SQL Server 的查询优化器是一个基于成本的优化器。它为一个给定的查询分析出很多的候 选的查询计划,并且估算每个候选计划的成本,从而选择一个成本最低的计划进行执行。实际上, 因为查询优化器不可能对每一个产生的候选计划进行优化,所以查询优化器会在优化时间和查询 计划的质量之间进行一个平衡,尽可能的选择一个“最优”的计划。
所以,查询优化器成为 SQL Server 中最重要的一个组件,并且影响着 SQL Server 的性能。 选择正确或错误的执行计划意味着查询执行时间可能存在着毫秒的,几分钟,甚至几个小时之间 的差异。
了解查询优化的内部机制,可以帮助 DBA 和开发人员能够编写更好的查询,或者给查询优 化器提供信息使得它可以产生有效的执行计划。本系列文章讲述的查询优化器的内部运作的知识, 此外,还会告诉你如何使用查询优化器的相关信息进行性能诊断。
下面,我们首先来看看:查询优化器是如何工作的。
在 SQL Server 数据库引擎的核心是两个主要部分组成:存储引擎和查询处理器(也被称为 关系引擎)。存储引擎负责在磁盘和内存之间以最优化的方式读取数据,同时维护数据的完整性。 查询处理器,顾名思义,接受提交给 SQL Server 所有的查询,并且为产生他们的最佳执行计划, 然后执行该计划,并提供所需的结果。
我们将查询以 T-SQL 的形式提交给 SQL Server。因为 SQL 语句是一个高层抽象的声明性的 语言,它仅仅只是定义了要从数据库中获取什么样的数据,而没有告诉如何去获取这些数据(或 者说,没有定义获取数据的方法和步骤)。所以,对于 SQL Server 所接受到的每一个查询,查询 处理器的首要任务就是产生一个计划,这个计划就描述了如何去执行查询,之后就由存储引擎去 执行这个计划了。
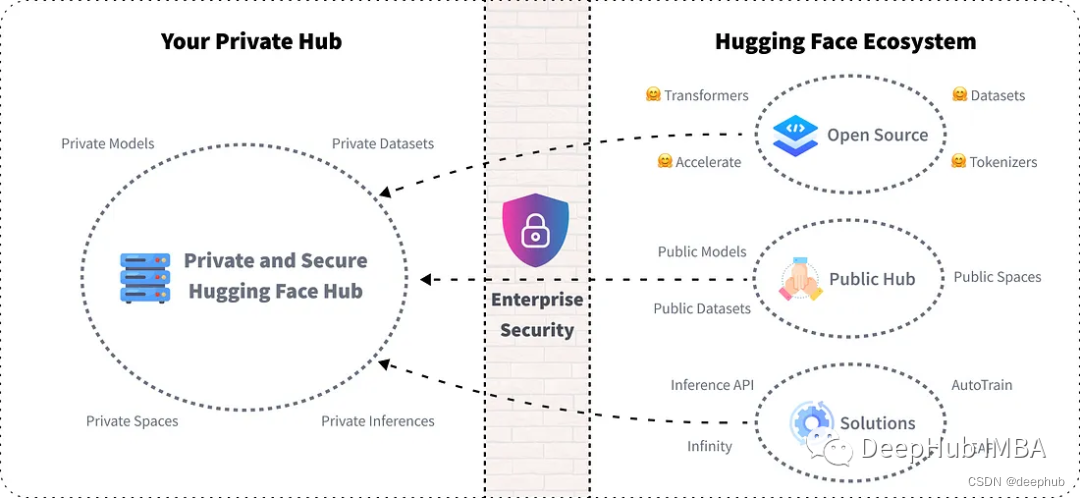
为了确保已经达到在查询处理器认为是最好的计划执行查询,查询处理器执行不同的步骤, 整个查询处理过程如图所示:

当然,上面的图只是一个最简单的示例图,下面,给大家看另外一个图,体会一下一个查 询处理的过程:

我们在后续的文章中会看到每一个步骤的详细讲解与应用,下面我们就简单的介绍 图中的一些步骤(为了简单起见,我们以第一幅图为例子)
