简介
数据库管理系统 (DBMS)是允许用户与数据库交互的计算机程序。DBMS允许用户控制对数据库的访问、写入数据、执行查询以及执行与数据库管理相关的任何其他任务。
为了执行这些任务,DBMS必须有某种底层模型来定义数据的组织方式。关系模型是一种组织数据的方法,自20世纪60年代末首次设计以来,它在数据库软件中得到了广泛的应用,以至于在撰写本文时,最受欢迎的前5种DBMS中有4种都是关系模型。
概念上的这篇文章概述了历史的关系模型,关系数据库如何组织数据,以及如何使用它们。
关系模型的历史
数据库是对信息或数据进行逻辑建模的集群。任何数据集合都是数据库,无论它以何种方式或在何处存储。甚至一个包含工资单信息的文件柜也是一个数据库,医院病人表单的堆栈或散布在多个位置的公司客户信息的集合也是数据库。在用计算机存储和管理数据成为普遍做法之前,像这样的物理数据库是需要存储信息的政府和商业组织唯一可用的数据库。
大约在20世纪中叶,计算机科学的发展使机器具有了更强的处理能力,以及更大的本地和外部存储容量。这些进步使计算机科学家开始认识到这些机器在存储和管理越来越多的数据方面的潜力。
然而,当时还没有任何理论可以解释计算机如何以有意义的、合乎逻辑的方式组织数据。在机器上存储未排序的数据是一回事,但要设计出能够以一致、实用的方式添加、检索、排序和管理数据的系统则要复杂得多。对存储和组织数据的逻辑框架的需求导致了许多关于如何利用计算机进行数据管理的建议。
早期的数据库模型是层次模型,其中数据被组织成树状结构,类似于现代的文件系统。下面的例子展示了用于动物分类的分层数据库的部分布局:
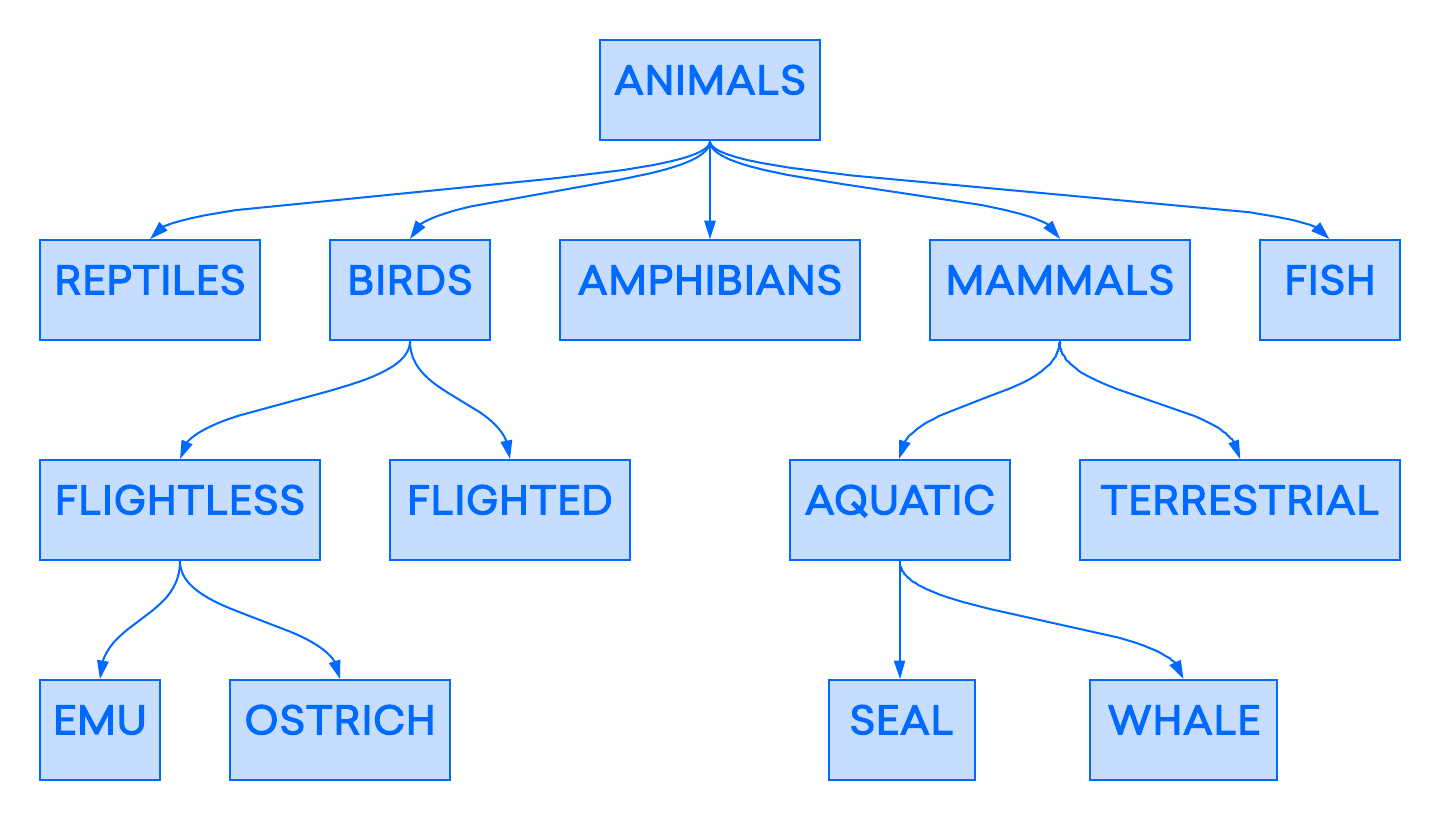
层次模型在早期的数据库管理系统中得到了广泛的实现,但它也被证明有些不灵活。在这个模型中,即使单个记录可以有多个“子”,但每个记录在层次结构中只能有一个“父”。因此,这些早期的分层数据库仅限于表示“一对一”和“一对多”关系。缺乏“多对多”关系可能会在处理需要关联多个父节点的数据点时产生问题。
20世纪60年代末,在IBM工作的计算机科学家埃德加·f·科德(Edgar F. Codd)设计了数据库管理的关系模型。Codd的关系模型允许单个记录与多个表关联,从而支持数据点之间的“多对多”关系以及“一对多”关系。在设计数据库结构时,这比其他现有模型提供了更多的灵活性,也意味着关系数据库管理系统(RDBMS)可以满足更广泛的业务需求。
Codd提出了一种管理关系型数据的语言,称为Alpha,它影响了后来数据库语言的发展。科德在IBM的两个同事,唐纳德·钱伯林和雷蒙德·博伊斯,创造了一种受阿尔法启发的语言。他们将这门语言命名为SEQUEL,它是(Structured English Query Language)的缩写,但是由于现有的商标,他们将这门语言的名称缩短为SQL(Structured Query Language),更正式的说法是结构化查询语言。
