1 、 数据排序 sort_values()函数
by:要排序的名称或名称列表,
sorted_df = df.sort_values(by='Age',ascending=False) 由大到小排序;
sorted_df = df.sort_values(by='Age') 由小到大排序;
# 创建一个示例数据帧
data = {'Name': ['Tom', 'Nick', 'John', 'Amy'],
'Age': [25, 29, 35, 21],
'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
# 按照Age列进行排序
sorted_df = df.sort_values(by='Age')
sorted_df.to_csv('test1.csv')
print(sorted_df)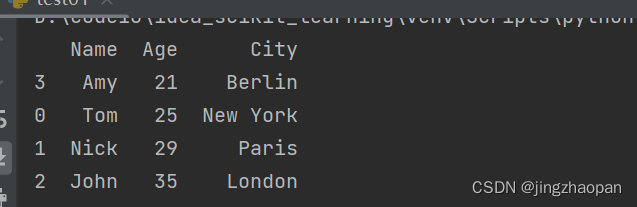
2 把字典,列表,迭代器 数据写入csv文件,to_csv() 函数
方式1:
lis_offer, lis_revenue = self.get_offer_revenue()
data = {'offerid': lis_offer,
'revenue': lis_revenue
}
result = pd.DataFrame(data)
result.to_csv(data_path + start_time + "offer_revenue.csv")方式2:
lis_offer, lis_revenue = self.get_offer_revenue()
x_offer = np.array(lis_offer).reshape(-1, 1)
x_revenue = np.array(lis_revenue).reshape(-1, 1)
result = np.concatenate((x_offer, x_revenue), axis=1)
result = pd.DataFrame(result, columns=['offerid', 'revenue'])
result.to_csv(data_path + start_time + "offer_revenue.csv") def read4(self):
active_score_lit = []
li = ['90-100.tsv']
for i in li:
with open(i, mode='r+', encoding='utf-8') as file:
for i in file.readlines():
aa = json.loads(i)
active_score_lit.append(aa)
data = pd.DataFrame(active_score_lit) access_cat ... conv_score
0 {"IAB9-5":7.32514399521715,"IAB9-30":7.3255896... ... NaN
1 {"IAB9-30":1.2948738821508443,"IAB1":1.2948738... ... NaN
2 {"IAB9-5":6.751567110240471,"IAB9-30":7.859169... ... NaN
3 NaN ... 2013.6735
4 {"IAB1":17.93415291298408,"IAB5":3.91909391671... ... NaN
方式3:
class GetOfferid():
def get_numpage(self):
'''
通过请求 task任务接口 num:
:return:
输出 迭代器:
offerid, strategy, country, sendSuccessCount, deviceCount
'''
for page in range(1, 15+1):
url1 = host + "api/admin/v3/task/page?pageNum="+str(page)+"&pageSize=10"
res = (requests.get(url=url1, headers=header, verify=False).json())['result']['records']
time.sleep(1)
for result in res:
yield result['offerId'],result['strategy'],result['country'],result['sendSuccessCount'],result['deviceCount']
def write_csv(self):
lis_deviceCount = self.get_numpage()