1. Parsing 和 Binding(解析与绑定):在一个查询提交给了数据库之后,首先就要被进行 语法的解析,如果这个查询的语法是没有问题的,那么这个 Parsing 过程的输入结果就 是一个逻辑树,在这个逻辑树种每一个节点都表示了这个查询进行的每个操作,例如 读取某个表,进行 inner join 等。
下面,给大家看一个逻辑树的例子,对于下面的查询:
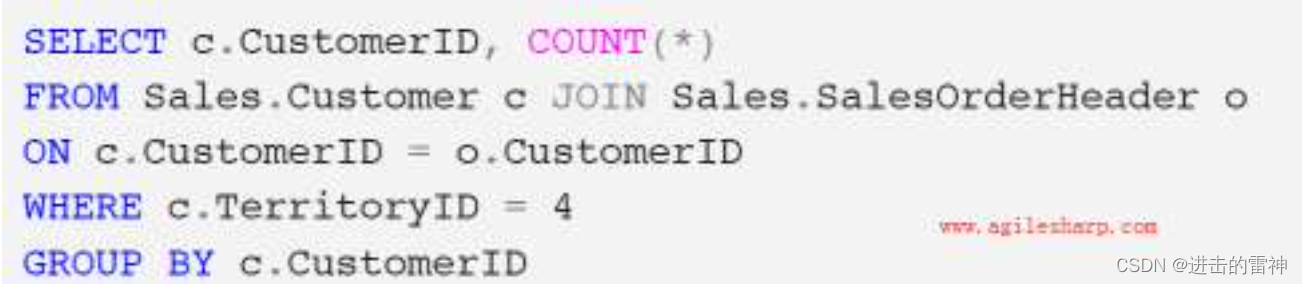
产生的逻辑树如下:
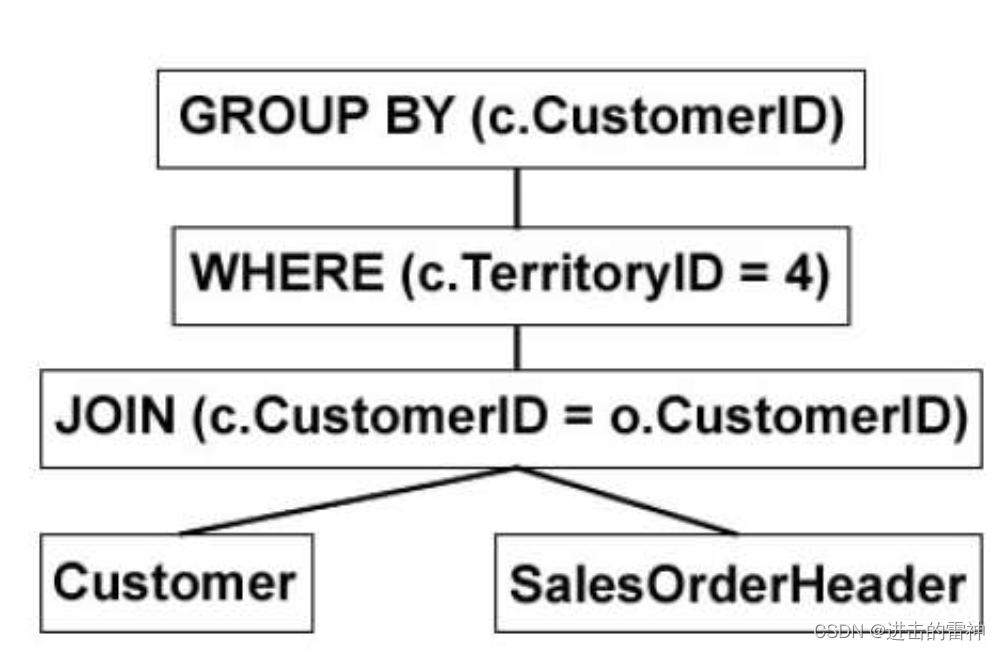
这个过程就是编译原理的一个文法词法的解析。
谈完了 Parsing,之后的操作就是 Binding 了,这个操作现在改名字为 Algebrizer。这个操作 主要就是检查解析产生的逻辑树中的对象是否存在,例如 Customer 是否是数据库中的表, CustomerID 字段是否在 Customer 表中等。
经过了这个 Binding 之后,就会产生另外一个树形的数据结构,传递给下一个步骤。
2. 查询优化。这个过程主要是使用上述过程中的AlgebrizerTree进行优化的处理过程, 我们这里大体的可以将这个优化的处理过程分为两个步骤:
-
产生执行计划。在这个过程中,查询优化器会使用之前的树,产生执行计划。 这个过程主要是将树上的逻辑操作转换为物理操作(其实就是存储引擎可以调 用的方法,这些方法就是实实在在的去读取数据的)。
-
估算每个执行计划的成本。一个逻辑操作可以有很多的物理操作与其对应,而 每个物理操作的成本不一样,同时,也没用所谓的“什么物理操作比其他的物 理操作更优” ,一切视情况可认定。在这个过程中产生很多的候选执行计划, 并且查询优化器会综合考虑很多的情况,选择一个它认为“比较优”的计划, 传递给存储引擎。
-
查询的执行与计划的缓存。这个过程比较简单了,主要是存储引擎去执行执行计划, 同时为了避免相类似的 SQL 查询重新编译,使用过的执行计划会被缓存在计划缓存池 中。
基本是,我们可以看出,查询优化的过程就是一个将逻辑操作映射为物理操作的过程。 我们在下一篇中稍微深入的看看候选执行计划的产生以及估算它们的成本!