论文:Adding Conditional Control to Text-to-Image Diffusion Models
代码:lllyasviel/ControlNet
简单来说ControlNet希望通过输入额外条件来控制大型图像生成模型,使得图像生成模型根据可控。
1. 动机
当前文生图任务中会出现如下问题:
- 特定任务中往往无法获取大规模的训练数据
- 对于大部分人来说,并没有大规模计算集群资源
- 各种图像生成任务中会有多种问题定义、用户控制条件、图像标注的形式
从而造成当前基于prompt控制的模型并不能满足特定业务需求。ControlNet的提出就是为了解决上面几个问题。
此外,我们在使用Stable Diffusion通过prompt生成图片时,很多时候我们希望能够生成一些固定姿态的物体,如下图所示,可能我们就想生成一只和最左边参考图像中鹿的姿态一摸一样的鹿,很显然如果直接通过prompt很难控制,这里主要有两个难点:
- 如何非常准确详细的描述左边鹿的姿态
- 即使参考图片鹿的姿态被描述的很准确,将prompt送入到模型中,依然无法控制姿势不变

而通过controlNet即可非常方便的解决这个问题,如下图所示,只需使用canny边缘检测,将参考图片的物体的边缘识别出来,然后将边缘轮廓图作为条件输入到模型中,即可轻松生成与参考图像姿势一样的鹿,同时通过prompt来控制鹿的颜色