# 迭代器 generator for i in lis_deviceCount: 遍历结果: ('9702', 'vba', 'IN', 155917, 48412574)
result = pd.DataFrame(lis_deviceCount, columns=['offerid', 'strategy', 'country', 'sendSuccessCount', 'deviceCount'])
result.to_csv(filename)方式3: 已存在表格中写入一列数据:
df = pd.read_csv(filename)
df['expect_cvr'] = self.get_expect_cvr()
df.to_csv(filename, index=False, encoding="utf_8_sig")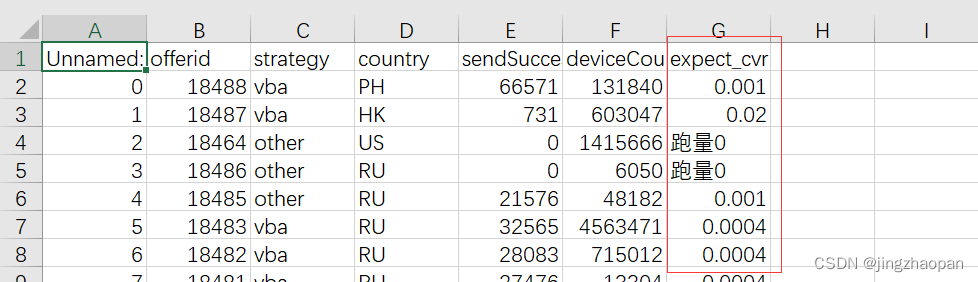
方式4: 已存在表格中写入几行数据:
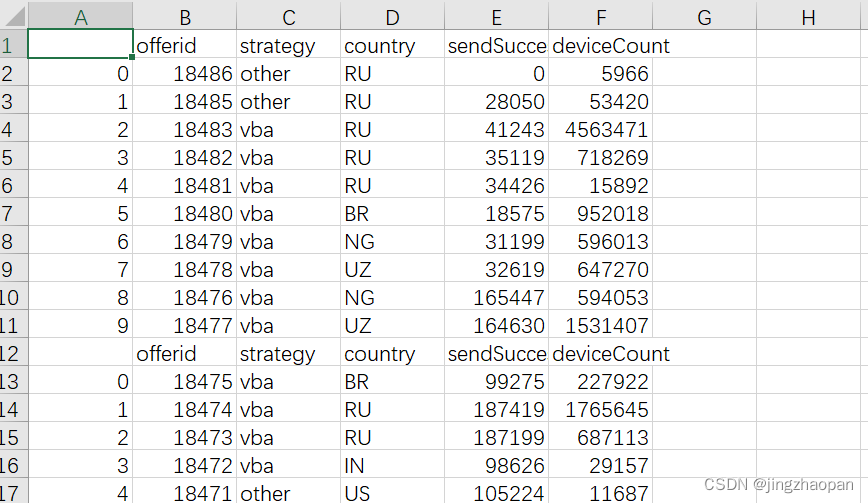
原数据:

追加写入 result.to_csv(filename, mode='a'), 加上mode='a',便可以追加写入数据;
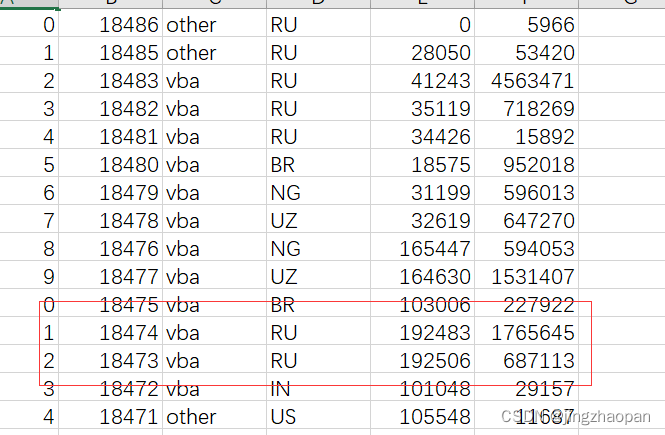
追加写入 header=False, 不写出列名;
result.to_csv(filename, mode='a', header=False)
3 查询 内容
3-0 查询单行数据【索引】,遍历所有行的数据
# 创建一个示例数据帧
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],
'Age': [25, 29, 35, 21],
'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
print(df[2:3])
print("``````````````````````")
for rr in df.values:
print(rr)
Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````
Name Age City
2 John 35 London
``````````````````````
['Tom' 25 'New York']
['Nick' 29 'Paris']
['John' 35 'London']
['Nick' 21 'Berlin']3-1根据内容查询出对应的索引: np.flatnonzero(df['Name'] == 'Nick')
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],
'Age': [25, 29, 35, 21],
'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
d = np.flatnonzero(df['Name'] == 'Nick')
print(d)
Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````
[1 3]3-2根据内容查询出对应的行的内容: df.loc[df['Name'] == 'Nick']
data = {'Name': ['Tom', 'Nick', 'John', 'Nick'],
'Age': [25, 29, 35, 21],
'City': ['New York', 'Paris', 'London', 'Berlin']}
df = pd.DataFrame(data)
print(df)
print("``````````````````````")
f = df.loc[df['Name'] == 'Nick']
print(f)
Name Age City
0 Tom 25 New York
1 Nick 29 Paris
2 John 35 London
3 Nick 21 Berlin
``````````````````````
Name Age City
1 Nick 29 Paris
3 Nick 21 BerlinDataFrame 增删改
2.3.1 行的操作
1.1 添加行
pd._append(new_series, ignore_index =True) ignore_index =True忽略标签意识
返回一个新的DataFrame
lis_dic2 = {
'offerId':[12078,18379,1817],
'click':[1663,18492024,6379911],
}
pd2 = pd.DataFrame(lis_dic2)
new_series = pd.Series([999,1000],index=['offerId','click'])
pd3 = pd2._append(new_series, ignore_index =True)1.2 修改行
pd.loc[行标签] = [列标签内容,列标签内容] x 表示要修改的行标签,填写所有内容不用添加标签
