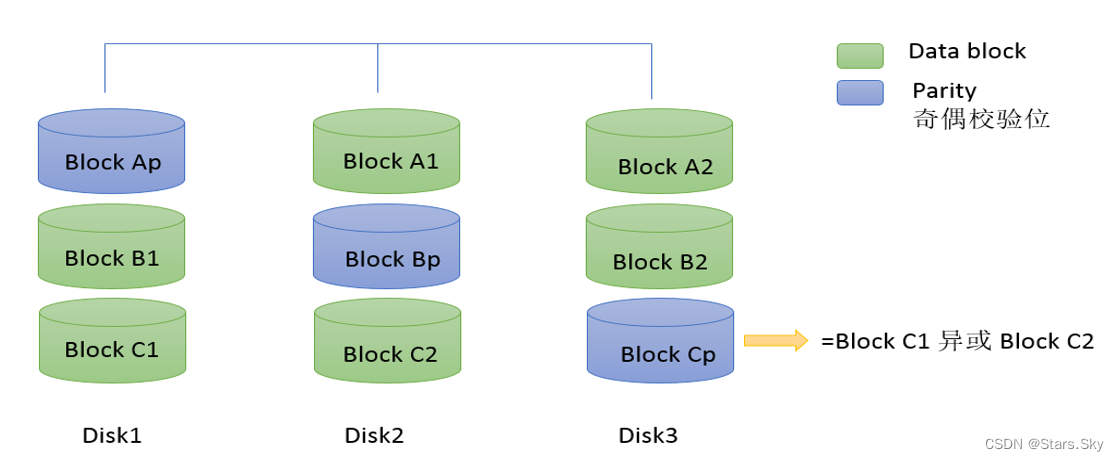
纠删码技术(Erasure coding)简称 EC,是一种编码容错技术。最早用于通信行业,数据传输中的数据恢复。它通过对数据进行分块,然后计算出校验数据,使得各个部分的数据产生关联性。当一部分数据块丢失时,可以通过剩余的数据块和校验块计算出丢失的数据块。
Hadoop 3.0 之后引入了纠删码技术(Erasure Coding),它可以提高 50% 以上的存储利用率,并且保证数据的可靠性。
4.3 Reed-Solomon(RS)码
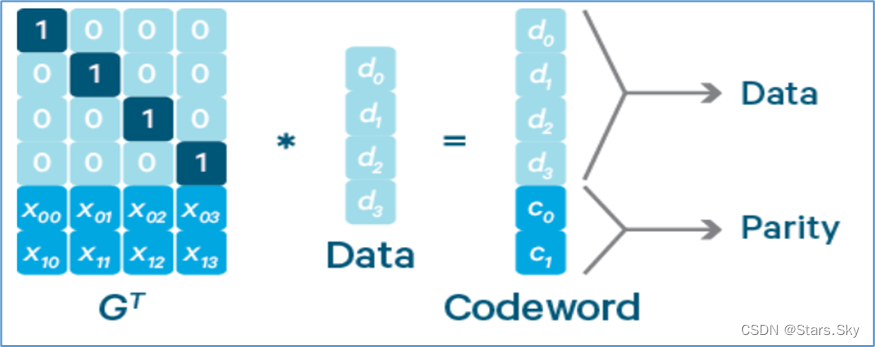
Reed-Solomon(RS)码是常用的一种纠删码,它有两个参数 k 和 m,记为 RS(k,m)。
k 个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT 从而得到一个码字(codeword)向量,该向量由 k 个数据块(d0,d1..d3)和 m 个校验块(c0,c1)构成。
如果数据块丢失,可以用 GT 逆矩阵乘以码字向量来恢复出丢失的数据块。
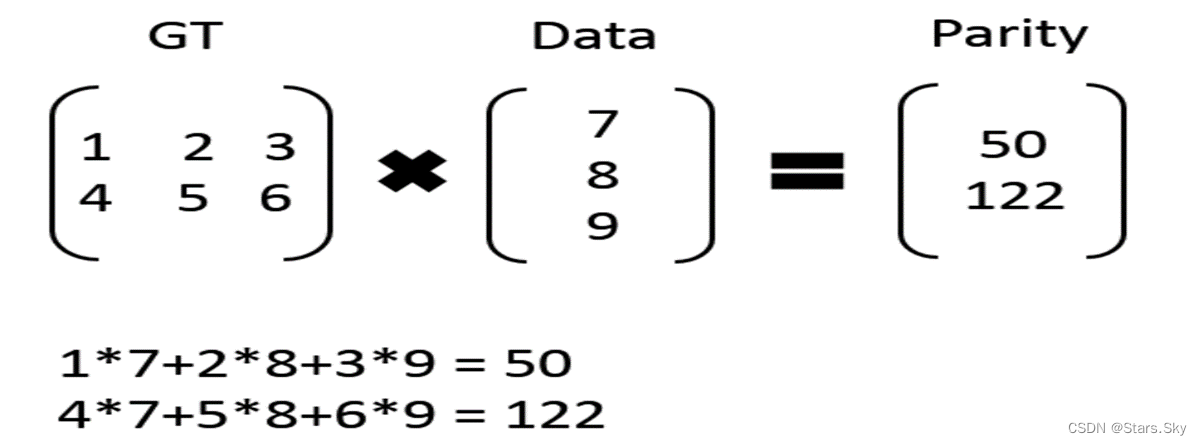
 比如有 7、8、9 三个原始数据,通过矩阵乘法,计算出来两个校验数据 50、122。
比如有 7、8、9 三个原始数据,通过矩阵乘法,计算出来两个校验数据 50、122。
这时原始数据加上校验数据,一共五个数据:7、8、9、50、122,可以任意丢两个,然后通过算法进行恢复。
 4.4 Hadoop EC架构
4.4 Hadoop EC架构
为了支持纠删码,HDFS 体系结构进行了一些更改调整。
- Namenode扩展
条带化的 HDFS 文件在逻辑上由 block group(块组)组成,每个块组包含一定数量的内部块。这允许在块组级别而不是块级别进行文件管理。
- 客户端扩展
客户端的读写路径得到了增强,可以并行处理块组中的多个内部块。
- Datanode扩展
DataNode 运行一个附加的 ErasureCodingWorker(ECWorker)任务,以对失败的纠删编码块进行后台恢复。 NameNode 检测到失败的 EC 块,然后 NameNode 选择一个 DataNode 进行恢复工作。
- 纠删编码策略
为了适应异构的工作负载,允许 HDFS 群集中的文件和目录具有不同的复制和纠删码策略。纠删码策略封装了如何对文件进行编码/解码。默认情况下启用 RS-6-3-1024k 策略, RS 表示编码器算法 Reed-Solomon,6 、3 中表示数据块和奇偶校验块的数量,1024k 表示条带化单元的大小。
目录上还支持默认的 REPLICATION 方案。它只能在目录上设置,以强制目录采用 3 倍复制方案,而不继承其祖先的纠删码策略。此策略可以使3x复制方案目录与纠删码目录交错。REPLICATION 始终处于启用状态。
此外也支持用户通过 XML 文件定义自己的 EC 策略,Hadoop conf 目录中有一个名为user_ec_policies.xml.template 的示例 EC 策略 XML 文件,用户可以参考该文件。
- Intel ISA-L
英特尔 ISA-L 代表英特尔智能存储加速库。 ISA-L 是针对存储应用程序而优化的低级功能的开源集合。它包括针对 Intel AVX 和 AVX2 指令集优化的快速块 Reed-Solomon 类型擦除代码。 HDFS 纠删码可以利用 ISA-L 加速编码和解码计算。
