导语
Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低学习成本,十分适合对数据仓库进行统计分析。
近几年,随着行业内数据体量的不断增大,再加上国产化的趋势下,很多企业都开始着手对自己已有的大数据平台进行扩容、升级、产品更换等一系列操作,以期可以赶上潮流。因此,就会有很多项目需要进行数据库迁移,本文主要总结了一些在项目上遇到Hive迁移时,可以使用的方式方法,供大家参考借鉴。
目录
● 1. Hive迁移类型
● 2. Hive迁移步骤
● 3. Hive迁移实施步骤
● 4. 结语
1. Hive迁移类型
■ 表和数据整体迁移
一般在企业进行大数据平台产品的升级更换(如国产化)、机房搬迁、物理机转向云平台等情况下,会进行整库迁移,那么此时Hive迁移建议使用表和数据整体迁移的方式进行迁移。
■ 表和数据分步迁移
一般在企业进行数据库改造、历史数据库区域创建、业务条线改造等,或是数据库出现瓶颈的情况下,会进行部分数据迁移,那么此时Hive迁移建议使用表和数据分步迁移的方式进行迁移。
2. Hive迁移步骤
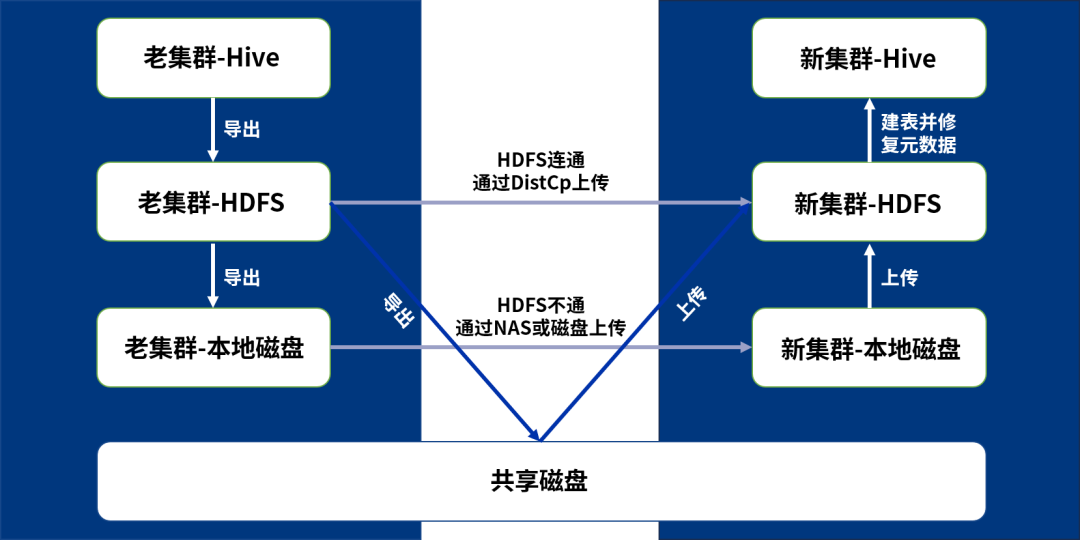
(1)将表和数据从老集群Hive导出到老集群HDFS
(2)将表和数据从老集群HDFS导出到老集群本地磁盘或共享磁盘
(3)将表和数据从老集群本地磁盘复制到新集群本地磁盘(如共享磁盘此步骤省略)
(4)将表和数据从新集群本地磁盘或共享磁盘上传到新集群HDFS
(5)修复新集群Hive数据库元数据
如果老集群HDFS和新集群HDFS连通,可使用DistCp工具跨集群复制,跳过中间步骤,直接执行第5步。
3. Hive迁移实施步骤
■ 新集群和服务器检查
#查看本地空间使用情况是否足够
df -h#查看HDFS集群使用情况是否满足
hadoop dfsadmin -report#查找Hive库存储位置
hadoop fs -find / -name warehouse#查看Hive库占用情况
hadoop fs -du -h /user/hive/warehouse■ 表和数据整体迁移
一般Hive整体迁移时使用HDFS文件迁移,然后再进行数据表与数据文件关联即可,新老集群Hive版本即使不一致的情况下也支持该步骤,详细操作步骤如下:
老集群备份
# 罗列迁移表清单
cat <<EOF > /home/data/backup/hive_sel_tables.hql
use <db_name>;
show tables;
EOF# 清洗迁移表清单
beeline -f /home/data/backup/hive_sel_tables.hql \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/data/backup/hive_table_list.txt# 拼接建表语句命令及清洗无用字符
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "show create table <db_name>.%s;\n",$1,$1}' \
| sed "s/|//g" \
| sed "s/+/'/g" \
| grep -v "tab_name" \
> /home/data/backup/hive_show_create_table.hql# 导出建表语句
beeline -e /home/data/backup/hive_show_create_table.hql>/home/data/backup/hive_table_ddl.sql# 清洗建表语句
sed -i 's/^|//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/|$//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/-//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/+//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/createtab_stmt//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/.*0: jdbc:hive2:.*/;/' /home/data/backup/hive_table_ddl.sql
sed -i '/^$/d' /home/data/backup/hive_table_ddl.sql# 拼接修复Hive元数据语句
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "msck repair table archive.%s;\n",$1,$1}' \
| sed "s/|//g" \
| sed "s/+/'/g" \
| grep -v "tab_name" \
> /home/data/backup/hive_repair_table.hql# 将Hive在HDFS中的文件导出到HDFS临时目录
hadoop fs -get /user/hive/warehouse/<db_name> /tmp# HDFS集群连通时使用DistCp进行拷贝