pd.locx[行位置] = [列位置内容,列位置内容,] x 表示要修改的行标签,填写所有内容不用添加标签
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd2.loc[2] = [1819,181918]1.3 删除行
pd.drop([x]), X表示要删除的行号,可以是多行,删除返回一个新的DataFrame
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 = pd2.drop([2])2.3.2 列的操作
1.1 新增/修改 列
方式1: df['列标签'] = 新列
方式2: pd.loc[:,'列标签'] =新列
如果DataFrame 不存在这一列,则新增一列; 如果DataFrame存在这一列则修改值;
new_result = DataFrame(result,columns=['sourceManager','sex','tel']) # 新增一个列
new_result['tel'] = ['15829041959','15829041969','15829041979','15829041989'] 新增这一列赋值;1.2 删除列
pd.drop([x],axis=1), X表示要删除的列,删除返回一个新的DataFrame
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd2.loc[:,'sourceManager'] = ['ber','amie','terch','lisi']
pd3 = pd2.drop(['click'],axis=1)DataFrame 数据查询
2.4.1 df.nlargest(n,columns) 按照columns 指定的列进行降序排序,并取前N行数据;
2.4.2 df.nsmallest(n,columns) 按照columns 指定的列进行升序排序,并取前N行数据;
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 = pd2.nsmallest(2,'click')2.4.3 按条件查询:
方式1: pd3 =pd2.loc[ 查询条件 ]
方式2: pd2.query(查询条件)
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
}
pd2 = pd.DataFrame(lis_dic2)
pd3 =pd2.loc[(pd2['click'] >1500)& (pd2['click'] < 6379912)]
pd4 = pd2.query('click > 1500 & click< 6379912')2.4.4 分组聚合
方式1:pd2.groupby(列标签,···). 列标签 . 聚合函数()
按指定列分组,并对分组数据的相应列进行相应的聚合操作;
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 安装sex 字段分组, 求 ‘click’字段平均值
pd4 = pd2.groupby('sex').click.mean()方式2:pd2.groupby(列标签,···).agg({'列标签':'聚合函数()',······})
按指定列分组,并对分组数据的相应列进行相应的聚合操作
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# # 安装sex 字段分组, 求 'offerId'的个数 和 ‘click’字段平均值
pd3 = pd2.groupby('sex').agg({'offerId':'count','click':'mean'})2.5 排序
2.5.1 将DataFrame 按照指定列的数据进行排序;ascending=False,降序,True,升序;
pd2.sort_values(by='列标签',ascending=False)
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 排序
pd3 = pd2.sort_values('click',ascending=False)2.5.2 将DataFrame 按照行标签进行排序;ascending=False,降序,True,升序;
pd2.sort_index(ascending=True)
lis_dic2 = {
'offerId':[12078,18379,1817,999],
'click':[1663,18492024,6379911,1000],
'sex':['A','B','A','B']
}
pd2 = pd.DataFrame(lis_dic2)
# 排序
pd4 = pd2.sort_index(ascending=True)