由于硬件的限制,早期的关系型数据库仍然很慢,过了一段时间才得到广泛应用。但是到20世纪80年代中期,Codd的关系模型已经在IBM及其竞争对手的许多商业数据库管理产品中实现。这些厂商也效仿IBM的开发和实施自己的SQL方言。到1987年,美国国家标准协会(American National Standards Institute)和国际标准化组织(International Organization for Standardization)都批准并发布了SQL的标准,巩固了SQL作为公认的RDBMS管理语言的地位。
关系模型在多个行业中的广泛使用使其成为公认的数据管理的标准模型。尽管近年来出现了各种NoSQL数据库,关系数据库仍然是存储和组织数据的主要工具。
关系型数据库如何管理数据
现在您对关系模型的历史有了大致的了解,让我们仔细看看模型是如何组织数据的。
关系模型中最基本的元素是关系(relations),用户和现代RDBMS将其视为表(table)。关系是一组元组(tuples)或表中的行,每个元组共享一组属性(attributes)或列:
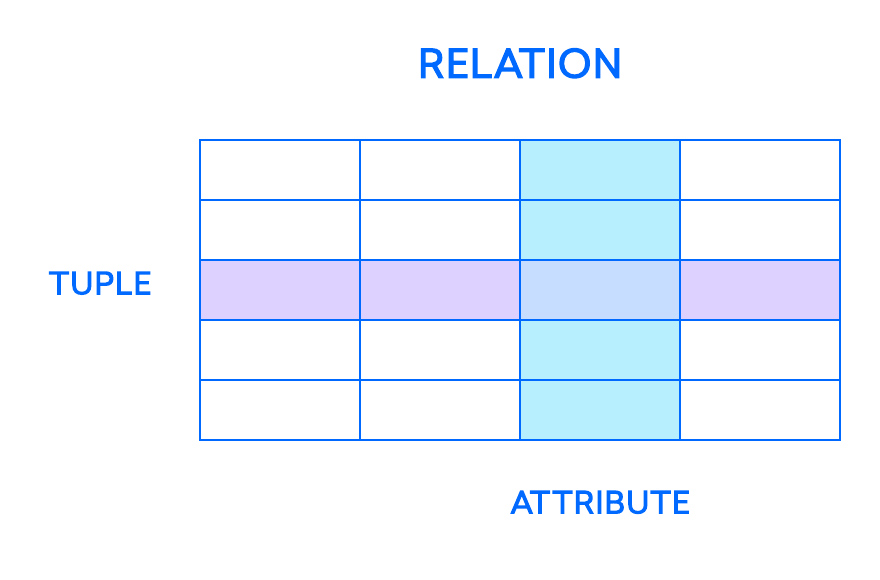
列是关系数据库中最小的组织结构,表示定义表中记录的各个方面。因此,它们的更正式的名称是属性。你可以将每个元组看作是表中保存的任何类型的人、对象、事件或关联的唯一实例。这些例子可能是公司的员工、在线业务的销售额或实验室测试结果。例如,在一个保存学校教师员工记录的表中,元组可能具有诸如name、subjects、start_date等属性。
当创建列时,你需要指定一个数据类型来指定该列允许哪些类型的条目。关系数据库管理系统通常实现自己独特的数据类型,这些数据类型与其他系统中的类似数据类型不能直接互换。一些常见的数据类型包括日期、字符串、整数和布尔值。
在关系模型中,每个表包含至少一列,可以用来唯一标识每一行,称为主键。这很重要,因为这意味着用户不需要知道他们的数据在机器上的物理存储位置;相反,它们的DBMS可以跟踪每条记录,并临时返回它们。反过来,这意味着没有定义的逻辑顺序,记录和用户有能力回报他们的数据中他们想要的任何订单或通过任何过滤器。
如果你有两个表想要相互关联,一种方法是使用外键。外键本质上是一个表(父表)主键的副本,插入到另一个表(子表)的一列中。下面的示例突出了两个表之间的关系,一个用于记录关于公司员工的信息,另一个用于跟踪公司的销售。在这个例子中,EMPLOYEES表的主键被用作SALES表的外键:

如果想向子表添加一条记录,而输入到外键列的值在父表的主键中不存在,那么插入语句将无效。这有助于维护关系级别的完整性,因为两个表中的行总是正确关联的。
关系模型的结构元素有助于数据存储在一个有组织的方式,但存储数据仅仅是有用的,如果你可以检索它。要从RDBMS中检索信息,你可以发出一个查询,即对一组信息的结构化请求。如前所述,大多数关系型数据库使用SQL来管理和查询数据。SQL允许您使用各种子句、谓词和表达式过滤和操作查询结果,从而可以精确地控制将出现在结果集中的数据。
