文章目录
- 前言
- 一、分库分表:
- 二、读写分离:
- 2.1 读写分离的实现:
- 2.2 主从延迟:
- 2.2.1 主从延迟造成的问题:
- 2.2.2 主从延迟的原因:
- 2.2.3 主从延迟的解决方案:
- 2.2.3.1 db 层面:
- 2.2.3.2 程序层面:
- 三、全局id:
- 四、分布式事务:
- 总结
前言
springboot 在整合mycat 之后,对于分库分表,读写分离,分布式事务 这些常用的业务处理是怎么实现的。
一、分库分表:
分库分表 主要取决于mycat server 端 中 schema.xml 配置文件对数据库表单的分片规则进行;

二、读写分离:
2.1 读写分离的实现:
分库分表 主要取决于mycat server 端 中 schema.xml 配置文件对数据库节点主库和从库的设置实现:
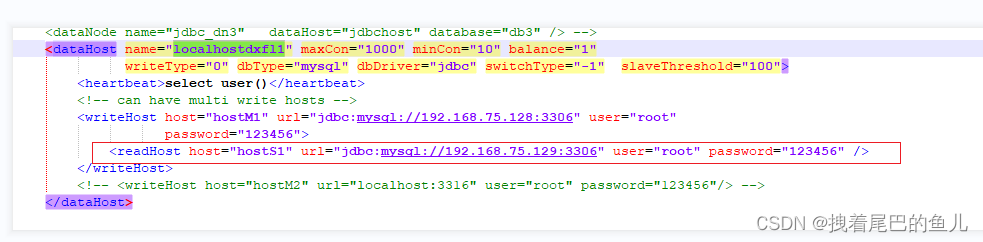
读写分离的前提是要实现mysql 主从复制,其中schema.xml 中 writeHost标签可以定义写库,readHost 可以定义读库;
2.2 主从延迟:
2.2.1 主从延迟造成的问题:
当写入数据后,然后进行数据读取,因为写入的是主库,读取的是从库,数据从主库到从库会存在一定的时间延迟,尤其是在高并发情况下这个延迟时间可能会比较大,从而造成从从库读取不到数据的情况出现;
2.2.2 主从延迟的原因:
-
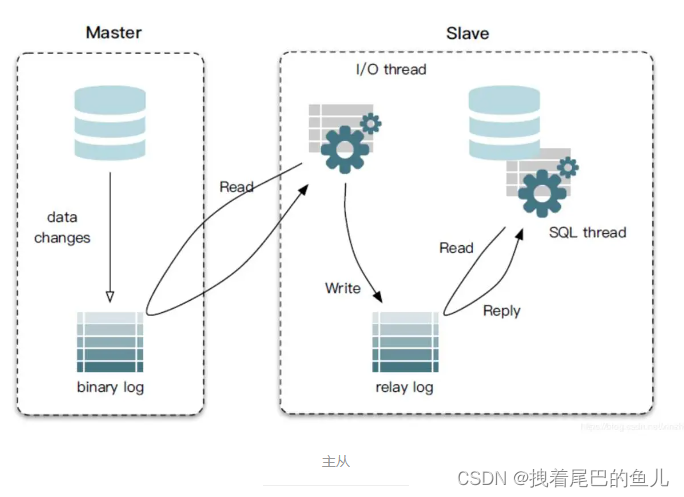
master服务器将数据的改变都记录到二进制binlog日志中,只要master上的数据发生改变,则将其改变写入二进制日志;
-
salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件
-
同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中
-
从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致
-
最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒.