当然,ControlNet功能强大,其输入条件可以是边缘轮廓图、手绘轮廓图、语义分割图、深度图等,从而使得控制变得更加简单。
2. ControlNet原理
如图1左图所示,在一个扩散模型中,如果不加ControlNet的扩散模型,其中原始的神经网络
F
\mathcal{F}
F 输入
x
x
x 获得
y
y
y,其中
Θ
\mathcal{\Theta}
Θ 是扩散模型的参数。
y
=
F
(
x
;
Θ
)
y={\mathcal{F}}(x;\Theta)
y=F(x;Θ)
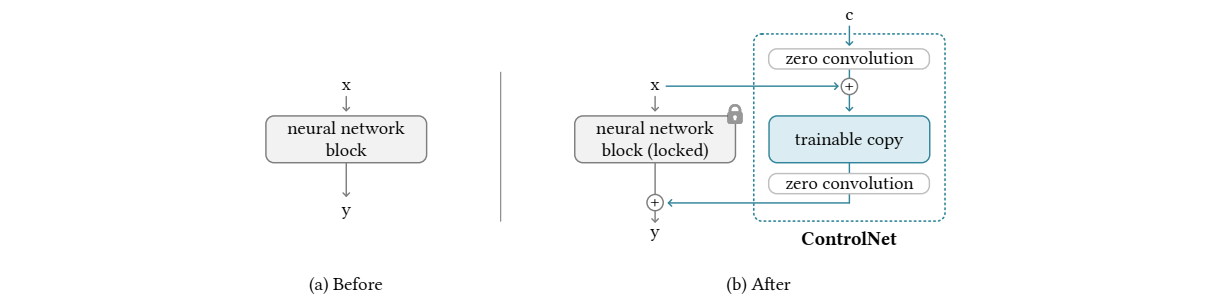
图1的右图展示了如何在原始神经网络上 F \mathcal{F} F 上构建ControlNet;ControlNet 将一个大型扩散模型的权重克隆为一个“可训练副本”和一个“锁定副本”:锁定的副本 (locked) 保留了从数十亿张图像中学习到的网络能力,而可训练副本 (trainable copy) 在特定任务的数据集上进行训练,以学习条件控制。经过上图所示的改变后,神经网络的输出变成如下式所示:
y
c
=
F
(
x
;
Θ
)
+
Z
(
F
(
x
+
Z
(
c
;
Θ
z
1
)
;
Θ
c
)
;
Θ
z
2
)
y_{c}={\mathcal{F}}(x;\Theta)+{\mathcal{Z}}({\mathcal{F}}(x+{\mathcal{Z}}(c;\Theta_{z1});\Theta_{c});\Theta_{z2})
yc=F(x;Θ)+Z(F(x+Z(c;Θz1);Θc);Θz2)
其中
Z
\mathcal Z
Z 是图中所示的零卷积网络,
Θ
z
1
\Theta_{z1}
Θz1和
Θ
z
2
\Theta_{z2}
Θz2分别是两个零卷积的参数。即trainablec copy的输入是原始输入
x
x
x加上控制条件
c
c
c经过零卷积的输出。而整个模型的输出是locked copy输出加上trainable copy的输出经过零卷积的结果。
所谓的零卷积层 Z \mathcal Z Z是指初始化weight和bias都为0的卷积层
初始化之后未经训练的ControlNet参数如下式所示;由于零卷积初始化的weight和bias都是零,所以第一个式子为0,带入到第二个式子中,由于可训练的副本是拷贝过来的,在未开始训练时,
Θ
c
\Theta_c
Θc是和原始网络参数
Θ
\Theta
Θ相同的;同理可以得到第三个式子为0
{
Z
(
c
;
Θ
z
1
)
=
0
F
(
x
+
Z
(
c
;
Θ
z
1
)
;
Θ
c
)
=
F
(
x
;
Θ
c
)
=
F
(
x
;
Θ
)
Z
(
F
(
x
+
Z
(
c
;
Θ
z
1
)
;
Θ
c
)
;
Θ
z
2
)
=
Z
(
F
(
x
;
Θ
c
)
;
Θ
z
2
)
=
0
