一、说明
朋友们,您可能听说过,在不平衡数据集上训练的模型可能会受到泛化不佳和少数类检测减少的影响。在接下来的几篇文章中,我将给你一个例子来展示不平衡的数据集如何影响模型的性能,以及我们如何处理这个问题。在这篇文章中,我们将首先下载数据并对其进行处理以进行进一步分析。
二、下载数据
为了说明这个不平衡的数据集问题,我们将使用Ronny Kohavi和Barry Becker(数据挖掘和可视化,Silicon Graphics)从1994年人口普查局数据库中提取的数据。预测任务是确定一个人的年收入是否超过 50 万美元。您可以从以下链接下载数据集:
成人人口普查收入
根据人口普查数据预测收入是否超过 50K<>K/年
www.kaggle.com
2.1 预处理数据
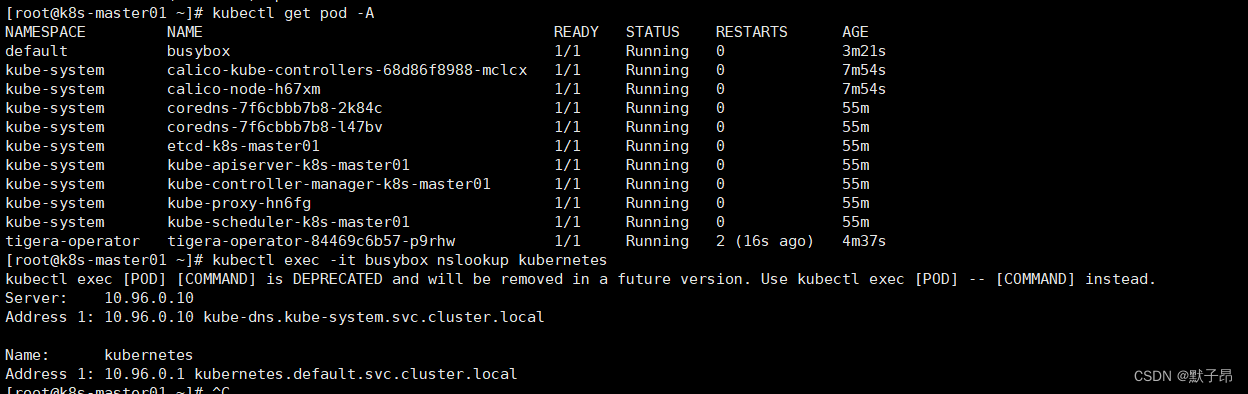
# Load the data the check first lines
import pandas as pd
df = pd.read_csv("adult.csv")
df.head()

然后,我们将删除缺失值和分析不需要的值。
# Drop missing values
import numpy as np
df[df=='?']=np.nan
new_df=df.dropna(axis=0)
# Drop the fnlwgt column which is useless for later analysis
new_df = new_df.drop('fnlwgt', axis=1)
我们还将收入值替换为 0 (≤50K) 和 1(>50K)。
new_df['income'].replace({'<=50K':0,'>50K':1},inplace=True)
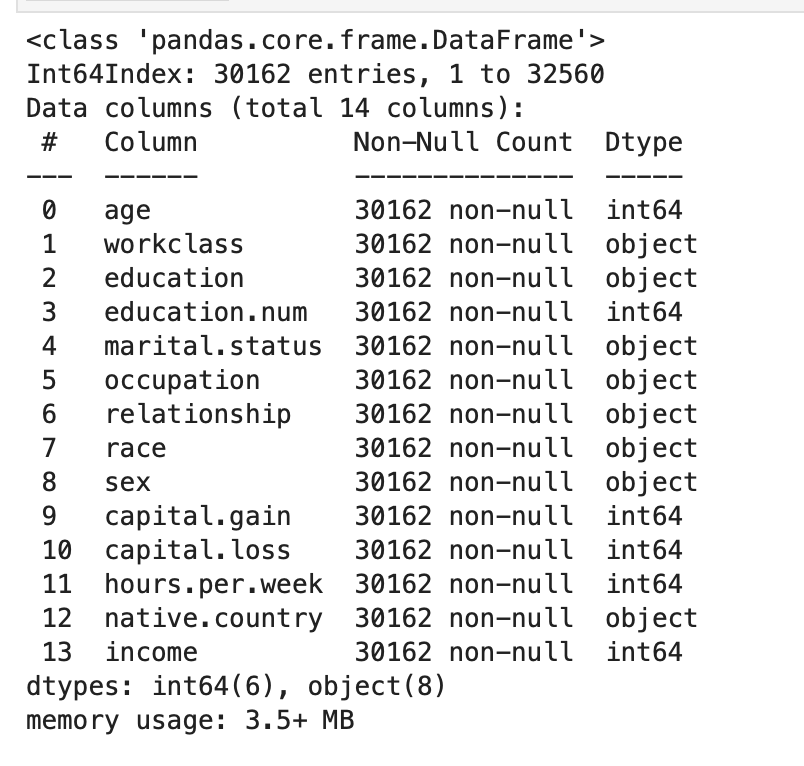
# Examine if there are missing value
new_df.info()
2.2 One-Hot码
每条记录有几个非数字特征。通常,学习算法期望输入是数字,这需要转换非数字特征(称为分类变量)。此处使用独热编码方案转换分类变量。
# 使用 sklearn 对“features_log_minmax_transform”数据进行独热编码。OneHotEncoder# 分类列的名称
cat_feats = new_df.dtypes[new_df.dtypes=='object'].index.tolist()cat_idx = [new_df.columns.get_loc(col) for col in cat_feats]
#
从 sklearn.preprocessing import 创建编码器 OneHotEncoder
编码器 = OneHotEncoder