主库针对写操作,顺序写binlog,从库单线程去主库读binlog,从库单线程去主库 取到binlog 在本地随机写,来保证主从数据逻辑上的一致。主库对所有DDL和DML产生binlog,binlog是顺序写,效率很高。从库的SlaveIORunning 线程到主库取binlog(因为要保证事务的顺序性所以是单线程进行),效率也比较高。下一步从库的SlaveSqlRunning 将主库的 DDL和DML在从库上执行(虽然在在MySQL 5.7版本之后,从库可以适应并行复制来提高效率,但是搞并发情况下依然可能有问题出现),DDL 和 DML 是随机写,成本很高,还有可能从库上其他查询产生的lock争用,所以从库 sql Thread 线程可能无法及时的将数据写入到从库中;
2.2.3 主从延迟的解决方案:
主从延迟可以从db 和程序层面进行优化;
2.2.3.1 db 层面:
主要解决主从数据同步,从库的延迟问题通过 SHOW SLAVE STATUS 获取主从同步延迟的时间(数据越小延迟越低):
- 并在从库中开启并行复制,使用多个线程读取中继日志然后进行从库的写入;
MySQL从5.6版本开始支持并行复制,对于多线程的场景,可以有效减少复制延迟,并且从 5.7 版本开始进一步的优化。
并行复制的基本原理是,如果在主库中同时进行的多个事务没有相互冲突,在从库端这多个事务也可以同时进行,而不需要按原始顺序逐个执行,从而提高了复制的效率和速度,进而减少了主从之间的延迟。
基于此原理,在 MySQL 5.7 及之后的版本中,MySQL 进一步引入了逻辑时钟的概念。在 5.7 版本中,MySQL 通过一个全局逻辑时钟来对并行事务进行排序,每一个事务提交的时候都会写一个逻辑时钟值,然后在从库端通过逻辑时钟来对这些事务进行排序,以此来决定哪些事务之间的准备阶段(apply stage)可以并发执行。
需要注意的是,并行复制并不意味着从库可以无限制地进行并发复制,还需要根据从库的具体硬件情况和业务场景来确定最大并发度,避免对从库的性能产生过大影响。
- 从库配置并行复制:
在主库已经开启bin-log 后在从库中,添加或修改下列参数:
[mysqld]
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 4
slave_parallel_type:设置为“LOGICAL_CLOCK”以启用基于逻辑时钟的并行复制。
slave_parallel_workers:设置并行复制的线程数。如果你有一个强大的从库服务器和多核处理器,可以尝试增加这个值。但要注意,设置过大可能会导致从库上过多的上下文切换,反而降低性能。
2.2.3.2 程序层面:
- 缓存层,在前端访问和数据库之间,添加缓存,优先从缓存读取,减弱数据库的并发压力,Slave 只作为数据备份,不分担访问流量;
- 将大事务拆为小事务,不必要的地方移除事务;
- 在主库插入数据后,进行多次查询或者睡眠一定的时间然后在进行查询;
三、全局id:
可以使用mycat 服务端,使用雪花算法来生成全局id:在server.xml 配置通过时间戳来生成id:
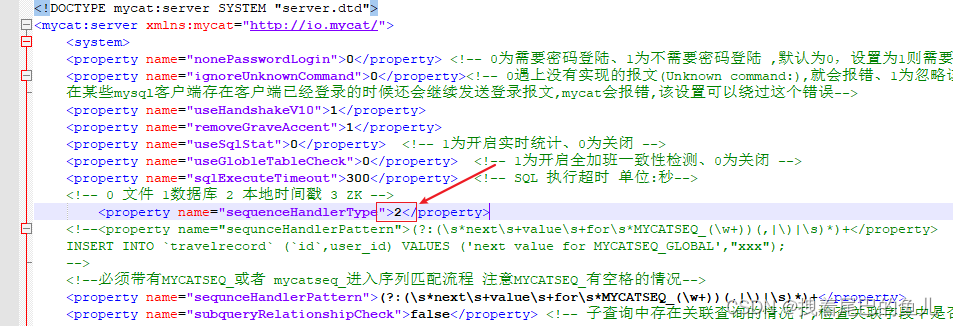
四、分布式事务:
Mycat在1.6版本以后已经完全支持 XA(2PC) 实现分布式强事务类型了;springboot 中的实现在方法中增加 @Transactional 接口

- 当应用程序方法中使用了 @Transactional 注解时,Spring 会在方法执行前启动一个事务,并将事务请求发送给 Mycat Server。然后,应用程序方法会在这个事务的上下文中执行相关的数据库读写操作等。
- 在方法执行期间,如果有其他数据库操作需要参与到同一个分布式事务中,Mycat Server 会将这些数据库操作拆分为相应的子事 务,并分发给各个后端 MySQL 实例执行。
- 每个后端MySQL实例在本地事务中执行接收到的SQL操作。
- 在事务的执行过程中,Mycat Server获取和记录每个后端MySQL实例的事务状态。
- Mycat Server收集到某个后端MySQL实例操作失败的结果时,它将这个失败结果通知给应用程序事务管理器,以便由事务管理器来决定回滚整个分布式事务;
- 在调用方应用程序方法执行结束后,Spring事务管理器会根据方法执行的成功与否以及其他业务规则,决定是提交整个事务还是回滚整个事务
- Spring 会将提交或回滚的指令发送给 Mycat Server,Mycat Server 接收到指令后会进一步将指令发送给各个后端 MySQL 实例。
总结
以上就是今天要讲的内容,本文阐述了使用mycat 如何完成分库分表,配置读写分离,以及基于xa 事务实现分布式事务。