\left\{\begin{array}{l l}{{\mathcal{Z}}(c;\Theta_{z1})=0}\\ {{{\mathcal{F}}(x+{\mathcal{Z}}(c;\Theta_{z1});\Theta_{c})={\mathcal{F}}(x;\Theta_{c})={\mathcal{F}}(x;\Theta)}}\\ {{{\mathcal{Z}}({\mathcal{F}}(x+{\mathcal{Z}}(c;\Theta_{z1});\Theta_{c});\Theta_{z2})={\mathcal{Z}}({\mathcal{F}}(x;\Theta_{c});\Theta_{z2})=0}}\end{array}\right.
⎩
⎨
⎧Z(c;Θz1)=0F(x+Z(c;Θz1);Θc)=F(x;Θc)=F(x;Θ)Z(F(x+Z(c;Θz1);Θc);Θz2)=Z(F(x;Θc);Θz2)=0
这表明ControlNet未经训练的时候,输出为0,那加到原始网络上的数字也是0。这样对原始网络是没有任何影响的,就能确保原网络的性能得以完整保存。之后ControlNet训练也只是在原始网络上进行优化,这样可以认为和微调网络是一样的。
3. ControlNet inStable Diffusion Model
3.1 网络结构
ControlNet对Stable Diffusion的控制如下图所示,可以看到控制Stable Diffusion的过程是只将Unet的Encoder部分复制训练,然后通过skip connection与decoder部分进行连接。
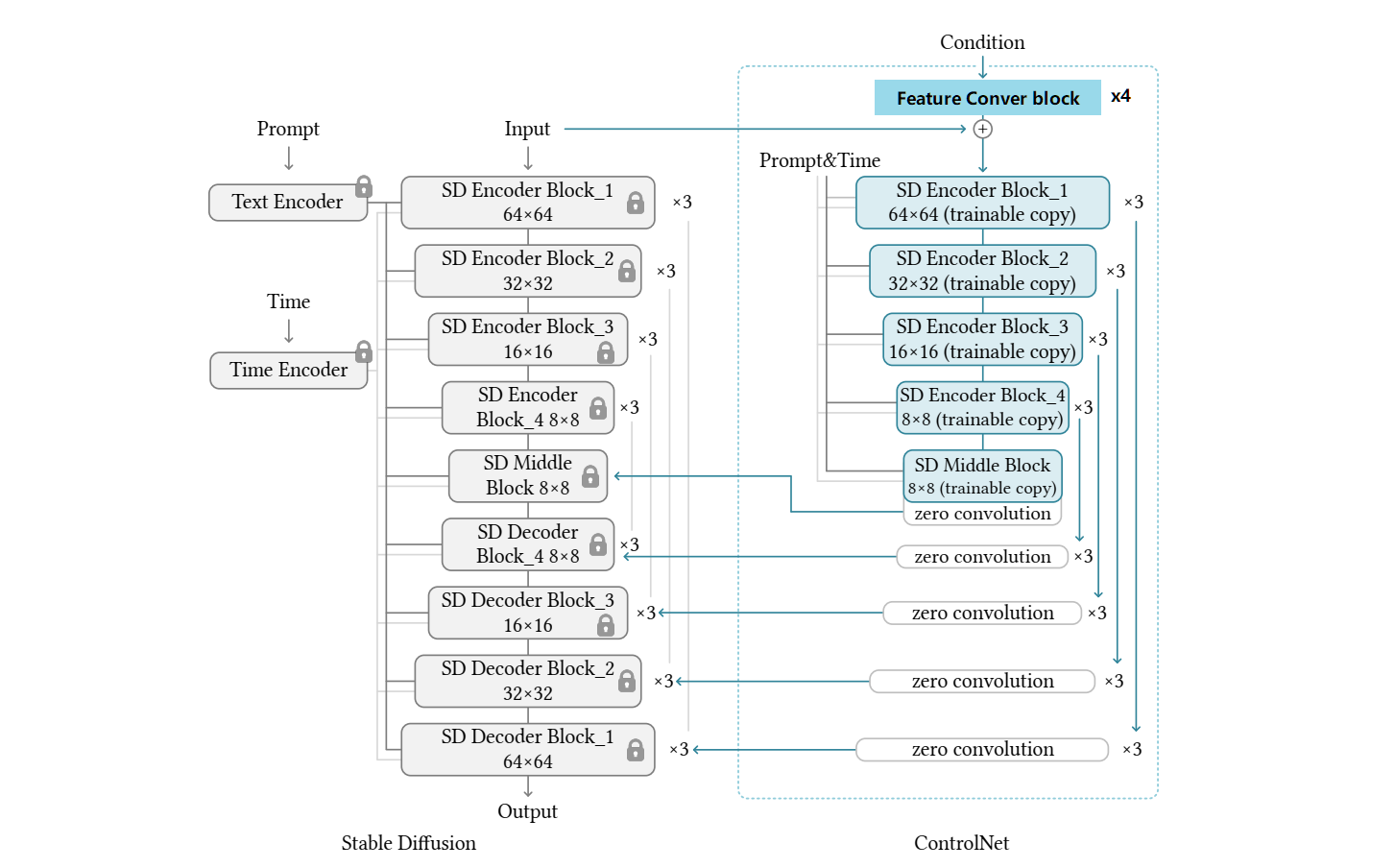
注意,由于Stable Diffusion 1.x中的Unet输入尺寸是64*64*4,因此输入的条件condition首先要通过Feature Convert Block将输入的图像条件,转换成64*64尺寸的特征图,这个特征转换层是一个四层卷积神经网络,卷积核为4×4,步长为2,通道16,32,64,128,初始化为高斯权重。这个网络训练过程是和整个ControlNet进行联合训练。
以上这种网络结构在计算方面是非常高效的,由于只复制了Unet Encoder部分,即只有Unet encoder部分参与训练,这样与原始网络比较起来省略了一半的梯度计算。
3.2 训练过程
如下式所示,将原始SD的损失函数稍微改动下,就可得到ControlNet的损失函数,仍然是预测噪声和真实噪声的L2损失,只是在预测噪声时,新增了与具体任务相关的
c
f
c_f
cf条件,
c
t
c_t
ct是prompt条件。
L
=
E
z
0
,
t
,
c
t
,
c
f
,
ϵ
∼
N
(
0
,
1
)
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
,
c
t
,
c
f
)
)
∥
2
2
]