hadoop distcp hdfs://scrNameNode/tmp/<db_name> hdfs://user/hive/warehouse/<db_name># HDFS集群不连通,导出HDFS文件到本地磁盘或者共享NAS
hadoop fs -get /tmp/<db_name> /home/data/backup/# 如果是共享磁盘忽略此步
scp -r /home/data/backup/ root@targetAP:/home/data/backup/新集群恢复
# 登录生产环境Hive并创建表
beeline -f /home/data/backup/hive_table_ddl.sql>>/home/data/backup/hive_table_ddl.log# 检查新集群数据库新表是否创建成功
beeline
use <db_name>
show tables;# 将数据文件上传到HDFS的Hive存储路径下
hadoop fs -put /home/data/backup/<db_name> /user/hive/warehouse/<db_name># 关联Hive表和数据
beeline -f /home/data/backup/hive_repair_table.hql# 查看HDFS所有目录检查是否都导入成功
hadoop fs -lsr /home# 查看所有表大小,验证新旧表大小是否一致
hadoop fs -du -h /user/hive/warehouse/<db_name>■ 表和数据分步迁移
一般Hive分步迁移时使用Import和Export,新老集群Hive版本不一致的情况下也支持该步骤。
Export工具导出时会同时导出元数据和数据;
Import工具会根据元数据自行创建表并导入数据。
老集群备份
# 罗列迁移表清单
cat <<EOF > /home/data/backup/hive_sel_tables.hql
use <db_name>;
show tables;
EOF# 罗列要迁移的表清单
beeline -f /home/data/backup/hive_sel_tables.hql\
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/data/backup/hive_table_list.txt# 生成导出脚本
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "export table <db_name>.%s to |/tmp/<db_name>/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/data/backup/hive_export_table.hql# 生成导入脚本
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "import table <db_name>.%s from |/tmp/<db_name>/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/data/backup/hive_import_table.hql# 创建HDFS导出目录
hadoop fs -mkdir -p /tmp/<db_name>/# 导出表结构到数据到HDFS
beeline -f /home/data/backup/hive_export_table.hql#HDFS集群连通时使用DistCp进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp# HDFS集群不连通,导出HDFS文件到本地磁盘或者共享NAS
hadoop fs -get /tmp/<db_name> /home/data/backup/# 如果是共享磁盘忽略此步
scp -r /home/data/backup/ root@targetAP:/home/data/backup/新集群恢复
# 创建HDFS导出目录
hadoop fs -mkdir -p /tmp/<db_name>/#上传到目标HDFS
hadoop fs -put /home/data/backup/<db_name> /tmp# 导入到目标Hive
beeline -f /home/data/backup/hive_import_table.hql# 查看HDFS所有目录检查是否都导入成功
hadoop fs -lsr /home# 查看所有表大小,验证新旧表大小是否一致
hadoop fs -du -h /user/hive/warehouse/<db_name>4. 总结
Hive的数据迁移其实有多种方式,根据需求不同采用的迁移方式也不尽相同,每种迁移的优势也是不同的,其中数据量是影响迁移的重要因素之一。
在数据量不大的情况下,Hive迁移一般常用的方式是使用Export、Import进行数据和元数据的导出导入,Export会将数据和元数据写到一起,并且元数据在恢复时是直接关联数据的,不需要再做其他的操作。同时还直接关联分区,不需要再使用MSCK进行分区修复。需要注意的一点的是,Import和Export在进行数据恢复的时候,只会关注到表层的文件夹,不用和旧集群的文件路径一摸一样。
在数据量比较大的情况下,建议使用整体迁移的方式,这样Hive迁移的速度较快,但是注意要保证新旧集群数据目录的一致性。