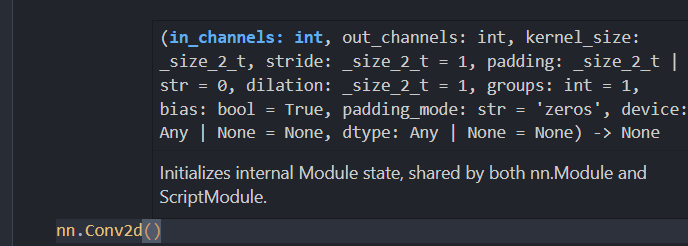
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True,padding_mode='zeros')
参数介绍:
-
in_channels:卷积层输入通道数 -
out_channels:卷积层输出通道数 -
kernel_size:卷积层的卷积核大小 -
padding:填充长度 -
stride:卷积核移动的步长 -
dilation:是否采用空洞卷积 -
groups:是否采用分组卷积 -
bias:是否添加偏置参数 -
padding_mode:padding的模式
如果输入大小为:数量N即批处理大小(batch size),输入通道数C_in,输入高度H_in,输入宽度C_in。输出大小为:数量N,输出通道数C_out,输出高度H_out,输出宽度C_out。
i
n
p
u
t
:
(
N
,
C
i
n
,
H
i
n
,
W
i
n
)
o
u
t
p
u
t
:
(
N
,
C
o
u
t
,
H
o
u
t
,
W
o
u
t
)
input: \quad (N, C_{in},H_{in},W_{in}) \\ output: \quad (N,C_{out}, H_{out}, W_{out})
input:(N,Cin,Hin,Win)output:(N,Cout,Hout,Wout)
之间的转换为:
(
N
i
,
C
o
u
t
)
=
b
i
a
s
(
C
o
u
t
)
+
∑
k
=
0
C
i
n
−
1
w
e
i
g
h
t
(
C
o
u
t
,
k
)
∗
(
N
i
,
k
)
(N_i,C_{out}) = bias(C_{out}) + \sum_{k=0}^{C_{in}-1}weight(C_{out},k) * (N{i},k)
(Ni,Cout)=bias(Cout)+k=0∑Cin−1weight(Cout,k)∗(Ni,k)
H o u t = [ H i n + 2 ∗ p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] ∗ ( k e r n a l s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_{out} = [ \frac {H_{in} + 2 * padding[0] - dilation[0] *(kernal_size[0] - 1) - 1}{stride[0]} + 1] Hout=[stride[0]Hin+2∗padding[0]−dilation[0]∗(kernalsize[0]−1)−1+1]
W o u t = [ W i n + 2 ∗ p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] ∗ ( k e r n e l s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 ] W_{out} = [ \frac {W_{in} + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1} {stride[1]} + 1] Wout=[stride[1]Win+2∗padding[1]−dilation[1]∗(kernelsize[1]−1)−1+1]
对于二维简化的:
W
i
n
,
H
i
n
输入的宽、高
W
o
u
t
,
H
o
u
t
输出的宽,高
F
卷积核的大小
S
步长
P
边界填充
W_{in},H_{in} \quad 输入的宽、高 \\ W_{out},H_{out} \quad 输出的宽,高 \\ F \quad 卷积核的大小 \\ S \quad 步长 \\ P \quad 边界填充
Win,Hin输入的宽、高Wout,Hout输出的宽,高F卷积核的大小S步长P边界填充
那么输出的宽、高为:
W
o
u
t
=
W
i
n
−
F
W
+
2
P
S
+
1
H
o
u
t
=
H
i
n
−
F
H
+
2
P
S
+
1
W_{out} = \frac {W_{in} - F_{W} + 2P} S + 1 \\ H_{out} = \frac {H_{in} - F_{H} + 2P} S + 1
Wout=SWin−FW+2P+1Hout=SHin−FH+2P+1
在pytorch中的使用
- 直接使用(不常见)
import torch
import torch.nn as nn
# https://www.bilibili.com/video/BV1644y1h7LN/?spm_id_from=333.337.search-card.all.click&vd_source=13dfbe5ed2deada83969fafa995ccff6
# 输入通道数
in_channels = 1
# 输出通道数
out_channels = 1
# 批处理大小
batch_size = 1
# 卷积核大小 (3,3)
kernel_size = 3
# 输入规格
input_size = [batch_size, in_channels, 4, 4]
# nn.Conv2d使用,其他默认值
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size)
# 随机输入特征图
input_feature_map = torch.randn(input_size)
# 打印输入特征图形状
print(input_feature_map.shape)
# 求出输出特征图
output_feature_map = conv_layer(input_feature_map)
# 打印出卷积核的规格
print(conv_layer.weight.shape)
# weight == out_channel * in_channel * height * weight
# 打印输出特征图大小
print(output_feature_map.shape)
输出:
torch.Size([1, 1, 4, 4])
torch.Size([1, 1, 3, 3])
torch.Size([1, 1, 2, 2])
- 封装为类的形式
import torch
from torch import nn
# 定义一个同样操作的卷积类
class Foo(nn.Module):
def __init__(self, in_channel, out_channel):
super(Foo,self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3)
)
def forward(self, x):
return self.layer(x)
# 实例化一个
conv2 = Foo(1,1)
# 输出特征图, input_feature_map_2 和 input_feature_map是相同的值
output_feature_map_2 = conv2(input_feature_map_2)
print(output_feature_map_2)
输出:
tensor([[[[ 0.5144, 0.0672],
[ 0.2169, -0.0591]]]], grad_fn=<ConvolutionBackward0>)
可以观察到,这两个操作相同但是结果值却不相同。这是因为虽然两者实现了相同的卷积操作,但由于它们的初始化和权重值的不同,因此输出结果可能不完全一致。 另外,对于卷积操作的结果,输出的张量形状可能会有所不同,但数值内容应该是相似的。如果希望确保两种方式得到的输出结果完全一致,可以尝试使用相同的初始化参数,并确保权重值相同。