\left.\mathcal{L}=\mathbb{E}_{\boldsymbol{z}_0, t, \boldsymbol{c}_t, \boldsymbol{c}_{\mathrm{f}}, \epsilon \sim \mathcal{N}(0,1)}\left[\| \epsilon-\epsilon_\theta\left(z_t, t, \boldsymbol{c}_t, \boldsymbol{c}_{\mathrm{f}}\right)\right) \|_2^2\right]
L=Ez0,t,ct,cf,ϵ∼N(0,1)[∥ϵ−ϵθ(zt,t,ct,cf))∥22]
训练过程中将50%的文本提示
c
t
c_t
ct 随机替换为空字符串。这样有利于ControlNet网络从控制条件中识别语义内容。当Stable Diffusion没有prompt的时候,编码器能从输入的控制条件中获得更多的语义来代替prompt,类似于classifier-free guidance。
此外作者还针对不同情况提出两种改进的训练方式:
- 小规模训练
当计算资源或者训练数据受限时,作者发现断开部分ControlNet和SD的skip connection可以加速收敛,如上图所示,默认是ControlNet和SD的Middle Block以及Decoder Block的1,2,3,4连接,如果断开1,2,3,4连接,只和Middle Block连接可以加快收敛。当模型的结果和控制条件有关联时,再将断开的连接重新连上,从而得到更精准的控制 - 大规模训练
当计算资源充足,训练数据充足(至少一百万)时,首先进行ControlNet训练,大概5万步,然后解锁SD部分的模型,让两者进行联合训练,这会使得模型在特定任务上表现更好
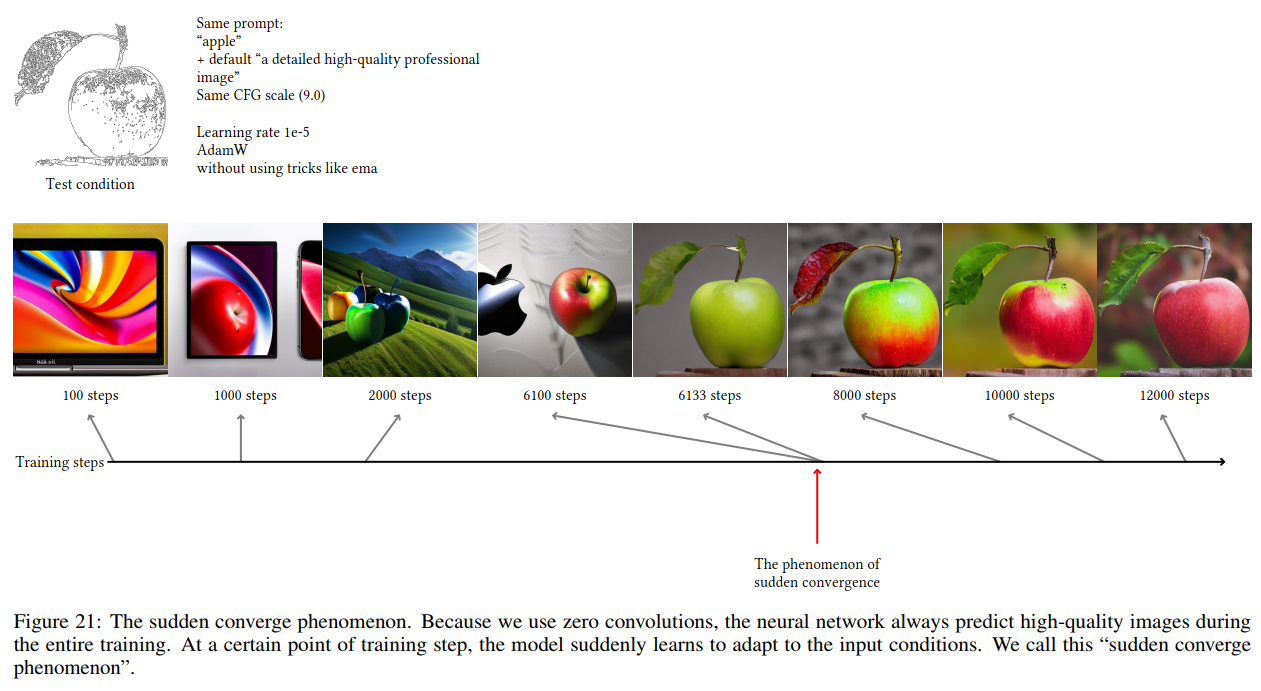
此外作者发现训练过程会出现突然收敛的情况,如下图所示
4. 生成效果
ControlNet的控制条件很多,论文里列举了在Canny Edge,Hough Line,HED Boundary,User Sketching,Human Pose,Semantic Segmentation,Depth,Normal Maps,Cartoon Line Drawing等条件上的控制生成结果。
参数配置如下:
- CFG-scale at 9.0
- sampler is DDIM
- sample 20 steps
同时使用了四种类型的prompt来分别控制:
- No prompt:空字符串
- Default prompt:a professional, detailed, high-quality image
- Automatic prompt:通过BLIP生成的prompt
- User prompt:用户自定义prompt
具体生成效果如下:
(1)Controlling Stable Diffusion with Canny edges(边缘图控制)