4.5 Erasure Coding 部署方式
4.5.1 集群和硬件配置
编码和解码工作会消耗HDFS客户端和DataNode上的额外 CPU。
纠删码文件也分布在整个机架上,以实现机架容错。这意味着在读写条带化文件时,大多数操作都是在机架上进行的。因此,网络带宽也非常重要。
对于机架容错,拥有足够数量的机架也很重要,每个机架所容纳的块数不超过 EC 奇偶校验块的数。机架数量=(数据块+奇偶校验块)/奇偶校验块后取整。
比如对于 EC 策略 RS(6,3),这意味着最少 3 个机架(由(6 + 3)/ 3 = 3计算),理想情况下为 9 个或更多,以处理计划内和计划外的停机。对于机架数少于奇偶校验单元数的群集,HDFS 无法维持机架容错能力,但仍将尝试在多个节点之间分布条带化文件以保留节点级容错能力。因此,建议设置具有类似数量的 DataNode 的机架。
4.5.2 纠删码策略设置
纠删码策略由参数 dfs.namenode.ec.system.default.policy 指定,默认是 RS-6-3-1024k,其他策略默认是禁用的。
可以通过 hdfs ec [-enablePolicy -policy <policyName>] 命令启用策略集。
4.5.3 启用英特尔 ISA-L(智能存储加速库)
默认 RS 编解码器的 HDFS 本机实现利用 Intel ISA-L 库来改善编码和解码计算。要启用和使用 Intel ISA-L,需要执行三个步骤。
- 建立 ISA-L 库;
- 使用 ISA-L 支持构建 Hadoop;
- 使用 -Dbundle.isal 将 isal.lib 目录的内容复制到最终的 tar 文件中。使用 tar 文件部署Hadoop。确保 ISA-L 在 HDFS 客户端和 DataNode 上可用。
所需软件:
| 软件 | 版本 |
|---|---|
| Hadoop | 3.2.4 |
| isa-l | 2.28.0 |
| nasm | 2.14.02 |
| yasm | 1.2.0 |
4.5.3.1 安装 yasm 和 nasm
# 在Hadoop集群所有节点上安装yasm和nasm。
yum install -y yasm
yum install -y nasm
# 注意:isa-l-2.28.0 对 nasm 和 yasm 有版本要求,低版本在安装时会报错。4.5.3.2 编译安装isa-l-2.28.0
# 在 Hadoop集群所有节点上编译安装 isa-l-2.28.0。
tar -zxvf isa-l-2.28.0.tar.gz
cd isa-l-2.28.0
./autogen.sh
./configure --prefix=/usr --libdir=/usr/lib64
make
make install
make -f Makefile.unx
# 检查 libisal.so* 是否成功
ll /lib64/libisal.so*
############如果有,则跳过##############
############如果没有有,则复制##############
cp bin/libisal.so bin/libisal.so.2 /lib644.5.3.3 Hadoop 上检查是否启用 isa-l
[root@hadoop01 ~]# hadoop checknative
Native library checking:
hadoop: true /usr/hdp/3.0.0.0-1634/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
zstd : false
snappy: true /usr/hdp/3.0.0.0-1634/hadoop/lib/native/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: true /lib64/libcrypto.so
ISA-L: true /lib64/libisal.so.2 -------------> Shows that ISA-L is loaded.4.5.4 EC 命令
[root@hadoop01 ~]# hdfs ec
Usage: bin/hdfs ec [COMMAND]
[-listPolicies]
[-addPolicies -policyFile <file>]
[-getPolicy -path <path>]
[-removePolicy -policy <policy>]
[-setPolicy -path <path> [-policy <policy>] [-replicate]]
[-unsetPolicy -path <path>]
[-listCodecs]
[-enablePolicy -policy <policy>]
[-disablePolicy -policy <policy>]
[-verifyClusterSetup [-policy <policy>...<policy>]]
[-help <command-name>]
[-setPolicy -path <path> [-policy <policy>] [-replicate]]
-
在指定路径的目录上设置擦除编码策略。
-
path:HDFS 中的目录。这是必填参数。设置策略仅影响新创建的文件,而不影响现有文件。
-
policy:用于此目录下文件的擦除编码策略。默认 RS-6-3-1024k 策略。
-
-replicate 在目录上应用默认的 REPLICATION 方案,强制目录采用 3x 复制方案。replicate和 -policy <policy> 是可 选参数。不能同时指定它们。
[-getPolicy -path < path >]
获取指定路径下文件或目录的擦除编码策略的详细信息。
[-unsetPolicy -path < path >]
取消设置先前对目录上的 setPolicy 的调用所设置的擦除编码策略。如果该目录从祖先目录继承了擦除编码策略 ,则 unsetPolicy 是 no-op。在没有显式策略集的目录上取消策略将不会返回错误。
[-listPolicies]
列出在 HDFS 中注册的所有(启用,禁用和删除)擦除编码策略。只有启用的策略才适合与 setPolicy 命令一起使用。
[-addPolicies -policyFile <文件>]
添加用户定义的擦除编码策略列表。
[-listCodecs]
获取系统中支持的擦除编码编解码器和编码器的列表。
[-removePolicy -policy <policyName>]
删除用户定义的擦除编码策略。
[-enablePolicy -policy <policyName>]
启用擦除编码策略。
[-disablePolicy -policy <policyName>]
禁用擦除编码策略。