(handle_unknown=“ignore”, sparse=False)
# 在分类特征上拟合和变换编码器 encoded_cat_feats = encoder.fit_transform(new_df.loc[:, cat_feats])# 获取原始列
中每个类别的唯一值 unique_values = [new_df[col].unique()
for col in cat_feats]# 为编码的分类特征生成特征
名称 encoded_cat_feats_name = []
对于 i,枚举 (cat_feats) 中的 col:对于 unique_values[i]中的值:
encoded_cat_feats_name.append(f“{col}_{value}”)
#
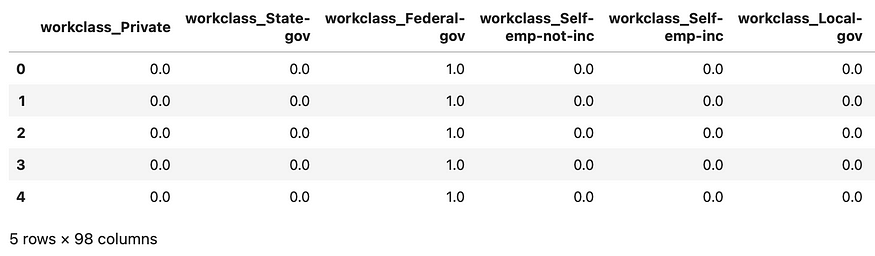
创建编码的分类特征数据帧
encoded_cat_feats_df = pd。DataFrame(encoded_cat_feats, columns=encoded_cat_feats_name)encoded_cat_feats_df.head()
# 定义数字列名
列表 num_col = [col 表示 new_df.columns 中的 col,如果 col 不在 cat_feats
中]] 提取仅包含数字特征的数据帧 num_feats_df = new_df[num_col].reset_index()
# 将数字和编码的分类特征
连接在一起
df_encoding = pd.merge(num_feats_df, encoded_cat_feats_df, left_index=True, right_index=True).drop('index', axis=1)df_encoding.head()
为了显示数据集的偏斜程度,我们可以运行以下代码:
income_1_count = df_encoding[df_encoding['收入'] == 1]。shape[0] print(“收入 = 1 的数据点数:”, income_1_count) income_0_count = df_encoding[df_encoding['收入'] == 0]。shape[0] print(“收入 = 0 的数据点数:”, income_0_count) --> 结果:收入 = 1 的数据点数:7508 收入 = 0 的数据点数: 22654
最后,我们将编码的数据保存到新的CSV文件中。
df_encoding.to_csv('encoded_data.csv', index=False)
三、总结
到目前为止,我们所做的是使我们的数据集为分类任务做好准备。接下来,我们将使用多层感知器(MLP)对一个人的收入是否超过50K进行分类。敬请👀关注
达门·
·