(2) Controlling Stable Diffusion with Hough lines (M-LSD) (直线图控制)

(3) Controlling Stable Diffusion with Human scribbles (手绘图控制)

(4)Controlling Stable Diffusion with HED boundary map

(5)Controlling Stable Diffusion with Openpose (人体姿态控制)
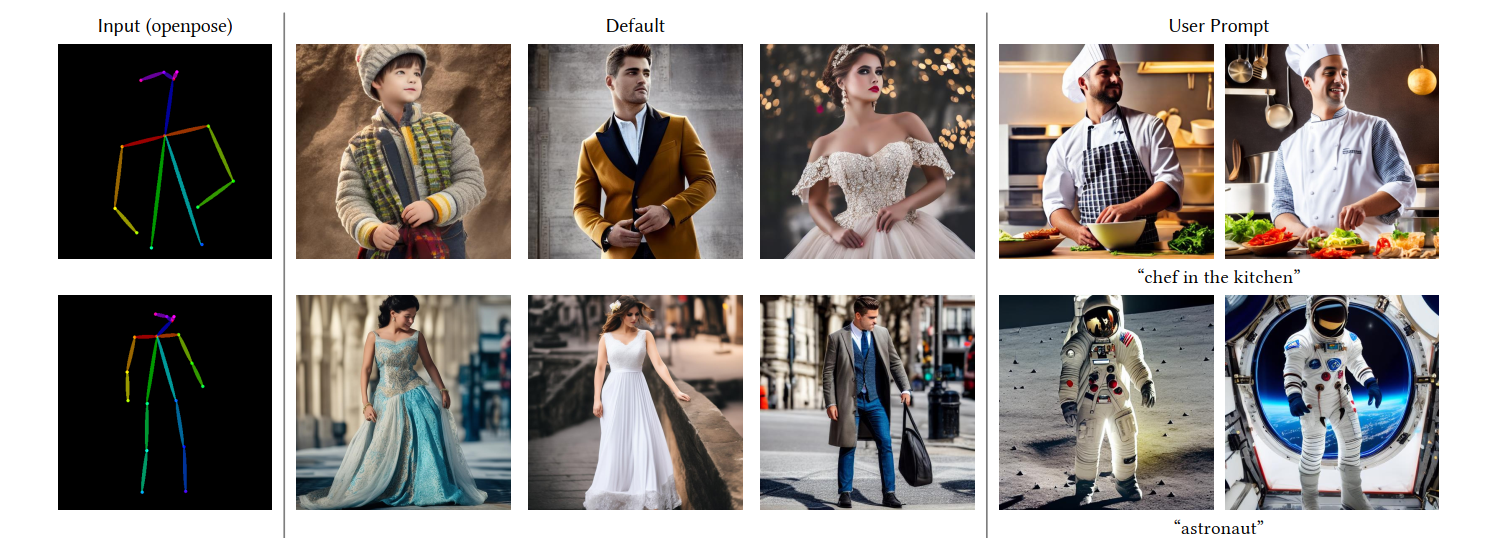
(6)Controlling Stable Diffusion with ADE20K segmentation map (分割图控制)

(7)通过卡通线稿图控制

(8)对于一些简单的物体,ControlNet会获得非常精准的控制

5. 参考
https://arxiv.org/abs/2302.05543