关系数据库的优点和局限性
了解了关系数据库的基本组织结构后,让我们考虑一下它们的一些优点和缺点。
今天,SQL和数据库,实现它在几个方面偏离科德的关系模型。例如,Codd的模型规定表中的每一行都应该是唯一的,而出于实用性的考虑,大多数现代关系型数据库都允许重复行。有一些不考虑关系数据库SQL数据库是真的如果他们不遵守每个科德的规范关系模型。实际上,任何使用SQL并且至少在某种程度上遵循关系模型的DBMS都可能被称为关系数据库管理系统(relational database management system)。
虽然关系型数据库迅速流行起来,但随着数据变得越来越有价值,企业开始存储更多的数据,关系型模型的一些缺点开始变得明显。首先,它可能很难规模水平关系数据库。水平扩展,或称向外扩展,是指向现有堆栈中添加更多的机器,以分散负载,并允许更多流量和更快的处理。这通常与垂直扩展相对,后者涉及升级现有服务器的硬件,通常是通过增加更多的RAM或CPU。
很难水平扩展一个关系型数据库的原因是,关系型模型的设计是为了保证一致性,这意味着查询相同数据库的客户端总是会检索到相同的数据。如果要在多台机器上水平扩展关系型数据库,就很难保证一致性,因为客户端可能会将数据写入一个节点,而不会写入其他节点。在初始写入和其他节点更新以反映更改之间可能存在延迟,从而导致它们之间的不一致性。
RDBMS的另一个限制是关系模型被设计为管理结构化数据,或者与预定义的数据类型保持一致,或者至少以某种预定的方式组织的数据,使其易于排序和搜索。与个人电脑的传播和互联网的兴起在1990年代早期,然而,非结构化数据——如电子邮件、照片、视频等。——变得越来越普遍。
这并不是说关系数据库没有用处。相反,经过40多年的发展,关系模型仍然是数据管理的主导框架。它们的流行程度和寿命意味着关系数据库是一种成熟的技术,这本身就是它们的主要优势之一。有许多应用程序是为关系模型设计的,也有许多职业数据库管理员,他们是关系数据库方面的专家。对于那些想开始接触关系数据库的人来说,还有大量的纸质和在线资源可供选择。
关系数据库的另一个优点是几乎每个RDBMS都支持事务。事务由一个或多个单独的SQL语句组成,这些语句作为一个工作单元按顺序执行。事务是一种全有或全无的方法,这意味着事务中的每条SQL语句都必须有效;否则,整个事务将失败。在对多行或多表进行更改时,这对于确保数据完整性非常有用。
最后,关系数据库非常灵活。它们已被用于构建各种不同的应用程序,即使在数据量非常大的情况下也能高效地工作。SQL也非常强大,允许您动态添加和更改数据,以及在不影响现有数据的情况下更改数据库模式和表的结构。
总结
由于其灵活性和数据完整性的设计,关系数据库在被提出50多年后仍然是管理和存储数据的主要方式。即使近年来各种NoSQL数据库兴起,理解关系模型以及如何使用RDBMS对于任何想要构建利用数据力量的应用程序的人来说都是关键。